Tencent выкатил переводчик, который помещается почти куда угодно
Tencent Hunyuan открыли Hy-MT2 - серию мультиязычных моделей для перевода с Dense и MoE-вариантами.
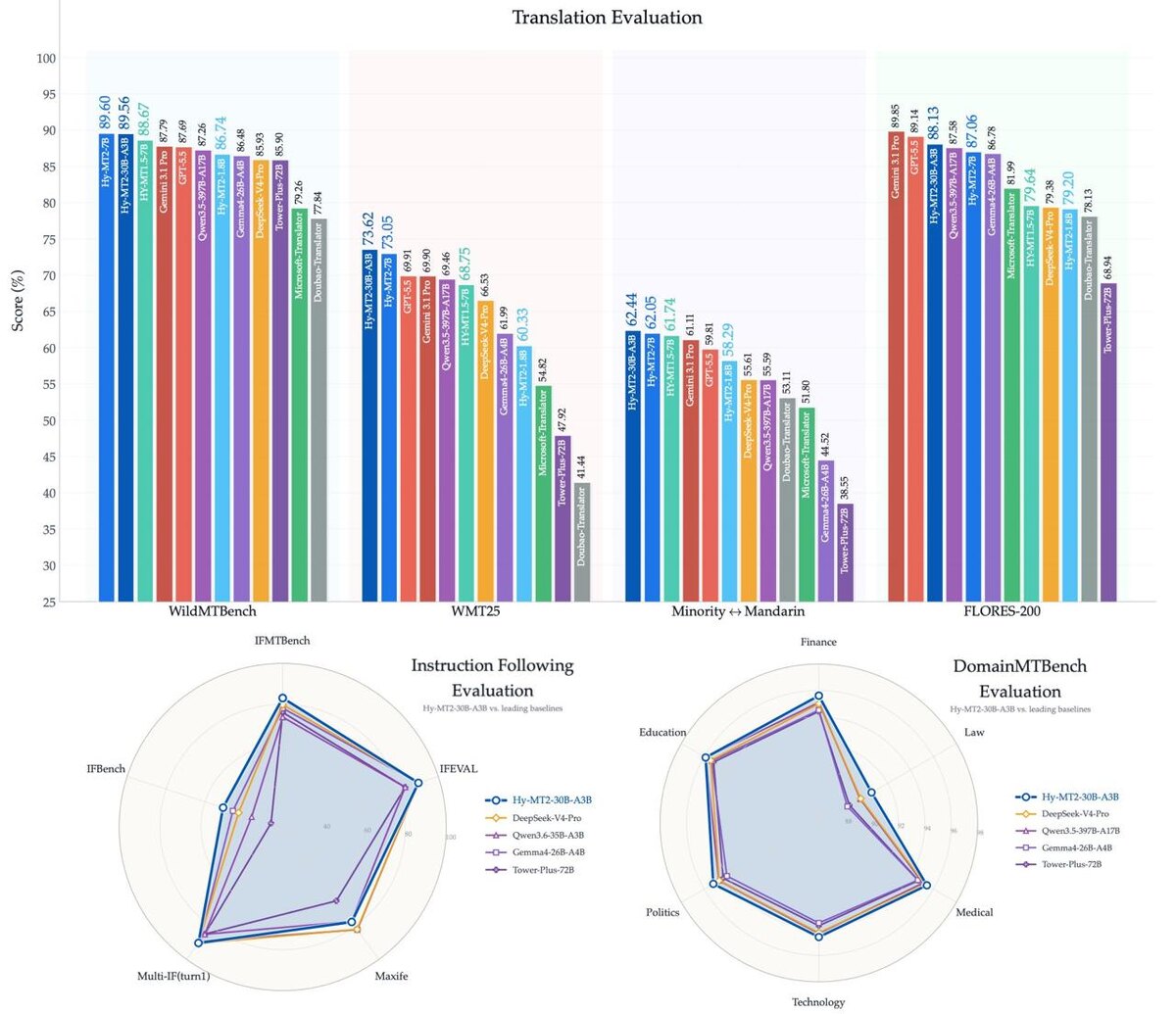
Главная фишка не в том, что это «ещё одна модель для перевода». Самое интересное - маленькая версия на 1.8B параметров.
Её ужали через AngelSlim до 1.25-bit, и теперь модель занимает всего 440 МБ. При этом на Apple A15 она работает в 1.5 раза быстрее, чем обычный 4-bit inference.
То есть нормальный on-device перевод уже не выглядит как фантазия, где нужно жертвовать либо скоростью, либо размером.
Что заявляют по моделям:
• поддержка 33 языков и 5 китайских диалектов
• версия 1.8B обходит Microsoft Translate и другие коммерческие API на FLORES-200
• версии 7B и 30B-A3B обходят DeepSeek-V4-Pro
• 7B достигает 97.9% от уровня Gemini 3.1 Pro Think
• 30B-A3B достигает 98.6% от уровня Gemini 3.1 Pro Think
• все три модели показывают 96-99% от Gemini 3.1 Pro Think на реальных и доменных бенчмарках
Плюс Tencent вместе с моделями открыли IFMTBench - бенчмарк для проверки того, насколько хорошо переводческие модели следуют инструкциям.
🤖 https://modelscope.ai/collections/Tencent-Hunyuan/Hy-MT2