Лучшее вложение в мою ИИ-команду оказалось обычной папкой wiki.
Не новая модель.
Не какой-нить супер GitHub репозиторий.
Не промпт на 40 экранов.
Обычная папка с markdown-файлами, которую видят Claude Code, Hermes, OpenClaw, Codex и все мои рабочие системы.
Я даю запрос и агент читает перед ответом читает файлы памяти.
Не додумывает.
Не вспоминает из воздуха.
Не делает вид, что «сейчас напишет как Макс Галсон». А потом скажет «ой, я не использовал навыки и не читал инструкции».
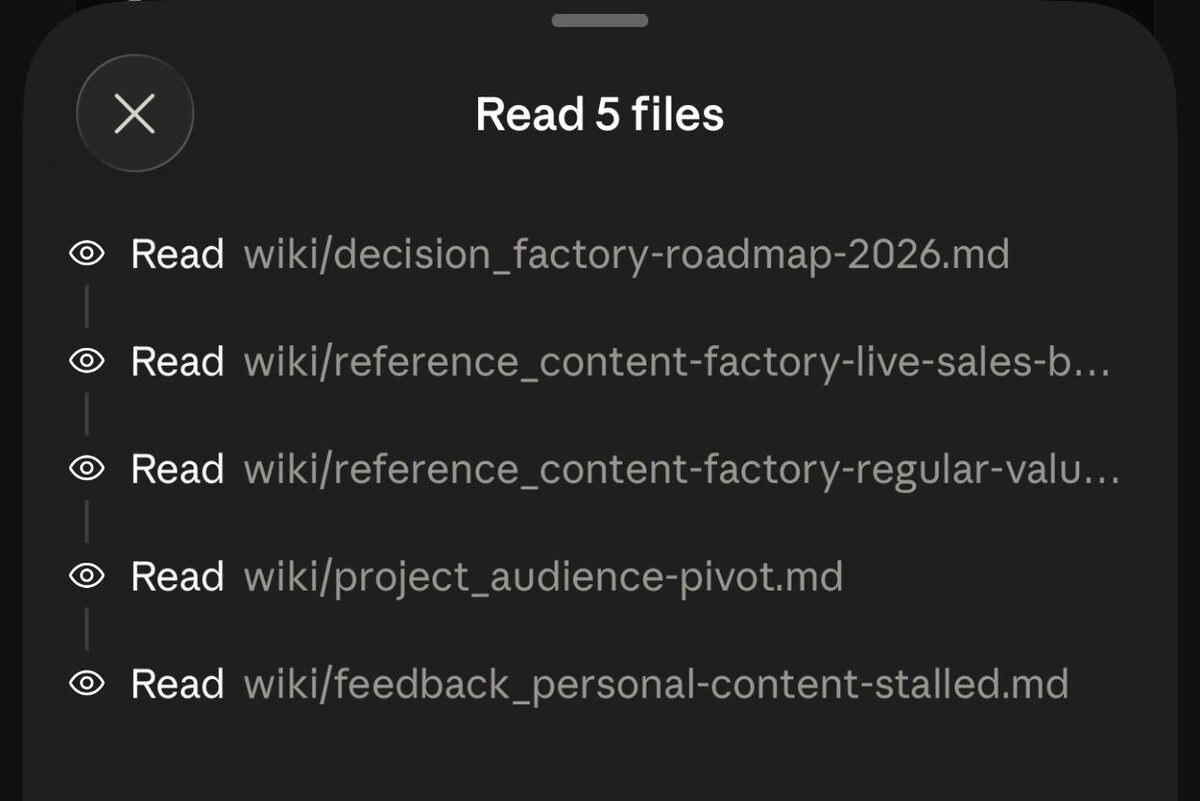
Он сначала открывает память:
- roadmap проекта
- sales-блоки Фабрики
- регулярную ценность
- pivot аудитории
- feedback, почему личный контент застопорился
И только потом что-то делает.
Вот в этом разница между чатом и рабочей ИИ-командой.
Чат получил вопрос, выдал текст, умер.
Команда сначала смотрит:
- какие решения уже приняты
- что раньше не сработало
- какие правила я сам поправил
- где текущий контекст проекта
- какие файлы считаются источником правды
И уже из этого пишет пост, чинит код, планирует продукт, собирает урок, отвечает в чате.
Самая большая проблема агентов сейчас не интеллект. Интеллекта уже дофига. Контекста в рамках одной сессии по 1 млн дают.
Проблема в амнезии.
Каждый новый запуск как новый стажёр: вроде умный, но опять спрашивает, кто мы, что продаём, как говорим, что уже решили.
Я это прям физически устал повторять.
Поэтому у меня появилась wiki:
- MEMORY.md: индекс
- project_*.md: состояние проектов
- decision_*.md: принятые решения
- feedback_*.md: ошибки и правки
- reference_*.md: схемы, правила, источники
Плюс правила, чтобы агенты сами не засирали память мусором: не сохранять токены, не тащить сырой чат, не записывать временный шум как истину.
И кайф в том, что это работает не в одном инструменте.
Разные тела. Claude, OpenClaw, Hermes, Codex.
Везде разный мозг Opus, Sonnet, ChatGPT. Но у всех одна память.
На ноуте, на VPS, в Telegram, в репозиториях.
Один контекст. Разные исполнители.
К чему я это всё веду: если ты сейчас ковыряешь ИИ-агентов, не начинай с «какую модель выбрать».
Начни с вопроса:
что мой агент видит перед тем, как ответить?
Проверь прямо сегодня.
Создай одну папку wiki и 5 файлов:
project_main.md
decision_main.md
feedback_main.md
reference_main.md
И в системной инструкции напиши: перед задачей читать wiki/MEMORY.md и релевантные файлы.
Будет просто меньше тупых повторов.
Главный актив в ИИ-команде — контекст.
Модель обновится. Инструмент поменяется. А твои решения, правки, стиль и ошибки должны оставаться в системе.
И на интенсиве настройка памяти будет обязательным пунктом внедрения Фабрики в систему работы.