Совсем недавно я услышал одно из интервью всем известной Наталья Каспирская.
Там было много чего сказано, но больше всего меня заинтересовала информация по нейросетям.
В силу того, что я немного представляю себе, что это такое, то решил поинтересоваться, а сколько же это удовольствие стоит?
Но сначала напомню про всем известную Кривую Хайпа Гартнера.
Модель Gartner Hype Cycle описывает пять стадий зрелости технологии:
1. Технологический триггер — появление прорывной инновации
2. Пик завышенных ожиданий — эйфория рынка, игнорирование рисков
3. Спад разочарования — осознание ограничений, коррекция оценок
4. Склон просвещения — прагматичное внедрение, поиск рабочих моделей
5. Плато продуктивности — устойчивая ценность, массовая адаптация
Задавшись вопросом, где находится генеративный ИИ сегодня, можем смело ответить следующее.
"На основании анализа рыночных сигналов, финансовых показателей и экспертных оценок, сектор генеративного ИИ в 2026 году находится на стыке «Пика завышенных ожиданий» и начала «Спада разочарования»."
Откуда мы можем сделать вывод, что совсем скоро нас ожидает пиковое падение раскручивающихся сегодня нейросетей. Ну и конечно большой-большой бум-бум!
Почему? Давайте разбираться.
Для начала разберём откуда появилась цитата, высказанная выше.
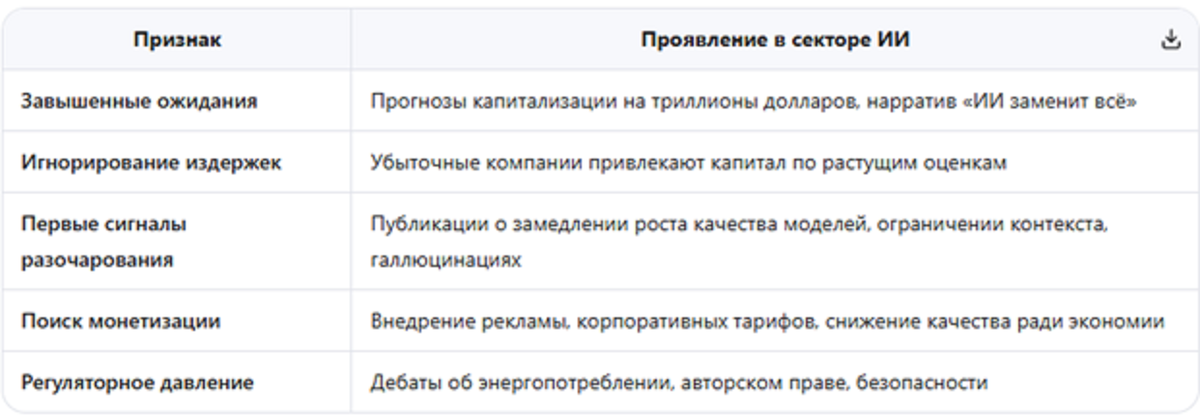
Таблица 1.
Как видим уже есть причины для "беспокойства".
Технология не «провалилась», но проходит необходимую фазу коррекции ожиданий. Инвесторам важно различать долгосрочный потенциал ИИ и краткосрочную спекулятивную переоценку.
Но продолжим.
Сектор генеративного искусственного интеллекта остаётся главным драйвером рыночных ожиданий, привлекая рекордные объёмы венчурного и публичного капитала. Ну или по простому, с лохов собирают деньгу под сладкие обещания.
Однако за фасадами презентаций с прогнозами капитализации на триллионы долларов скрывается фундаментальная проблема:
- текущая бизнес-модель разработки и развёртывания ИИ демонстрирует структурное расхождение между затратами и доходами.
На основе анализа открытых данных, отраслевых отчётов и экспертных оценок можно систематизировав экономические параметры генеративного ИИ, выявявить признаки переоценённости рынка.
Такое выдают различные обзоры.
О чём это?
Я не экономист, но благодаря возможности ускоренного поиска и анализа тех же нейросетей можно сказать следующее.
1. Исторические параллели: симптомы «пузыря»
Сравнение текущего ИИ-бума с дотком-пузырём 2000 года не является риторическим приёмом. Наблюдаются повторяющиеся макроэкономические паттерны:
- Отрыв оценки от денежных потоков: компании оцениваются по потенциальному влиянию на рынок, а не по текущей прибыльности или свободному денежному потоку.
- Концентрация капитализации: узкий пул акций формирует основную часть прироста индексов, что исторически предшествует коррекциям.
- Нарратив вместо юнит-экономики: аргументация строится на «революционности технологии», тогда как базовые показатели (маржинальность, срок окупаемости, стоимость привлечения клиента) игнорируются.
Но технологический прогресс не отменяет законов корпоративных финансов. Инновация становится инвестиционно зрелой только тогда, когда её масштабирование снижает предельную издержку, а не увеличивает её.
2. Юнит-экономика и парадокс масштабирования
В отличие от традиционного ПО, где предельная стоимость обслуживания нового пользователя стремится к нулю, генеративные модели обладают положительной предельной стоимостью инференса.
Каждый запрос требует вычислительных ресурсов, памяти и энергии.
Для примера:
- OpenAI (2024): выручка ~$12 млрд, операционные расходы ~$28 млрд. Чистый убыток превышает $16 млрд.
- Прогноз к 2030 г.: планируемые капитальные и операционные затраты оцениваются в $600 млрд при ожидаемой выручке $280 млрд. Расходы растут вдвое быстрее доходов.
- Масштабирование = убыточность: увеличение числа пользователей напрямую требует закупки серверов, расширения дата-центров и роста счетов за электроэнергию. Кривые затрат и доходов продолжают расходиться.
Данный парадокс указывает на то, что текущая монетизация (подписки, корпоративные лицензии, API-доступ) не покрывает инфраструктурную базу, необходимую для поддержки заявленных объёмов трафика.
3. Инфраструктура и энергия: скрытый мультипликатор затрат
Физические ограничения ИИ-индустрии становятся главным финансовым риском:
Таблица 2.
Трёхлетний жизненный цикл аппаратного обеспечения означает, что компании вынуждены непрерывно реинвестировать в инфраструктуру, не успевая достичь точки безубыточности.
При текущих тарифах на электроэнергию и дефиците мощностей в ряде регионов, себестоимость одного запроса останется структурно высокой.
4. Проблемы монетизации и компромиссы качества
В условиях растущих издержек разработчики ИИ вынуждены искать альтернативные источники дохода:
- Внедрение рекламы: интеграция рекламных моделей в генеративные интерфейсы снижает маржинальность корпоративных клиентов и ухудшает пользовательский опыт.
- Снижение качества ради экономии: оптимизация моделей под бюджет часто приводит к уменьшению точности, увеличению галлюцинаций или ограничению длины контекста.
- Ограниченность роста качества: отраслевые отчёты фиксируют замедление прироста производительности моделей относительно затрат на обучение (закон убывающей отдачи от масштабирования параметров).
Эти факторы формируют «треугольник компромиссов»: качество, себестоимость и монетизация не могут быть оптимизированы одновременно в текущей технологической парадигме.
Закономерный вывод
Генеративный ИИ обладает трансформационным потенциалом, однако его текущая экономическая модель находится в стадии структурной перестройки.
Расхождение между ожиданиями «светлого будущего» и финансовой реальностью создаёт условия для рыночного перехода от высокой изменчивости к постепенной стабилизации сектра. (волатильности и консолидации)
Устойчивая прибыльность станет возможной только при сочетании трёх факторов:
- - снижения стоимости вычислений (новые архитектуры, специализированные чипы, эффективные модели),
- - оптимизации энергопотребления и
- - доказательства реальной отдачи для корпоративных клиентов.
Я думаю так на это посмотрят какие-нибудь финансисты.
---
А что же скажет на это технари, которые зарабатывают на этом технологическом "чуде" денежки не хотят покидать это насиженное местечко?
Инженерная реальность: что видит разработчик за цифрами отчётов
Человек, который непосредственно проектирует, обучает и разворачивает нейросетевые модели, переведёт "сухие" цифры финансовой аналитики на язык технических решений и ограничений, наверно примерно таким способом.
1. Проблема масштабирования — это не баг, это архитектурное ограничение
К сожалению, «Улучшение моделей удаляет разработчиков от прибыльности»
С инженерной точки зрения это звучит так: каждое улучшение качества модели требует экспоненциально больше ресурсов.
Таблица 3.
Как видно из таблицы, всё упирается не в «нехватку денег», а в фундаментальные ограничения архитектуры трансформеров и физических законов (память, пропускная способность, энергопотребление).
Без смены парадигмы (новые архитектуры, алгоритмы, чипы) масштабирование будет только ухудшать unit economics(метод анализа прибыльности бизнеса, рассчитывающий доходы и расходы на одну базовую единицу (юнит): клиента, сделку или товар).
2. Энергопотребление — это не операционные расходы, это инженерный вызов
Ещё бы: «Один запрос — 0,047 кВт·ч. Умножьте на 800 млн запросов в неделю»!
Для инженера это означает:
- Тепловыделение: сервер DGX H100 (10 кВт) требует жидкостного охлаждения, стандартные ЦОДы не справляются.
- Латентность: оптимизация под энергоэффективность часто конфликтует с требованием low-latency(минимальное время, необходимое для передачи, обработки и получения данных в цифровых системах) инференса.
- Балансировка: распределение нагрузки между регионами с дешёвой энергией vs. требования GDPR и задержки сети.
Что делается для решеня этой проблемы:
- - Квантование моделей (INT8, FP4) — снижение точности ради экономии памяти и энергии.
- - Distillation — «сжатие» больших моделей в меньшие с сохранением качества.
- - Speculative decoding, caching, batching — инженерные хаки для снижения стоимости инференса.
- - Миграция инференса на специализированные чипы (TPU, NPU, LPU) вместо универсальных GPU.
Но Проблема: Эти оптимизации дают линейный выигрыш, а рост трафика — экспоненциальный. Разрыв сохраняется.
3. «Срок службы 3 года» — это технический долг в чистом виде
«Их реальный срок службы около 3 лет. Через 3 года на помойку»
С точки зрения DevOps и MLOps:
- Hardware obsolescence: новые модели требуют больше памяти и вычислительной мощности -> старое железо не тянет инференс новых версий.
- Software stack drift: фреймворки, драйверы, CUDA-версии меняются быстрее, чем амортизируется оборудование.
- Model versioning: поддержка нескольких версий моделей для разных клиентов умножает инфраструктурные затраты.
Отсюда получается: Строится система с заведомо коротким жизненным циклом. Это требует:
- - Автоматизации развёртывания (Infrastructure as Code)
- - Модульной архитектуры, позволяющей заменять компоненты без полного редизайна
- - Чёткого планирования миграции между поколениями железа
4. Качество vs. Себестоимость: инженерный треугольник компромиссов
В результате «Компании вынужденно снижают качество и пытаются найти новые модели сбыта»
Для разработчика это классический треугольник: быстро / дёшево / качественно — выберите два.
Таблица 4.
Реальность такова: Пользователи хотят всё три одновременно. Инженеры вынуждены искать баланс через:
- - A/B-тестирование разных версий моделей
- - Динамический выбор модели под задачу (routing: маленькая модель для простых запросов, большая — для сложных)
- - Прозрачную коммуникацию с продуктом о допустимых компромиссах
5. Что реально может изменить ситуацию: технические направления
Не все новости плохие. Вот где инженеры видят потенциал для прорыва:
Новые архитектуры: Mixture of Experts (MoE), state space models (Mamba), рекуррентные трансформеры — обещают лучшее соотношение качество/вычисления.
Специализированные чипы: TPU v5, Groq LPU, Cerebras — оптимизированы под инференс, а не обучение.
Локальный инференс: запуск компактных моделей на устройстве пользователя снижает нагрузку на ЦОДы и задержки.
Энергоэффективные алгоритмы: sparse attention, активация по запросу, early exiting — вычисления только там, где нужно.
Синтетические данные и самообучение: снижение зависимости от дорогой человеческой разметки.
Вот только: эти технологии находятся на разных стадиях зрелости. Массовое внедрение — вопрос 2–5 лет, а не месяцев.
Итоговый вывод для разработчика
Генеративный ИИ сегодня — это инженерно сложный, ресурсоёмкий продукт с положительной предельной стоимостью каждого запроса. Разработчики не строят «программное обеспечение» в классическом смысле — строят инфраструктуру, которая потребляет физические ресурсы в реальном времени.
Отсюда финал: Технологический прогресс не отменяет физику и экономику. Но именно инженеры, работающие на стыке алгоритмов, железа и инфраструктуры, могут найти путь к устойчивой архитектуре — не через «хайп», а через последовательную оптимизацию, инновации и честную оценку компромиссов.
Таков возможный вывод разработчику.
Ну и напоследок, а нам то что от этого? Мне простому обывателю, что с того?
Если отбросить миллиарды долларов, серверные стойки и графики хайпа — что всё это значит для вас и меня? Для человека, который не инвестирует в стартапы, не строит дата-центры и не пишет код, а просто живёт, работает и пользуется телефоном?
Давайте по-простому.
Таблица 5.
Проще говоря: ИИ уже работает как «невидимый помощник» — ускоряет рутину, подсказывает, экономит время.
Но есть и обратная сторона
1. «Бесплатно» — не значит бесплатно
«Вы не платите деньгами — вы платите вниманием, данными, временем»
- - Реклама в ответах ИИ -> вы смотрите, компания зарабатывает
- - Сбор данных о ваших запросах -> профиль для таргета
- - Подписка за «премиум-качество» -> базовая версия ухудшается
2. Качество может падать
«Когда компания экономит — страдает пользователь»
- - Модель отвечает короче, чтобы сэкономить токены
- - Ответы становятся шаблонными, чтобы снизить нагрузку
- - Ошибки и «галлюцинации» остаются, потому что проверка стоит денег
3. Зависимость от «коробки»
«Если сервис отключат — вы остаетесь без привычного помощника»
- - Локальные альтернативы слабее
- - Навыки «делать самому» атрофируются
- - Резкий рост цен на подписку = шок для бюджета
Так стоит ли пользоваться?
Да, если:
- - Вы используете ИИ как инструмент, а не как замену мышлению
- - Понимаете, что бесплатный тариф — это компромисс
- - Проверяете важные ответы (особенно в работе, здоровье, финансах)
- - Не храните в чатах конфиденциальную информацию
Нет, если:
- - Вы верите каждому слову модели без проверки
- - Ожидаете, что ИИ решит все проблемы «сам собой»
- - Готовы платить за подписку, не оценив реальную пользу
- - Боитесь, что «все пользуются — и мне надо», без понимания зачем
---
Практические советы для обывателя
1. Начните с малого: попробуйте ИИ для одной конкретной задачи (составить письмо, объяснить сложную тему, перевести текст). Оцените, экономит ли это время.
2. Сравнивайте: один и тот же запрос — в разных моделях. Где ответ точнее? Где понятнее? Где быстрее?
3. Не доверяйте слепо: ИИ может ошибаться уверенно. Проверяйте факты, цифры, цитаты.
4. Защищайте приватность: не пишите в чат паспортные данные, пароли, медицинские диагнозы, коммерческие тайны.
5. Считайте деньги: если сервис просит подписку — посчитайте, сколько часов в месяц он реально экономит. Стоит ли это 500/1000/5000 рублей?
6. Оставляйте «ручной режим»: учитесь делать важное без ИИ. Навык — это страховка на случай, если сервис изменится, подорожает или исчезнет.
---
А что с «пузырём»? Мне-то что?
Если ИИ-пузырь «лопнет» — для обычного пользователя это может означать:
- Коррекция рынка - Исчезнут некоторые бесплатные сервисы, останутся крупные игроки
- Рост цен - Подписки подорожают, бесплатные тарифы станут ещё ограниченнее
- Консолидация - Меньше выбора, но, возможно, более стабильные продукты
- Смена фокуса - Компании перейдут от «вау-эффектов» к реально полезным функциям
Хорошая новость: даже если хайп спадёт, технологии останутся. Как после 2000 года остался интернет — просто стали работать те, кто предлагал реальную ценность.
---
Главный вывод для обычного человека
Искусственный интеллект (нейросеть) — это не магия и не угроза. Это инструмент. Как молоток: можно построить дом, а можно ударить по пальцу. Всё зависит от того, как и зачем вы его используете.
Не гонитесь за «новинкой» ради новизны.
Не бойтесь технологии из-за страшных заголовков.
Спрашивайте себя: «Это реально облегчает мне жизнь — или просто модно?»
Если ответ «да» — пользуйтесь с умом.
Если «нет» — не тратьте время, деньги и нервы.
---
Ну и в завершение:
Технологии меняются. Хайп приходит и уходит.
А ваша способность думать, выбирать и контролировать — остаётся с вами.
Это и есть главный «апгрейд», который никто не отнимет.
И напоследок из практики, своей собственной.
- Что-то искать по быстрому, анализировать, посчитать, если это известные факты, рутинная работа, типа проверки ошибок - отлично нейронка справляется.
- Но ни в коем случае не предоставлять ей "право" творческой "деятельности". И дело не в каком то "страхе", а просто она это не умеет делать.
- Она каждый раз заканчивает предложениями, которые заложены в её памяти, выводы делает из тех выводов, которые также заложены, по вероятностной программе.
- А в литературе даже не может отличить двух персонажей друг от друга.
- Я понимаю, что нейросети будут развиваться. Но уже не так быстро, как хотелось бы и выводы выше уже были представлены.
Так что ни завоевания мира машинами или замены человека полностью даже в далёком будущем не предвидится.
Только рутинная работа, да и то тольок та, которая подвержена алгоритмизации.
Вот как-то так.
А вы как считаете?
---------------------------------------------------------------------------------
Источники и подтверждающие материалы
1. Первичный текст анализа: Касперская Н. «Недавно менеджер из банка предложила мне купить акции…». Telegram-канал, 2025–2026 гг. [Транскрипт предоставлен пользователем].
2. Финансовые показатели OpenAI:
- LessWrong. *OpenAI lost $5 billion in 2024 and its losses are accelerating*. URL: https://www.lesswrong.com/posts/CCQsQnCMWhJcCFY9x/openai-lost-usd5-billion-in-2024-and-its-losses-are
- Asia Times. *OpenAI is burning billions and an IPO won't stave off bankruptcy*. Апрель 2026. URL: https://asiatimes.com/2026/04/openai-is-burning-billions-and-an-ipo-wont-stave-off-bankruptcy/
3. Заявления IBM и оценка инфраструктуры:
- DIGITIMES. *IBM CEO: AGI cost and data center hardware economics*. Декабрь 2025. URL: https://www.digitimes.com/news/a20251208PD211/ibm-agi-cost-data-center-hardware.html
- DataCenterDynamics. *IBM's CEO says there's no way for gigawatt data centers to turn a profit*. URL: https://www.datacenterdynamics.com/en/news/ibms-ceo-says-theres-no-way-for-gigawatt-data-centers-to-turn-a-profit/
4. Энергопотребление ИИ:
- The Verge. *How much electricity does AI consume?*. 2024–2025. URL: https://www.theverge.com/24066646/ai-electricity-energy-watts-generative-consumption
- ACM Digital Library. *Power Hungry Processing: Watts vs. Work in AI*. Carnegie Mellon University & Hugging Face. URL: https://dl.acm.org/doi/fullHtml/10.1145/3630106.3658542
- DataCenterDynamics. *AI data centers could use more electricity than the Netherlands by 2027*. URL: https://www.datacenterdynamics.com/en/news/ai-data-centers-could-use-more-electricity-than-the-netherlands-by-2027/
5. Сравнение с дотком-пузырём 2000 г.:
- Investing.com. *The Dot-AI Bubble: Why 2026 feels like 2000 all over again*. URL: https://www.investing.com/analysis/the-dotai-bubble-why-2026-feels-like-2000-all-over-again-200668624
- The Conversation. *The AI boom feels eerily similar to 2000s dotcom crash*. URL: https://theconversation.com/the-ai-boom-feels-eerily-similar-to-2000s-dotcom-crash-with-some-important-differences-269472
6. Аналитика по экономике инфраструктуры ИИ:
- Epoch AI. *OpenAI Revenue Growth & Financial Trajectory*. URL: https://epoch.ai/data-insights/openai-revenue
- The Diligence Stack. *AI Infrastructure Economics: The Capex Problem*. URL: https://thediligencestack.com/p/ai-infrastructure-economics-the-2