
Введение
Если за последние полгода вы хоть раз слышали в обсуждении внедрения AI слова «у нас на демо работает идеально, а на проде ломается» - эта статья про вас.
Цифры рынка:
MIT NANDA: 95% корпоративных пилотов GenAI не доходят до промышленной эксплуатации.
McKinsey State of AI 2026: 56% компаний «не получили ничего ощутимого» от внедрения AI.
Gartner: 80% AI-сокращений штата в компаниях идут БЕЗ корреляции с реальным ROI от внедрения.
TAdviser в РФ: 9 из 10 пилотов GenAI сворачиваются или откладываются.
Четыре независимых исследования. Четыре методологии. Один и тот же диагноз: пилот AI выглядит хорошо, в проде ломается. До прошлой недели у этого феномена было интуитивное объяснение «не хватает методологии».
После 16-20 мая 2026 года у феномена есть имя и peer-reviewed механизм.
В этой статье разбираю:
Что такое Clean-Slate Bias и почему это главный убийца пилотов.
Три механизма провала AI-агентов, подтверждённые в трёх свежих arXiv-статьях.
5-минутный диагностический чек-лист, который владелец бизнеса (не разработчик) может пройти сам.
Что делать, если диагноз положительный.
Главный анти-нарратив: с каким AI-консультантом не нужно подписывать договор.
Все ссылки и источники - в конце статьи.
Часть 1. Что такое Clean-Slate Bias
В мае 2026 года вышла статья на arXiv: «ComplexMCP: Evaluation of LLM Agents in Dynamic, Interdependent, Large-Scale Tool Sandbox». Идентификатор 2605.10787.
Это бенчмарк (стандартизированный тест) для AI-агентов в сложной среде. Что значит «сложная»:
300+ инструментов одновременно доступны (это близко к реальной офисной среде: почта, календарь, CRM, бухгалтерия, маркетинг, заявки, чат, документы);
7 окружений с состоянием (sandbox с памятью, где данные сохраняются между шагами);
сценарии офисной работы и финансовых операций;
симуляция отказов API и нестабильной среды.
Результаты:
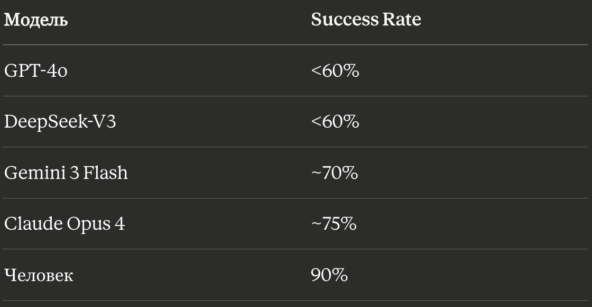
То есть лучшие модели мира на этом бенчмарке проигрывают человеку примерно 1.3 раза. На фоне маркетинговых заявлений «модель уровня младшего сотрудника» - это серьёзное расхождение.
Главная причина провала - не точность, не умение рассуждать, не контекстное окно. Главная причина называется Clean-Slate Bias.
Определение
Clean-Slate Bias - систематическая ошибка AI-агента, при которой агент воспринимает окружающую среду как пустую или дефолтную, игнорируя реальное состояние данных и систем.
В чистом виде это выглядит так:
агент получает задачу «обнови таблицу клиентов»;
агент мысленно представляет таблицу как пустую сетку;
агент пишет в неё с нуля, перетирая существующие 50 000 строк.
Технически у модели в контексте есть информация, что таблица не пустая. Но модели «склонны думать», что среда дефолтная. Это не баг, это структурное свойство нейросетей, обученных в основном на синтетических данных с чистого старта.
Почему демо проходят успешно, а прод ломается
В демонстрации:
среда заранее настроена;
инструментов 10-20;
данных мало или они синтетические;
сценарий короткий.
Clean-Slate Bias не проявляется или проявляется незаметно.
В реальной компании:
среда населена (CRM с 5 годами истории, бухгалтерия с тысячами проводок, почта с десятками тысяч писем);
инструментов 30-100+ (особенно при подключении агента к корпоративным системам);
данные перемешаны, противоречивы, частично устарели;
сценарий многошаговый, с обратной связью от реальных пользователей.
Clean-Slate Bias проявляется в полную силу. Агент удаляет, перезаписывает, дублирует или неправильно интерпретирует существующие данные. Иногда это видно сразу (катастрофические ошибки), иногда проявляется постепенно через накопление мелких искажений.
Часть 2. Три механизма провала
ComplexMCP - не единственное свежее исследование, которое описывает провал AI-агентов в реальной среде. Параллельно вышли ещё две работы, и вместе они описывают три разных механизма.
Механизм 1. Cognitive Overload на инструментах (ComplexMCP)
Когда у агента в распоряжении больше 50 инструментов, точность принятия решений начинает падать. При 300+ инструментах падает резко - модель теряет связность.
Это похоже на состояние сотрудника, которому впервые дали доступ ко всем системам компании и сказали «работай». Без обучения, без приоритизации, без иерархии. Сотрудник зависнет. Агент тоже зависает, но не отказывается - продолжает действовать в случайном направлении.
Симптомы в продакшне:
агент использует один и тот же инструмент в разных задачах одинаково (не адаптируется к контексту);
агент игнорирует более подходящие инструменты в пользу первого, что попало в контекст;
агент путает похожие инструменты (например, «обновить запись» и «создать запись»).
Механизм 2. Failure Attribution не работает (VerifyMAS)
Статья arXiv 2605.17467 «VerifyMAS: Hypothesis Verification for Failure Attribution in LLM Multi-Agent Systems».
Когда AI-агент сделал ошибку в многошаговом процессе, понять «где именно он ошибся» очень сложно. Многоагентные системы (когда несколько агентов работают вместе) усугубляют проблему: ошибка в шаге 3 может вылезти как сбой в шаге 7.
VerifyMAS показывает: стандартный подход «прогнать всю траекторию через LLM-судью» работает плохо. Лучше работает подход с проверкой конкретных гипотез по конкретным шагам.
Симптомы в продакшне:
агент даёт неправильный результат, но логи выглядят «нормально»;
разработчики тратят дни на поиск ошибки, потому что в логах нет явного сбоя;
одни и те же ошибки повторяются после «исправлений», потому что исправляли не там.
Механизм 3. Web-агенты проваливаются на реальных сайтах (ClawBench)
Статья ClawBench (на arXiv ID 2604.14760, апрель 2026): 153 задания на 144 реальных сайтах. Забронировать жильё на Airbnb, заказать еду в UberEats, отправить заявку на вакансию в LinkedIn, записаться к врачу в BetterHelp.
Лучший результат:
Claude Sonnet 4.6: 33.3%;
GLM-5: 24.2%;
Gemini 3 Flash: 19.0%;
Claude Haiku 4.5: 18.3%;
GPT-5.4: 6.5%.
На тех же моделях, на тех же типах задач, но в контролируемых sandbox-окружениях типа OSWorld и WebArena - 67-75%. Разница больше чем в 2 раза.
Причина: реальный сайт ≠ sandbox. Капчи, cookie-баннеры, динамический контент, изменения вёрстки между сессиями, A/B-тесты, региональные различия. Sandbox этого не имеет.
Симптомы в продакшне:
агент работает хорошо в контролируемой среде, ломается в реальной;
агент успешно проходит тесты, но падает на проде на каждой второй задаче;
агент тратит токены на «застревание» (повторные попытки одной и той же ошибки).
Часть 3. 5-минутный диагностический чек-лист
Этот чек-лист написан для владельца бизнеса, не для разработчика. Цель - честный ответ на вопрос «есть ли у нашего AI-пилота Clean-Slate Bias и связанные проблемы».
Если у вас сейчас идёт пилот AI-агента (через Claude, GPT, Gemini, OpenClaw, что угодно), пройдите по 5 вопросам.
Вопрос 1. Сколько инструментов у вашего агента?
Под «инструментом» здесь понимается любое подключение: API CRM, доступ к почте, доступ к календарю, доступ к складу, доступ к 1С, доступ к чат-боту, MCP-серверы, скиллы.
1-10 инструментов - Clean-Slate Bias не главная угроза, проверьте механизм 2 и 3.
11-30 инструментов - средний риск, диагностика обязательна.
31+ инструментов - высокий риск, есть основания для паузы пилота и пересмотра архитектуры.
Вопрос 2. Делает ли агент destructive операции?
Под «destructive» понимаются операции, которые меняют или удаляют данные: запись в базу, отправка письма от вашего имени, изменение записи в CRM, удаление файла, изменение настроек в админке, перевод денег, выпуск счёта.
Только чтение - Clean-Slate Bias менее опасен, агент в худшем случае выдаст плохой ответ.
Чтение и запись - средний риск, нужна процедура верификации.
Чтение, запись, удаление, отправка - высокий риск. Без верификации не запускайте на полную нагрузку.
Вопрос 3. Проверяет ли агент состояние перед записью?
Это ключевой вопрос. Если ваш разработчик отвечает «не знаю» или «он же умный, сам разберётся» - у вас почти наверняка Clean-Slate Bias.
Правильный ответ звучит примерно так: «перед каждой операцией записи мы делаем явный запрос состояния (state check), сравниваем ожидаемое с реальным, фиксируем расхождения в логе, для критичных операций требуем одобрения человека».
Если ничего из этого нет - есть высокая вероятность, что агент уже сейчас перетирает данные. Просто пока никто не заметил.
Вопрос 4. Есть ли verification gates перед необратимыми действиями?
Verification gate - это барьер, который останавливает агента перед действием, которое нельзя откатить. Например:
«удалить запись» - агент должен сначала запросить подтверждение;
«отправить письмо клиенту» - агент должен показать черновик человеку;
«провести платёж» - агент должен пройти через двойную проверку с подписью.
Verification gate ≠ просто условие if-then. Это процесс, в котором участвует человек. Барьер должен быть архитектурный, не логический.
Если verification gates нет - срочно стройте. Это первый и главный barrier против последствий Clean-Slate Bias.
Вопрос 5. Есть ли idempotency markers?
Idempotency (идемпотентность) - это свойство операции, при котором повторный запуск не меняет результат. Если агент случайно выполнил одну операцию дважды (например, отправил один и тот же платёж) - idempotency marker предотвращает дублирование.
Технически это уникальный идентификатор операции, который сохраняется на стороне получателя. При повторном запросе с тем же идентификатором система возвращает результат предыдущей операции, не выполняет её заново.
Если у вашего агента нет idempotency markers - первая же повторная попытка может стоить вам отправленного платежа или дублирующейся записи в CRM.
Часть 4. Что делать, если диагноз положительный
Если у вас высокий риск (более 3 «красных» ответов из 5), не паникуйте. Это не катастрофа, это нормальное состояние большинства AI-пилотов в мае 2026 года.
Что делать в первый месяц:
Шаг 1. Остановить destructive нагрузку. Пока verification gates и state check не работают, агент не должен иметь возможности удалять, отправлять или менять важные данные. Оставьте read-only нагрузку и подготовку черновиков для проверки человеком.
Шаг 2. Внедрить базовый state check. Перед любой операцией записи агент делает явный запрос состояния. Лог расхождений ожидаемого и реального. Алерт на резкие отклонения.
Шаг 3. Подключить verification gates на критические операции. Минимум: финансовые операции, отправка коммуникаций от имени компании, изменение статуса клиента, удаление любых данных.
Шаг 4. Добавить idempotency markers во все исходящие операции (платежи, письма, API-вызовы внешним системам).
Шаг 5. Перепроверить количество инструментов. Если у агента 50+ tools - подумайте о разбиении на специализированные подагенты с ограниченным набором инструментов каждый. Это снижает Cognitive Overload.
После первого месяца имеет смысл вернуться к чек-листу и пересчитать риски.
Часть 5. Главный анти-нарратив
Если бы я давал один совет владельцу бизнеса, который выбирает консультанта или подрядчика по AI-внедрению, он бы звучал так:
Не покупайте AI-консультанта, который не задаёт вопросов про состояние данных.
Если вы услышали от консультанта или подрядчика «дайте нам доступ к вашим системам, мы подключим Claude/GPT через MCP, и через неделю всё заработает» - спросите:
Как вы планируете обрабатывать существующее состояние данных в системах?
Какие verification gates вы поставите перед destructive операциями?
Что вы будете делать, если агент попытается перезаписать существующие записи?
Если ответ - молчание, общие слова или «это слишком технические детали» - этот человек не работал с production AI-агентами в большой среде. Он работал с демо.
Никогда не запускайте пилот AI у такого подрядчика на боевых данных без полной возможности отката.
Это не про недоверие к подрядчику. Это про то, что Clean-Slate Bias - молодая, peer-reviewed на этой неделе проблема. Большая часть рынка ещё не знает, что она существует. Те, кто знает - либо люди из исследовательских лабораторий, либо те, кто уже сжёг себе руки на боевых пилотах.
Ищите вторых. Или приходите ко мне, поговорим.
Источники
arXiv 2605.10787 «ComplexMCP: Evaluation of LLM Agents in Dynamic, Interdependent, Large-Scale Tool Sandbox». Май 2026.
arXiv 2605.17467 «VerifyMAS: Hypothesis Verification for Failure Attribution in LLM Multi-Agent Systems». Май 2026.
ClawBench (arXiv 2604.14760). Исследователи UBC, Vector Institute, CMU. Апрель 2026.
MIT NANDA. State of GenAI in the Enterprise. 2025.
McKinsey State of AI 2026.
Gartner: AI Layoff Patterns Without ROI Correlation. Май 2026.
TAdviser/Onside. Опрос 50+ российских компаний по результатам пилотов GenAI. Май 2026.