📝 LLMs-from-scratch: учебник, который помогает собрать GPT-подобную LLM на чистом PyTorch с пониманием внутри
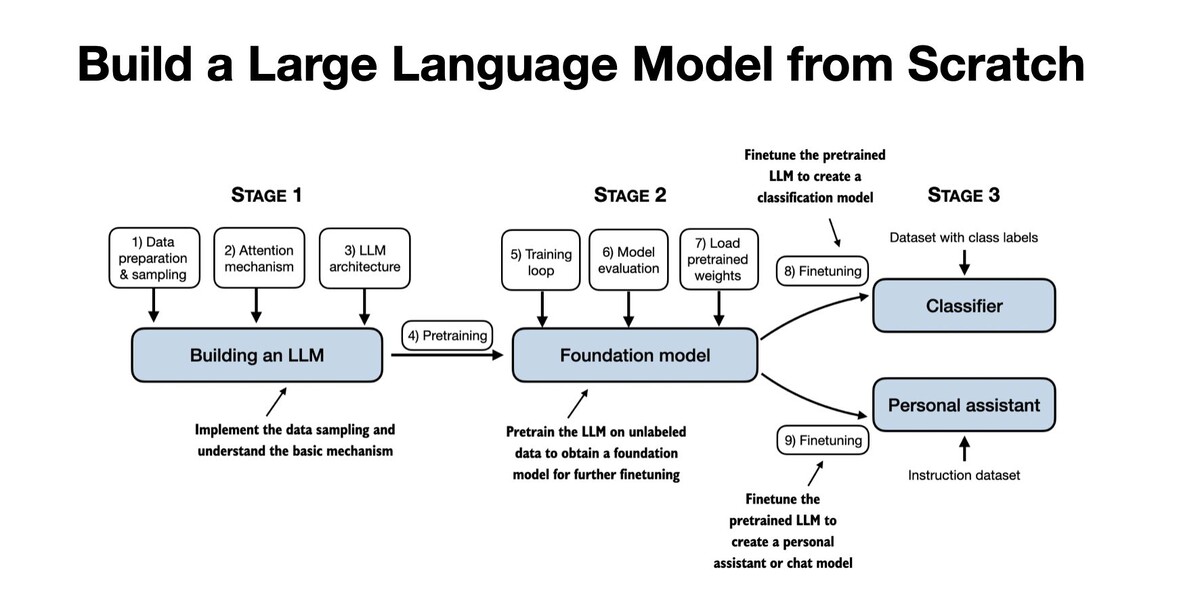
LLMs-from-scratch — репозиторий к книге Себастьяна Рашки, где GPT-подобную LLM собирают шаг за шагом на чистом PyTorch, без “скопируй и запусти”.
Весь путь от данных до поведения ассистента: сначала токенизация и Dataset/Dataloader с перекрывающимися окнами, потом вручную реализуют Multi-Head Attention (softmax, causal masking и сборка голов), затем собирают GPT-движок из embedding’ов, трансформер-блоков и head’а.
Самое редкое в подобных курсах — что attention и маскирование пишут руками: большинство тут останавливается на высокоуровневых импортов вроде nn.MultiheadAttention или ограничивается поясняющими слайдами.
Есть и “современный” блок: в приложениях показаны версии архитектур — например, Llama 3 с контекстом до 131,072 токенов и отличиями вроде SwiGLU и RMSNorm; для Qwen 3 отдельно отмечены qk_norm и разные контекстные/размерные конфиги (0.6B–32B).
Полезно попробовать на собственных задачах: в репозитории есть LoRA (Low-Rank Adaptation) для параметро-экономичного дообучения и улучшения training loop (warmup, cosine decay, gradient clipping). Начните с главы 2 (токенизация и Dataset): там короткий участок кода, после которого появляется первый работающий пайплайн. 95k звёзд — для образовательного проекта это редкость, явно ставят не только студенты.
#tool #PyTorch #LoRA #nlp #GitHub #transformers #Llama3 #Qwen3