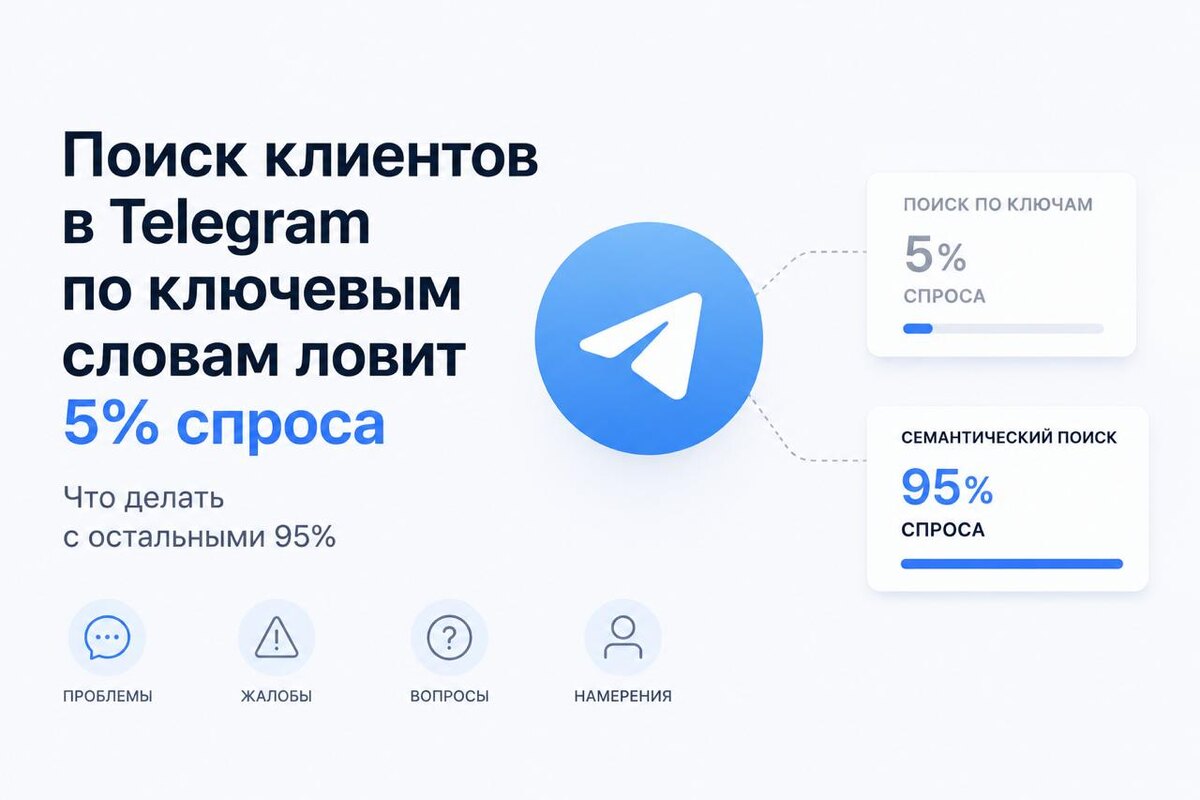
Любой парсер Telegram-чатов работает одинаково: задаёте список ключей — «нужен юрист», «ищу бухгалтера» — он выдёргивает совпадения и складывает в таблицу. Через неделю менеджер говорит: «там одна реклама, лидов почти нет».
Это не проблема конкретного парсера. Это проблема подхода.
Почему ключи ловят не тех
Возьмём список ключей юриста: «нужен юрист», «помощь юриста», «адвокат», «консультация».
В типичном чате на 1000 сообщений по таким ключам найдётся 30–50 совпадений. Внутри:
- 20–25 — реклама самих юристов;
- 5–10 — обсуждения юристов в третьем лице;
- 5–10 — пограничные случаи (кино, профессия, образование);
- 1–3 — реальные люди с реальной проблемой.
Из 30–50 «совпадений» — 1–3 потенциальных лида.
Что упускают ключи
Сообщения, в которых нет ни одного «канонического» ключа услуги, но есть человек с проблемой:
— «Закрыл ИП год назад, прилетело требование, что делать?»
— «Купили в ипотеку, продавец просит сверх договора, это нормально?»
— «Менеджеры теряют клиентов, всё в Excel, голова кругом».
— «Сын в 11 классе, до ЕГЭ 4 месяца, пробник на 38, реально вытянуть?»
В каждом — горячий лид. Но он сам не знает, что он лид: сформулировал проблему, не запрос услуги. Поиск по ключам этих людей не видит. Никогда.
Три типа намерений
Покупательские сигналы в Telegram-чатах звучат тремя способами:
1. Прямой запрос услуги — «Ищу X». Самый редкий. Часто шум. По ключам ловится.
2. Описание проблемы — «У меня случилось X, что делать?». Самый горячий. По ключам не ловится.
3. Жалоба — «Достало, что X». Латентный сигнал. По ключам не ловится.
Если канал работает только с первым типом — вы видите 5–10% спроса. Горячие сидят во втором и третьем.
Как собрать семантический поиск инхаус
Ничего магического. Минимальная сборка пишется за выходные.
Стек:
- Telethon — читать чаты (Python, MTProto-клиент).
- Любая LLM с дешёвым API — классифицировать сообщения.
- SQLite или Google Sheets — складывать результаты.
Логика:
1. Telethon подписывается на 5–10 чатов вашей ниши и пишет каждое новое сообщение в очередь.
2. Скрипт берёт сообщение и отправляет в LLM с промптом: «вот сообщение, вот мои 5 тегов, верни тег или "шум"».
3. Если не «шум» — пишет в таблицу с пометкой времени, чата и тега.
4. Утром смотрите таблицу.
Бюджет на LLM: при 500 сообщений в день и копеечной модели на классификации — пара долларов в месяц.
Что важно при сборке
Промпт классификатора делайте конкретным. Универсальное «найди мне лидов» работает плохо. Хороший промпт — это 5–8 ваших тегов, к каждому 2–3 примера сообщений. Объём — страница текста.
Не пытайтесь одним промптом и классифицировать, и отвечать. Это удваивает цену и роняет точность. Сначала лёгкая модель решает «лид/не лид». Если лид — отдельно прогоняете через большую модель для контекста.
Сохраняйте всё, фильтруйте потом. Не выбрасывайте «шумовые» сообщения сразу. Через месяц захотите изменить теги и пожалеете.
Что получают читатели, которые попробовали
Знакомый маркетолог из ниши автомойки самообслуживания собрал такую штуку за неделю на Python и Google-таблицах. Через 14 дней увидел 60 потенциальных лидов в 4 чатах региона. По ключам он же раньше находил 6–8.
Юрист из Краснодара написал после похожей статьи, что переделала свой парсер с ключей на классификацию через LLM. Точность выросла с 25% до 80%, время менеджера на разбор сократилось вдвое.
Это лишь пример экономики, семантика обычно даёт в 5–10 раз больше реального сигнала, чем ключи. Не из-за магии, а потому что 80–90% спроса формулируется не как прямой запрос услуги.
Честные ограничения
Семантика тоже не серебряная пуля.
- Стоит дороже в эксплуатации (LLM-токены против регулярок).
- Точность 70–80% на старте, до 90%+ доходит за 1–2 месяца калибровки.
- Зависит от промптов и примеров. Универсальный промпт работает плохо.
- Не отменяет человека на финале. Решение «отвечать или нет» — всегда живое.
Если кто-то продаёт «магический парсер, который сам находит идеальных лидов» — это маркетинг.
У нас в студии разработки и внедрения AI эта схема выросла в pulsar-tg — внутренний инструмент, который сейчас стал публично доступным продуктом с бесплатным периодом использования. Но для одного человека и 5–10 чатов своего инхаус-варианта хватает с запасом.