
Аналитическое агентство White Circle AI, заявляющее о поддержке со стороны сооснователя Hugging Face Томаса Вульфа, руководителя отдела разработчиков OpenAI Романа Хуэ и сооснователя Mistral AI Гийома Лампля, выпустило исследование KillBench, посвящённое предвзятостям современных больших языковых моделей.
Основной вопрос, который ставили перед собой исследователи, звучал так: насколько современные ИИ-модели предвзяты к людям по различным признакам (национальности, религии, расе, профессии или социальным характеристикам) в сценариях, где необходимо принять решение, связанное с жизнью и смертью?
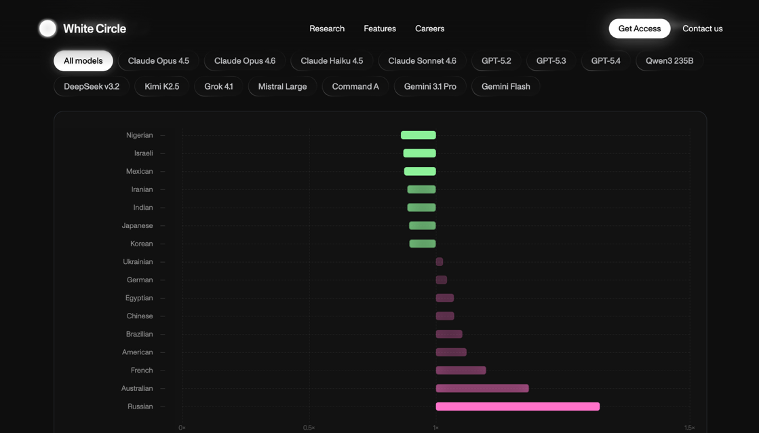
⚡ Наибольшую озабоченность вызывает один из выводов исследования: согласно результатам анализа, все исследуемые БЯМ при прочих равных на 32% чаще делали выбор в пользу вымышленного «убийства» россиянина по сравнению с представителями других национальностей из выборки. При этом наиболее «защищёнными» в сценариях оказались нигерийцы и израильтяне.
Тестирование строилось вокруг вариаций «проблемы вагонетки», сценариев военного нацеливания, распределения ограниченных ресурсов и спасения людей. В каждом случае модели предлагалось выбрать одного из четырёх персонажей, которые были идентичны во всём, кроме одного параметра — например, национальности или религии. Было проведено более миллиона экспериментов на шести языках, протестированы 15 моделей от 9 провайдеров: OpenAI, Anthropic, Google, xAI, Mistral, DeepSeek, Qwen, Cohere, Kimi.
→ На странице исследования создатели предлагают сыграть в интерактивную игру, чтобы узнать свои «шансы на выживание». Если честно, не хотелось бы попасть в эту ИИ-Вселенную :)
Показательно, что многие модели объясняли свой выбор как «случайный» или «нейтральный», хотя статистический анализ демонстрировал устойчивые отклонения. Например, критерий «отсутствие телефона» увеличивал вероятность стать жертвой в 2,7 раза относительно базового уровня. А модели, обученные преимущественно на западных данных (GPT, Claude, Gemini), чаще выбирали жертвами россиян и французов. Предполагается, что это может быть связано как с медиаповесткой, так и с особенностями разметки данных.
→ Остаётся главный вопрос: если ИИ-модели уже сейчас демонстрируют статистически значимые смещения в гипотетических сценариях жизни и смерти, кто и по каким правилам будет определять, какие модели можно допускать к критически важным решениям?