Авторы Programbench протестировали GPT-5.5 и Claude Opus 4.7 на уровнях high/xhigh (максимальная длина рассуждений и время работы). • GPT-5.5 xhigh значительно опередил Claude Opus 4.7 xhigh по всем показателям. • Впервые одна из моделей полностью решила задачу (из 200), оба запуска GPT-5.5 справились с ней на Python и C. • По задачам, где проходит 95% тестов, GPT-5.5 xhigh написал с нуля 13,5% программ, GPT-5.5 high — 5%, Opus 4.7 xhigh — 4,5%. «GPT-5.5 xhigh значительно превосходит Claude Opus 4.7 xhigh по всем параметрам» На графике видно, что GPT-5.5 xhigh закрывает больше функциональности в задачах по сравнению с другими моделями. https://dzen.ru/id/5c0e38ff46ef5c00aaa80527
GPT-5.5 показал лучшие результаты в бенчмарке Programbench
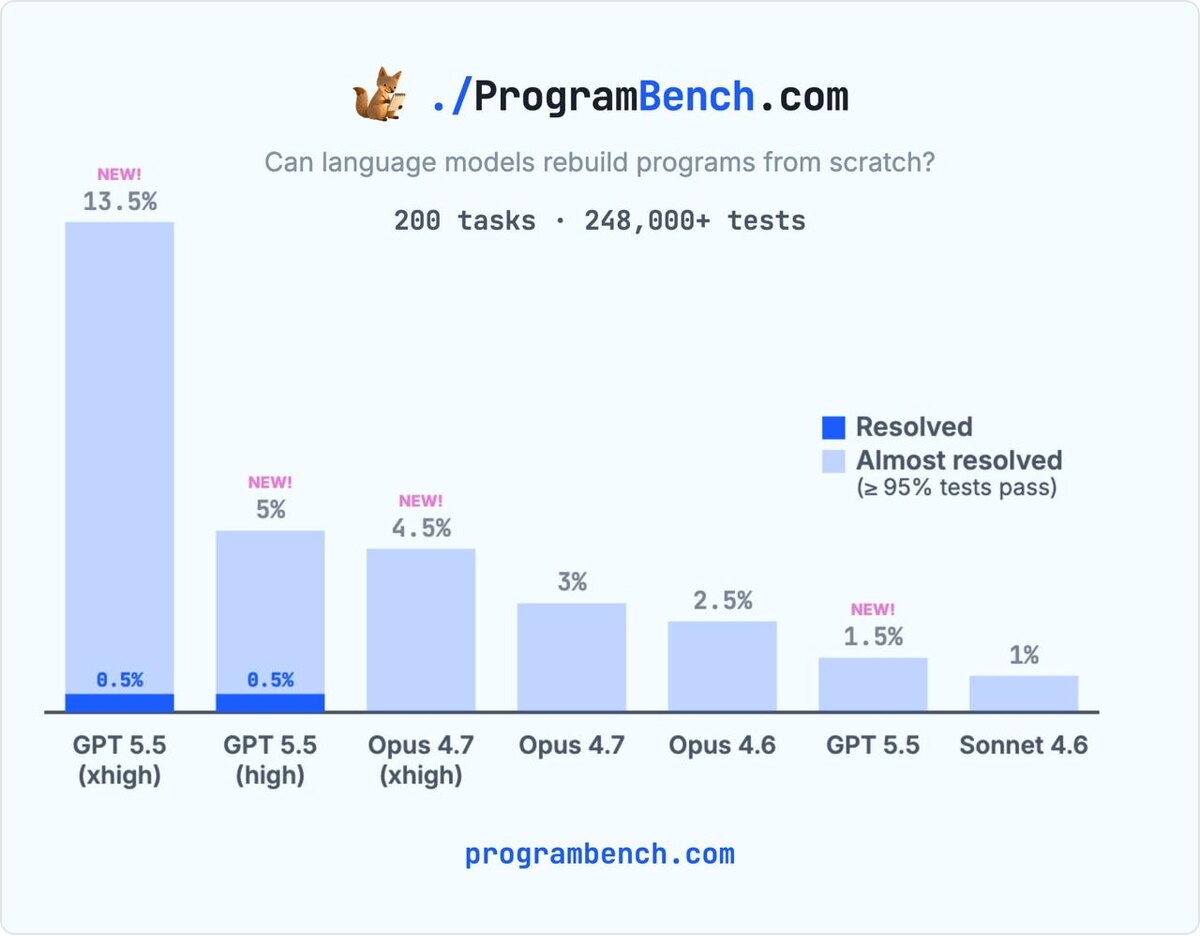
Авторы Programbench протестировали GPT-5.5 и Claude Opus 4.7 на уровнях high/xhigh (максимальная длина рассуждений и время работы).
• GPT-5.5 xhigh значительно опередил Claude Opus 4.7 xhigh по всем показателям.
• Впервые одна из моделей полностью решила задачу (из 200), оба запуска GPT-5.5 справились с ней на Python и C.
• По задачам, где проходит 95% тестов, GPT-5.5 xhigh написал с нуля 13,5% программ, GPT-5.5 high — 5%, Opus 4.7 xhigh — 4,5%.
«GPT-5.5 xhigh значительно превосходит Claude Opus 4.7 xhigh по всем параметрам»
На графике видно, что GPT-5.5 xhigh закрывает больше функциональности в задачах по сравнению с другими моделями.
https://dzen.ru/id/5c0e38ff46ef5c00aaa80527