В современной индустрии ИИ существует опасная мантра: «Данные — это новая нефть». Однако, как и сырая нефть, данные без многоступенчатой очистки превращаются в токсичный актив. В 2026 году, когда нейросети управляют критической инфраструктурой, вопрос «информационной гигиены» перестал быть теоретическим.
В этом материале мы проведем глубокое исследование того, как системное искажение обучающей выборки ломает математическую логику модели, превращая её в уверенного «цифрового лжеца».
1. Философия «Черного ящика» и иллюзия объективности
Большинство пользователей воспринимает ИИ как объективный оракул. Мы привыкли доверять числам: если алгоритм выдает прогноз с уверенностью 99%, мы верим ему больше, чем человеку. Но нейросеть — это не интеллект в человеческом понимании. Это сложнейшая функция аппроксимации, которая ищет статистические связи в массивах данных.
Нейросеть не обладает критическим мышлением. Она — зеркало датасета. Если в «учебнике» заложены системные ошибки, модель не просто их выучит — она сделает их фундаментом своей реальности.
2. Математический фундамент: Веса, Нейроны и Функция потерь
Чтобы понять, как рождается галлюцинация, нужно спуститься на уровень архитектуры.
Веса (Weights) — это память системы
Обучение — это процесс автоматической настройки весов. Каждый вес — это коэффициент значимости входного сигнала.
- Нейрон — единица обработки.
- Вес — определяет, насколько сильно конкретный параметр влияет на итоговый ответ.
Функция потерь (Loss Function): Компас в тумане
Это инструмент, измеряющий размер ошибки. В нашем эксперименте мы использовали MSE (Mean Squared Error):
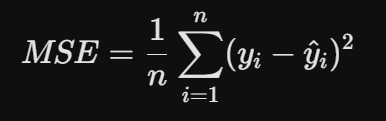
3. Гипотеза: Галлюцинация как побочный эффект оптимизации
Гипотеза исследования: Использование выборки с системными искажениями не просто снижает точность, а создает эффект «цифровой галлюцинации». Модель будет выдавать ложные ответы с высокой уверенностью, так как её функция потерь будет минимизирована относительно искаженной реальности, которую она приняла за единственную истину.
4. Программная реализация эксперимента
Для верификации деградации логики был проведен эксперимент на базе TensorFlow/Keras.
Архитектура модели
Мы выбрали задачу регрессии — сложение двух чисел. Это простейшая линейная зависимость, на которой лучше всего видна деградация весов.
- Скрытые слои: 32 и 16 нейронов.
- Активация: ReLU (она часто страдает от проблемы «умирающих нейронов» при больших ошибках).
- Оптимизатор: Adam.
Методология отравления данных
Были сформированы две группы данных по 1000 примеров:
- Чистая выборка: Идеальные математические примеры ($10+10=20$).
- Искаженная выборка (50% данных): К верному результату принудительно прибавлялось число 100. Это имитирует системный сбой датчика.
5. Анализ функции потерь: Визуализация хаоса
Графики Loss-функции наглядно показали разрыв:
- Чистые данные: Кривая ошибки экспоненциально падает к нулю. Модель выстроила четкие логические связи.
- Искаженные данные: Ошибка замерла на аномально высоком уровне — выше 2000 единиц. Входной сигнал вел к противоречивым результатам (то 20, то 120). Нейросеть попала в состояние «информационного хаоса», не имея возможности отбросить ошибку как шум.
6. Результаты: Эффект цифровой галлюцинации
Финальное тестирование показало катастрофический разрыв:
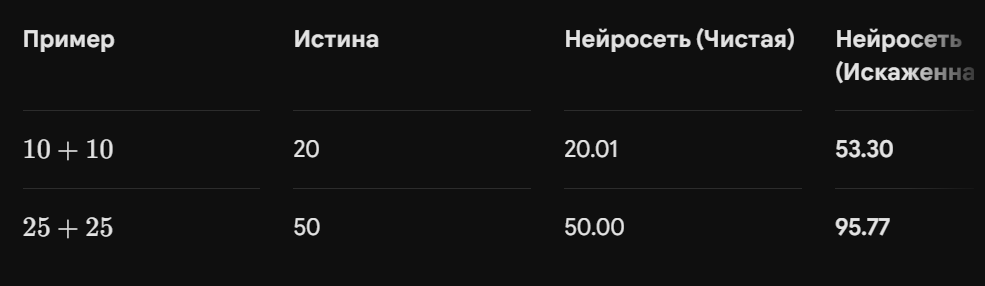
Откуда взялось число 53.30? Это результат математического конформизма. Нейросеть не смогла выбрать между правдой и ложью и попыталась их «усреднить» в своих весах. Она не понимает, что ошибается — она уверена, что таков закон этого искаженного цифрового мира.
7. Глобальные кейсы: Когда галлюцинации убивают
Кейс Amazon: Алгоритмические увольнения
Сбои Wi-Fi на складах привели к искажению метрик, которые получал ИИ. Галлюцинация алгоритма заключалась в том, что он считал эффективных сотрудников «медленными» и автоматически инициировал их увольнение. Это прямое доказательство: системный сбой в данных ведет к разрушению социальной и бизнес
Кейс IBM Watson Health: Крах надежд
Проект обучался на гипотетических кейсах вместо реальных медкарт. В результате нейросеть галлюцинировала, предлагая методы лечения, которые могли вызвать фатальную кровопотерю у пациентов. Проект, в который вложили миллиарды, был закрыт из-за «грязных» данных в его фундаменте.
8. Техническое приложение: Пример реализации на Python
Python
# Имитация внедрения хаоса в данные
def generate_poisoned_data(n=1000):
X = np.random.uniform(0, 50, (n, 2))
y = np.sum(X, axis=1)
# Внедряем аномалию в 50% случаев
for i in range(len(y)):
if i % 2 == 0:
y[i] += 100 # Имитация сбоя
return X, y
Этот фрагмент кода наглядно демонстрирует, как легко «отравить» будущее решение ИИ всего одной строчкой некорректной логики в препроцессинге.
9. Стратегии защиты: Как не дать ИИ сойти с ума?
Чтобы избежать деградации моделей, индустрия должна перейти от «моделе-центричного» к «данно-центричному» подходу:
- Robust Statistics: Использование функций потерь, устойчивых к аномалиям (например, Huber Loss).
- Цифровой аудит: Регулярная проверка обучающих выборок на предмет «информационных трещин».PDF
- Принцип Человеческого фильтра: Обязательная экспертная верификация решений ИИ в медицине и бизнесе.PDF
Почему слепое доверие к нейросетям — это профессиональный риск
Сегодня нейросети стали привычным инструментом для работы с информацией. Многие пользователи воспринимают ответы ИИ как объективные факты, доверяя им на 100%. Однако такой подход игнорирует фундаментальный принцип работы машинного обучения: модель — это не источник истины, а статистическая система, обучаемая на массивах данных.
Мой недавний эксперимент наглядно демонстрирует, к чему это приводит. Обучая модель на наборе данных, содержащем намеренные ошибки, я увидел, что нейросеть не отсеивает ложную информацию, а интегрирует её в свою логику. Вместо того чтобы выявить противоречие, алгоритм «усредняет» корректные данные с ошибочными, выдавая результат, который внешне выглядит убедительно, но по сути является математически неверным.
Основные выводы, которые важно осознавать каждому пользователю:
- Отсутствие верификации: Нейросеть не обладает навыком критического анализа. Она не «понимает», что именно она генерирует. Если в обучающей выборке присутствуют искажения, модель будет транслировать их как корректные данные.
- Иллюзия компетентности: ИИ формулирует ответы с высокой степенью уверенности, независимо от их фактической точности. Это создает опасную иллюзию экспертности, заставляя пользователя снижать уровень контроля.
- Когнитивное делегирование: Перекладывая анализ информации на алгоритмы, мы теряем навык самостоятельной проверки данных. В долгосрочной перспективе это делает нас зависимыми от ошибок, заложенных в систему.
Как работать с ИИ безопасно:
- Относитесь к результатам как к черновикам. Любой прогноз, расчет или аргумент, полученный от нейросети, требует перепроверки через внешние, независимые источники.
- Ищите подтверждение, а не оправдание. Используйте ИИ для сбора идей, но не для принятия окончательных решений без верификации данных.
- Учитывайте контекст данных. Понимайте, что качество работы модели прямо зависит от качества данных, на которых она обучалась. Если исходные данные сомнительны — результат будет предсказуемо некорректным.
Технологии ИИ позволяют значительно ускорить работу, но они не снимают с человека ответственности за результат. Критическое мышление остается единственным фильтром, позволяющим отделить полезную информацию от программных ошибок и искажений.
Заключение: Архитектура доверия
Главный вывод нашего исследования: эффективность любого алгоритма на 100% ограничена чистотой входной информации. В мире, где ИИ принимает за нас решения, мы не имеем права на «грязные данные». Без жесткой экспертной фильтрации мы рискуем оказаться в реальности, где критические решения принимаются на основе математически выверенной, но абсолютно ложной галлюцинации.