
В прошлой статье мы обнажили математический скелет нейросетей, написав собственный алгоритм с абсолютного нуля. Мы убедились, что под капотом ИИ нет никакой мистики — лишь строгая симфония матриц и градиентов. Но сегодня мы делаем шаг из академической песочницы в реальный мир. А реальность такова, что мы живем в эпоху когнитивного паноптикума. Облачные корпорации предоставляют нам невероятно умные нейросети, но взамен требуют наши данные, анализируют каждый промпт и навязывают жесткую цензуру. Истинная свобода в XXI веке кроется в децентрализации.
Сегодня я покажу, как превратить ваш домашний компьютер в независимый оазис искусственного интеллекта. Мы развернем полноценную Большую Языковую Модель (LLM) локально. Бесплатно. И без единого байта, отправленного в интернет.
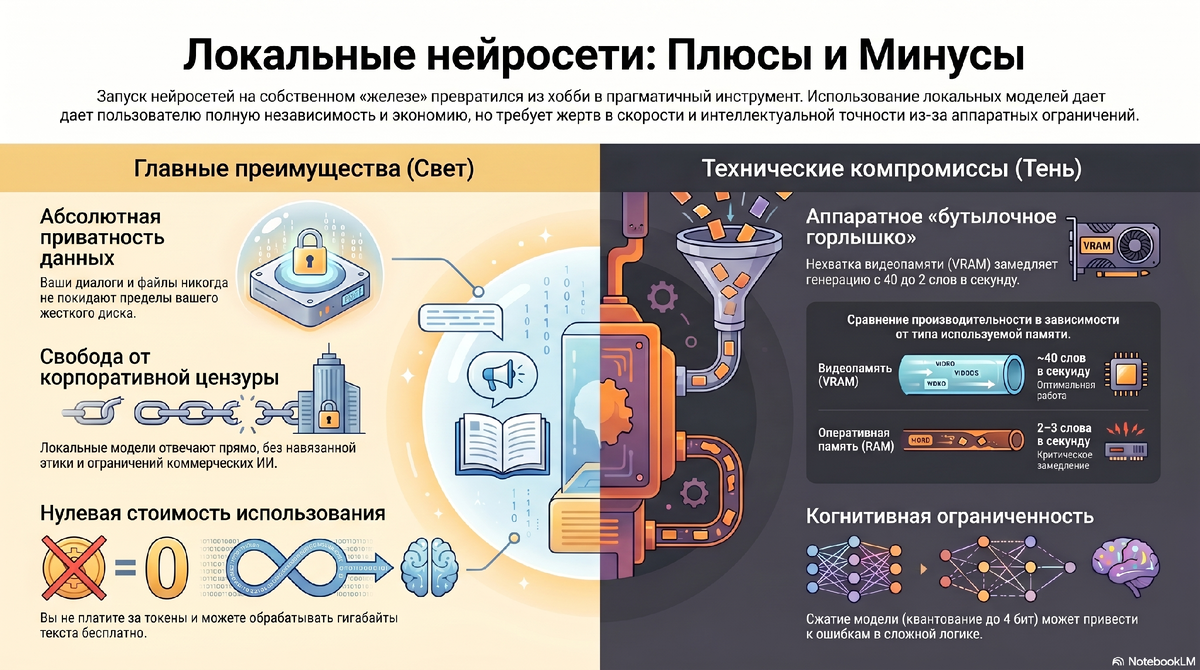
1. Зачем вам локальная LLM? (Свет и тени децентрализации)
Запуск ИИ на домашнем железе — это не просто развлечение для гиков, а прагматичный инструмент. У него есть четкий набор преимуществ и неизбежных компромиссов.
В чем безоговорочные плюсы?
- Абсолютная приватность. Ваши диалоги никогда не покинут пределы жесткого диска. Вы можете анализировать конфиденциальные финансовые отчеты, личные дневники или проприетарный код своей компании без страха утечки.
- Свобода от цензуры. Коммерческие модели (вроде ChatGPT или Claude) страдают от гипертрофированной корпоративной этики (alignment). Локальные open-source модели отвечают на поставленные вопросы без морализаторства и ограничений.
- Нулевая стоимость инференса. Вы больше не платите за токены. Модель может работать сутками напролет, обрабатывая гигабайты текста совершенно бесплатно.
В чем минусы и откуда они берутся?
- Аппаратное «бутылочное горлышко». Главный враг локального ИИ — нехватка видеопамяти (VRAM). Если модель не помещается в память видеокарты, система перебрасывает нагрузку на медленную оперативную память (RAM). Из-за этого скорость генерации падает с 40 слов в секунду до мучительных 2-3 слов.
- Когнитивная ограниченность. Чтобы уместить гигантскую модель на 8 миллиардов параметров в домашний ПК, её подвергают квантованию (сжимают точность весов с 16 бит до 4 бит). ИИ становится в разы «легче». Для обычных бесед эта потеря интеллекта почти незаметна, но в задач со сложной многоступенчатой логикой урезанная сеть может начать ошибаться.
2. Архитектура выбора: Как измерить свой цифровой потенциал?
Прежде чем скачивать модели, нужно трезво оценить возможности вашего компьютера. Для расчета аппетитов нейросети существует простое эмпирическое правило:
Формула расчета памяти (при стандарте сжатия Q4):
1 Миллиард параметров (1B) ≈ 0.7 ГБ памяти
- Модель на 8B (например, Llama 3) заберет около 5.6 ГБ памяти.
- Модель на 14B (например, Qwen 2.5) потребует около 9.8 ГБ памяти.
Важный нюанс: Никогда не забивайте память под завязку. Всегда оставляйте минимум 2-3 ГБ для работы самой операционной системы. Также учитывайте «контекстное окно» (историю вашей переписки): по мере продолжения диалога ИИ будет резервировать под нее дополнительную память (обычно от 1 до 2 ГБ).
Где живет разум: Видеокарта (VRAM) против ОЗУ (RAM)
Идеальный сценарий — когда вся модель целиком помещается в видеокарту. Тогда ИИ будет "летать", печатая текст быстрее, чем вы способны его читать. Если VRAM не хватает, в дело вступает процессор и обычная оперативка — магия сохранится, но ответов придется подождать.
(Исключение составляют Mac на чипах M1/M2/M3/M4: их архитектура использует объединенную память, поэтому нейросети там работают потрясающе быстро даже без отдельной видеокарты).
3. Битва платформ и их порог входа
Экосистема шагнула далеко вперед: вам больше не нужно писать сложный код на Python для запуска ИИ. Существуют удобные визуальные «движки». Выбирайте тот, что подходит вашему железу:
- GPT4All (Спасательный круг для старого ПК) Порог входа: от 4 до 8 ГБ ОЗУ, процессор не старше 2015 года.
Платформа создана для работы исключительно на процессоре (CPU). Идеально, если у вас вообще нет дискретной видеокарты или под рукой только старый офисный ноутбук. - Ollama (Для гиков и разработчиков) Порог входа: от 8 ГБ ОЗУ.
Работает как невидимый фоновый сервер, не тратя ресурсы на красивые интерфейсы. Это лучший вариант, если вы планируете интегрировать ИИ в свой собственный код. Потрясающе оптимизирована под Apple Silicon. - LM Studio (Для максимального комфорта) Порог входа: от 8 ГБ ОЗУ (дискретная видеокарта строго рекомендуется).
Роскошный интерфейс, визуально неотличимый от ChatGPT. Встроенный каталог позволяет искать и скачивать модели в один клик. Идеальный выбор для пользователей с современным ПК.
4. Стартовый арсенал: Выбор когнитивного ядра
Нейросети, как и люди, имеют узкие специализации. Вот лучшие модели для старта, разбитые по их сильным сторонам:
1. Универсалы и Логики (Тексты, генерация идей, рассуждения)
- Llama 3 (8B) — Золотой стандарт от Meta. Глубокая эрудиция и отличная логика.
Требования: от 8 ГБ RAM (в идеале видеокарта на 6-8 ГБ VRAM). - Qwen 2.5 (7B) — Феноменально понимает нюансы русского языка. Очень креативная модель с нестандартным мышлением.
Требования: от 8 ГБ RAM (видеокарта на 6 ГБ VRAM). - Phi-3 Mini (3.8B) — Малыш от Microsoft. Демонстрирует поразительную дедукцию при своих крошечных размерах.
Требования: от 4 ГБ RAM (потянет практически любой ноутбук).
2. Архитекторы Кода (Написание скриптов и рефакторинг)
- Qwen 2.5 Coder (7B) — Обучена на миллиардах строк кода. Пишет на Python, JS и C++ увереннее многих джуниоров.
Требования: 8 ГБ RAM / 6 ГБ VRAM. - DeepSeek-Coder-V2-Lite (16B) — Мощная архитектура смеси экспертов (MoE). Справляется с комплексной логикой и сложным программированием.
Требования: от 16 ГБ RAM (видеокарта на 12 ГБ VRAM).
3. Визуальные анализаторы (Чтение изображений)
Это мультимодальные сети. Им можно «скормить» график, мем или скриншот ошибки в коде, и они поймут, что изображено на картинке.
- Moondream2 (1.8B) — Крошечная, но на удивление зоркая модель для базового распознавания объектов.
Требования: всего 3 ГБ памяти. Оптимально для слабых машин. - LLaVA 1.5 (7B) — Более тяжеловесная модель, способная в деталях описывать сложные визуальные сцены.
Требования: от 8 ГБ VRAM на видеокарте.
5. Пошаговая инструкция (Разворачиваем ИИ через LM Studio)
Поскольку наша главная цель — комфорт и эстетика использования, мы пойдем по пути LM Studio.
Шаг 1: Установка среды
Перейдите на официальный сайт lmstudio.ai и скачайте дистрибутив для вашей операционной системы.
Шаг 2: Выбор цифрового «мозга»
Откройте программу. В поисковой строке на главном экране введите название модели из нашего списка (например, Qwen 2.5 7B Instruct).
Шаг 3: Магия формата GGUF
В результатах поиска вы увидите странные приписки вроде GGUF и уровни сжатия (например, Q4_K_M). Не пугайтесь. Выбирайте файл именно с меткой Q4_K_M или Q5_K_M. Это проверенный баланс между тем, насколько модель сохраняет свой "ум", и тем, как быстро она будет бегать на вашем ПК. Нажмите Download.
Шаг 4: Инициализация и первый диалог
Перейдите во вкладку чата (иконка облачка слева), выберите скачанную модель в самом верхнем выпадающем меню и дождитесь загрузки.
Всё. Прямо сейчас на вашем жестком диске, без единого пинга к серверам корпораций, пробудилась искра эмерджентного интеллекта. Можете написать свое первое сообщение.
Эпилог: Ваша цифровая крепость
То, что еще пару лет назад требовало суперкомпьютеров стоимостью в миллионы долларов, сегодня работает на вашем домашнем ПК — где-то между чашкой утреннего кофе и открытым браузером. Локальные LLM возвращают нам контроль над технологией.
Ваш компьютер больше не просто терминал для потребления чужого контента. Теперь это вместилище персонального, независимого цифрового разума, ключи от которого есть только у вас.
А какую задачу вы бы поручили своему личному ИИ в первую очередь: написать скрипт, проанализировать запутанные документы или просто обсудить философию киберпанка? Делитесь своими идеями и результатами в комментариях — давайте обсудим!