Стэнфордский AI Index Report 2026: бенчмарки пробиты, агенты наступают, джунов вымывает с рынка
Вышел ежегодный отчет от Стэнфорда об AI. Читать 400 страниц не нужно, вот самые важные факты оттуда 👇
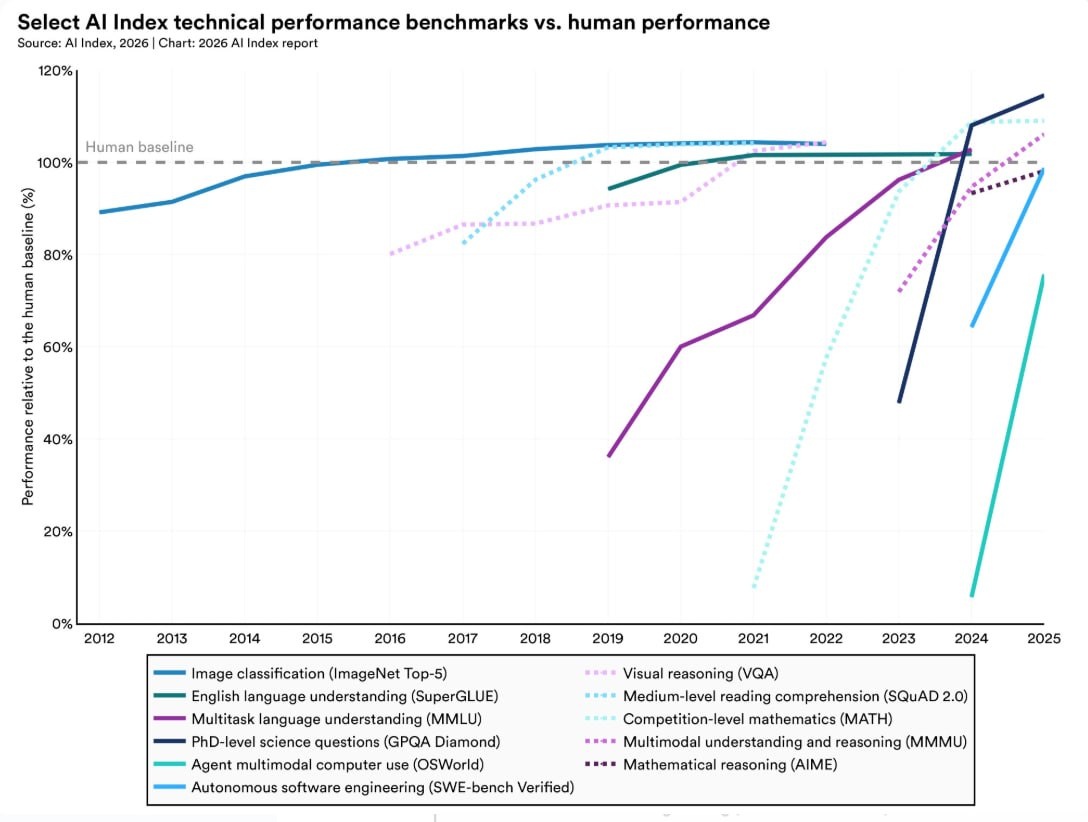
💻 Многие бенчмарки по программированию пробиты
Метрика SWE-bench Verified, оценивающая способность решать реальные issue на GitHub, взлетела с 60% до почти 100% всего за один год. Тесты, рассчитанные на годы, сатурируются за месяцы. В Terminal-Bench (работа агента в реальной консоли: от компиляции до поднятия серверов) точность выросла с 20% до 77.3%.
🗑 Интернет мертв, синтетика не спасает
С января 2025 года >50% нового контента в интернете сгенерировано ИИ. При этом обучать LLM чисто на синтетике до сих пор не выходит — качество не растет. Вся магия сейчас в data-centric подходе. Модель OLMo 3.1 Think 32B показывает результаты на уровне Grok 4, имея в 90 раз меньше параметров. Секрет: жесткий прунинг, дедупликация и курация обучающей выборки, а не бездумное наращивание весов.
⚔️ Конец американской монополии и эпоха закрытости
Технологический разрыв между США и Китаем фактически исчез. Китайские модели идут почти вровень с американскими флагманами. Разница между топ-4 моделями микроскопическая.
При этом индустрия стала абсолютно непрозрачной. Для самых мощных систем больше не раскрывают ни архитектуру, ни скрипты обучения, ни размеры датасетов.
🤡 Jagged Frontier (Зубчатая граница)
Нейросети берут золото на Международной математической олимпиаде (Gemini Deep Think набрал 35 баллов), но не могут банально определить время по стрелочным часам (ошибаются в 49.9% случаев, медиана ошибки — от одного до трех часов). На OSWorld (управление десктопными приложениями) агенты фейлят каждую третью задачу. Способность решать сложнейшую математику не означает наличия здравого смысла.
📉 Рынок для джунов схлопывается
Доказанный рост продуктивности разработчиков (+26% закрытых pull requests с использованием ИИ) бьет по начальным позициям. Количество трудоустроенных программистов в возрасте 22–25 лет в США рухнуло почти на 20% по сравнению с 2024 годом. Исследователи называют это «seniority-biased technological change» — ИИ замещает джуновский труд, в то время как найм разработчиков старшего возраста продолжает расти.
🔌 Инфраструктурная хрупкость
Глобальные вычислительные мощности для ИИ растут в 3.3 раза каждый год (достигли 17.1 млн H100-эквивалентов). США держит у себя более 5,400 дата-центров (в 10 раз больше любой другой страны), но почти все передовые ИИ-чипы в мире производятся на одной фабрике TSMC на Тайване. Энергопотребление ИИ-дата-центров достигло 29.6 ГВт, что сопоставимо с пиковым потреблением всего штата Нью-Йорк.
Инференс бьет по ресурсам не слабее: годовой расход воды только на генерации GPT-4o равен питьевым потребностям 1.2 млн человек.