Трансформеры в ИИ: архитектура, изменившая индустрию за 5 лет
В 2017 году исследователи Google опубликовали революционную статью «Attention Is All You Need», которая навсегда изменила траекторию развития искусственного интеллекта. Предложенная архитектура трансформеров стала фундаментом для всех современных больших языковых моделей — от GPT и Gemini до Claude и Midjourney. Эта работа положила начало новой эре в машинном обучении, когда модели впервые получили возможность по-настоящему понимать контекст и смысл человеческого языка.
До появления трансформеров индустрия использовала рекуррентные нейронные сети (RNN и LSTM), которые обрабатывали текст последовательно, слово за словом. Главная проблема этого подхода заключалась в неспособности удерживать контекст длинных фрагментов — к концу предложения модель теряла связь с его началом. Трансформеры радикально изменили парадигму: вся последовательность обрабатывается параллельно, и каждый элемент может анализировать все остальные одновременно. Это не просто улучшение — это полная смена концепции обработки информации.
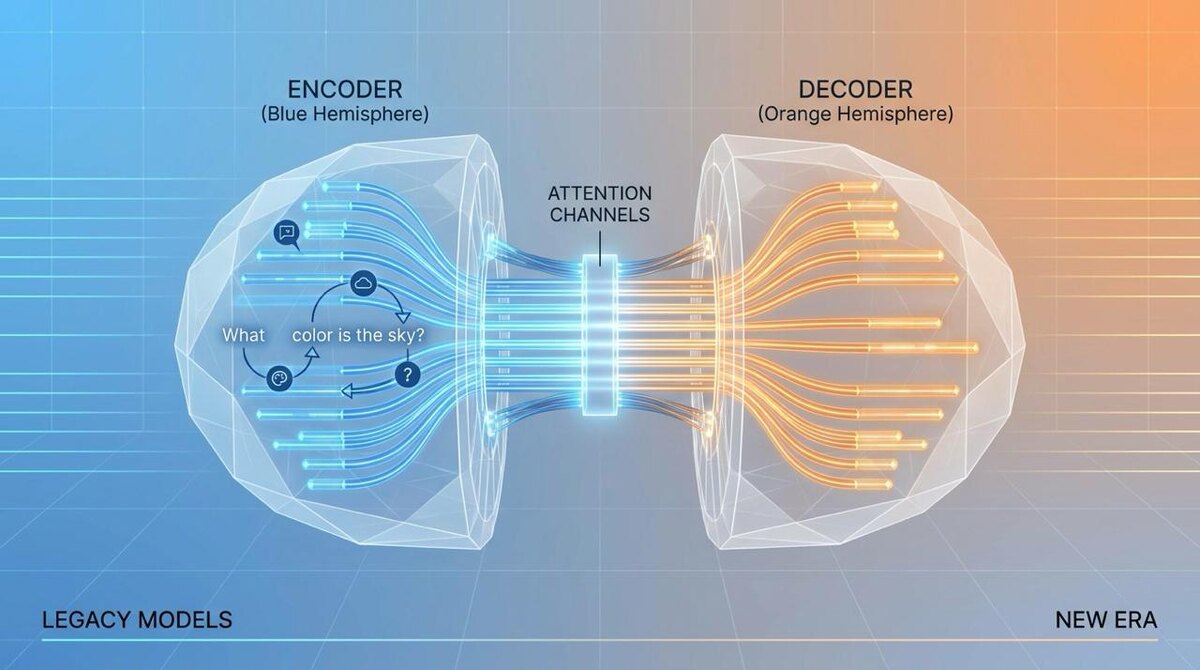
Сердце архитектуры — механизм самовнимания (Self-Attention). Он позволяет модели гибко определять, каким словам во входной фразе нужно уделить больше внимания при генерации ответа. Когда вы задаёте вопрос «Какого цвета небо?», трансформер создаёт внутреннее математическое представление, которое определяет взаимосвязь между словами «цвет», «небо» и «голубой», понимая их релевантность друг другу. Механизм внимания вычисляет веса важности для каждого слова относительно всех остальных, создавая динамическую карту зависимостей.
Классическая архитектура трансформера состоит из двух основных компонентов: энкодера и декодера. Энкодер преобразует входные данные в контекстное представление, а декодер генерирует выходную последовательность. Интересно, что многие современные языковые модели используют только одну половину этого механизма — GPT, например, работает исключительно на основе декодера, генерируя тексты автономно, в то время как BERT использует только энкодерную часть для задач понимания текста.
Многоголовое внимание — ещё одна критическая инновация. Параллельные «головы» внимания работают одновременно, каждая ищет свой тип зависимостей в данных. Это позволяет модели улавливать различные аспекты контекста: синтаксические связи, семантические отношения, логические зависимости. Типичная современная модель использует от 8 до 96 голов внимания, что обеспечивает многомерное понимание информации.
Трансформеры вывели нейросети из ниши узкоспециализированных инструментов в категорию универсальных систем. Сегодня эта архитектура применяется не только для обработки текста, но и для компьютерного зрения через Vision Transformers, анализа аудио, генерации изображений. Нейросети научились не только читать, но и видеть картинки, слышать звук — всё благодаря универсальности механизма внимания.
Однако индустрия не стоит на месте. В 2025-2026 годах аналитики фиксируют появление следующего поколения архитектур — диффузионных языковых моделей (Diffusion LLM) и State Space Models, включая архитектуру Mamba, которые могут превзойти трансформеры по эффективности и скорости обработки длинных последовательностей. Эти новые подходы обещают решить проблему квадратичной сложности вычислений, характерную для трансформеров. Но пока именно архитектура 2017 года остаётся золотым стандартом, на котором построены все топовые решения рынка искусственного интеллекта.
Трансформеры доказали: иногда одна научная статья способна перевернуть целую индустрию. 🧠
#ИскусственныйИнтеллект #Трансформеры #МашинноеОбучение #НейронныеСети #ТехнологииБудущего