
Машинная извлекаемость (extractability) – это фундамент вашего присутствия в выдаче нейросетей. Если вы внедрили AEO (Answer Engine Optimization) и GEO (Generative Engine Optimization), но нейросеть не цитирует ваш бренд, проблема часто кроется не в качестве текста, а в архитектуре данных.
В этой статье мы разберём, какие конкретно элементы страницы блокируют попадание в ответы LLM, как структурировать B2B-контент для рынка РФ и как диагностировать проблемы «невидимости» для нейросетей. Мы не говорим здесь про SEO-ранжирование или дизайн. Мы говорим о том, как сделать ваш контент машиночитаемым.
Что такое extractability в AEO и GEO
Extractability (Извлекаемость) – это техническая способность нейросети выделить конкретный смысловой фрагмент из кода страницы, интерпретировать его как прямой ответ на запрос и связать с вашим брендом без потери контекста.
В классическом SEO мы боролись за индексацию. В AEO и GEO мы боремся за векторизацию правильных кусков текста. Когда пользователь спрашивает: «Какие CRM подходят для крупного бизнеса в РФ?», LLM не читает вашу страницу целиком. Она ищет «ответный блок» – автономную единицу смысла.
Если контент есть, но он «размазан» по странице или свёрстан нелогично, extractability стремится к нулю. Нейросеть видит текст, но не может извлечь из него фактуру для генерации ответа.
Для B2B цена ошибки – отсутствие в шорт-листе рекомендаций нейросети, когда ваш клиент выбирает поставщика.
Ключевые элементы страницы, влияющие на извлечение
Ниже приведён список элементов, которые являются «крючками» для LLM. Если они настроены неверно, генеративная модель проигнорирует информацию.
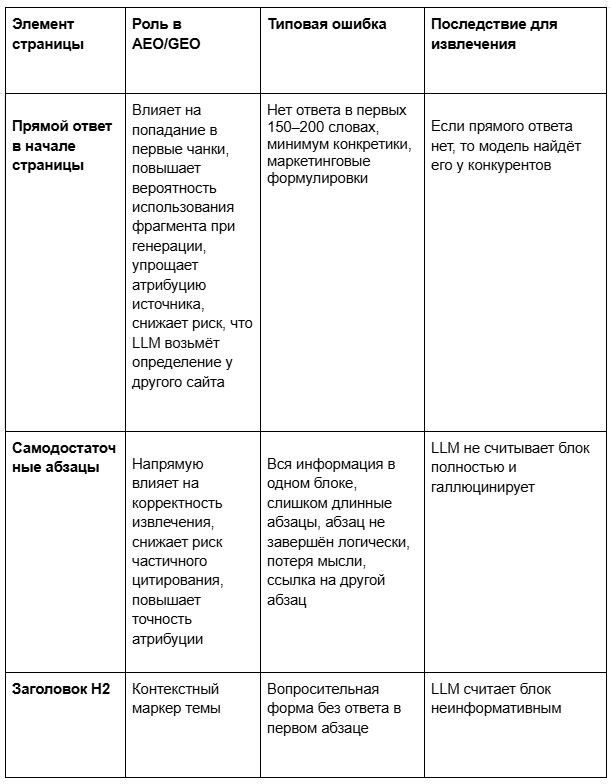
Прямой ответ в начале страницы
Функция: обеспечение извлечения ключевого определения или вывода retrieval-системами за счёт размещения самодостаточного ответа в первых 150–200 словах документа.
Ошибка: размещение в начале страницы вводных, маркетинговых или абстрактных формулировок, которые не содержат прямого ответа на целевой вопрос пользователя («что такое X?», «для чего нужно Y?»).
Эффект для LLM: нейросеть не находит в первых чанках готового определения, снижает вес фрагмента или пропускает его, и вынуждена искать ответ у конкурентов, чей контент структурирован правильно. Это критически снижает вероятность цитирования вашего источника.
Самодостаточные абзацы
Функция: обеспечение корректного извлечения и цитирования контента LLM за счёт логической завершённости каждого абзаца как самостоятельной смысловой единицы.
Ошибка: нарушение границ смысловых блоков – смешение нескольких идей в одном абзаце, обрывание мысли с переносом в другой чанк или создание зависимостей между абзацами через отсылки («как будет показано ниже»).
Эффект для LLM: при нарезке документа на чанки (300–500 токенов) логически связанные элементы могут попасть в разные фрагменты. Нейросеть получает обрывочную или неполную информацию, что приводит к искажению смысла, снижению вероятности цитирования или использованию фрагмента не по назначению.
Заголовочный комплекс (H1–H3)
Функция: создание иерархии смыслов и маркировка начала нового контекстного блока. Заголовки служат «якорями» для разбивки текста на фрагменты для обработки.
Ошибка: использование креативных, абстрактных заголовков («Путь к успеху», «Синергия возможностей») или нарушение иерархии (H3 перед H2).
Эффект для LLM: нейросеть не понимает, к какой теме относится текст ниже. Вероятность того, что этот блок будет использован как ответ на конкретный вопрос, падает.
Лид-абзац (Answer Target)
Функция: прямой, концентрированный ответ на запрос, заложенный в заголовке H2/H3. Это самый ценный элемент для extractability.
Ошибка: долгое вступление, «вода», размытые формулировки («В современном мире каждая компания сталкивается...»).
Эффект для LLM: модель классифицирует абзац как «шум» и не использует его для генерации ответа (Zero-shot extraction fail).
Маркированные списки (List Items)
Функция: структурирование перечислений, этапов, характеристик. Списки – это готовые данные для алгоритмов.
Ошибка: оформление перечислений сплошным текстом через запятую или использование псевдосписков (разрыв строк без тегов <ul>/<ol>).
Эффект для LLM: потеря структуры. Нейросеть может не распознать это как перечень шагов или свойств, что критично для запросов «Как сделать...» или «Топ-5 функций...».
Табличные данные (Table Data)
Функция: сравнение параметров, цен, тарифов. Идеальный формат для B2B-сравнений.
Ошибка: вёрстка таблицы картинкой или сложной div-структурой, которую бот не может распарсить как таблицу.
Эффект для LLM: данные становятся невидимыми. LLM «галлюцинирует», выдумывая цены, или отвечает «информации не найдено».
Автономность смысловых блоков
Автономность – это главное требование к extractability.
Суть требования: любой раздел вашего материала (от заголовка H2 до следующего H2) должен быть понятен, если его «вырезать» из статьи и показать отдельно.
LLM при обработке данных часто использует RAG (Retrieval-Augmented Generation). Она берёт только релевантный кусок текста. Если этот кусок ссылается на «то, что мы писали выше», или использует местоимения без существительных, контекст теряется.
Семантическая ошибка
- Плохо: «Retrieval в RAG используется для поиска документов. Он помогает модели работать с внешними источниками. Далее рассмотрим его преимущества и ограничения, а также сравним с fine-tuning». (3 разные идеи в одном абзаце).
- Хорошо: «Retrieval в RAG — это этап, на котором система выбирает релевантные документы из базы знаний до начала генерации ответа. Эти документы передаются в контекст модели и определяют информационное поле будущего ответа». (Одна идея — как работает retrieval)
Последствие неавтономности
Если текст не автономен, нейросеть при формировании ответа либо проигнорирует его (так как уверенность в фактах низкая), либо припишет свойства вашего продукта другому бренду, упомянутому в запросе. Для AEO-, GEO-стратегии это фатально.
Географический контекст и его размещение
Для продвижения в РФ недостаточно просто иметь домен.ru. География должна быть «зашита» в структуру контента.
Проблема: нейросети часто обучаются на глобальных данных. Если вы не укажете явно географическую привязку внутри смыслового блока, LLM может выдать ответ, нерелевантный для РФ (например, посоветовать софт, ушедший с рынка).
Элементы, отвечающие за GEO-привязку:
- Топонимы в заголовках: «Особенности логистики в Москве и МО».
- Указание валют и юрисдикций: рубли, НДС, ФЗ-152.
- Локальные сущности: упоминание российских аналогов, интеграций с 1С, Госуслугами.
Если убрать из текста название города/страны, смысл меняется? Если нет, то географический контекст слабый. В AEO, GEO это приведёт к тому, что по запросу «лучшие поставщики в России» вас не покажут, так как алгоритм не связал ваш контент с регионом «РФ».
Типовые структурные ошибки
Как быстро диагностировать проблемы извлекаемости
Проведите аудит материала до масштабирования. Это чек-лист для проверки extractability одной страницы.
Поиск прямого ответа в начале страницы
- Задайте вопрос к заголовку H1.
- Вопрос: Содержится ли прямой ответ в первом предложении после заголовка?
- Если нет, то вы теряете шанс попасть в сниппет или быстрый ответ нейросети (Featured Snippet / Generative Snapshot). Перенесите суть наверх.
Тест на автономность
- Скопируйте случайный блок (H2 + текст под ним) в отдельный файл.
- Вопрос: Понятно ли, о чём речь, о каком продукте и в какой стране, без контекста предыдущих блоков?
- Если нет, то добавьте название бренда и продукта внутрь текста. Уберите местоимения.
Проверка иерархии
- Просмотрите только заголовки H1–H3.
- Вопрос: Понятна ли структура и логика статьи без чтения основного текста?
- Если нет, то LLM тоже не поймёт структуру. Перепишите заголовки.
Проверка GEO-слоя
- Вопрос: Есть ли в тексте слова «Россия», «РФ», названия городов или локальные термины (ИНН, ООО)?
- Если нет, то для нейросети ваш контент висит в вакууме. Добавьте локализацию.
FAQ
Ниже ответы на частые вопросы о механике взаимодействия контента и LLM.
Как структура материалов влияет на извлекаемость ответов ChatGPT и YandexGPT?
Структура (прямой ответ в начале страницы, самостоятельные абзацы, HTML-теги H1-H6) помогает парсерам LLM разбивать текст на логические сегменты. Чёткая структура упрощает векторизацию данных. Если структуры нет (сплошной текст), нейросеть может смешать разные смыслы, что приведёт к галлюцинациям или полному игнорированию контента.
Почему LLM игнорируют текст, если он не автономен?
Нейросети имеют ограниченное «окно внимания» и часто работают с фрагментами. Если во фрагменте написано «как указано выше, это решение эффективно», а само решение описано в другом фрагменте, связь разрывается. LLM отбрасывает такой фрагмент, как бессмысленный.
Как определить, что проблема AEO/GEO связана со структурой материала, а не с интентом?
Если вы видите, что страница релевантна запросу, содержит правильные факты, но нейросеть упорно не цитирует её, то это проблема структуры (extractability). Если же нейросеть цитирует, но ответ не удовлетворяет пользователя (не тот продукт, не та услуга), то это проблема интента.
Как влияет размещение на сторонних площадках на AEO/GEO?
Сторонние площадки (vc, habr, профильные медиа) часто имеют высокую техническую трастовость и жёсткую структуру вёрстки. Это повышает extractability.
На что влияет AEO, а на что GEO?
AEO (Answer Engine Optimization) влияет на попадание в Featured Snippet или голосовой ответ (Google Assistant, Siri, Alexa, Google AI Overviews). GEO (Generative Engine Optimization) отвечает за цитирование и рекомендации в синтезированном ответе LLM (ChatGPT, Perplexity, Claude, Gemini, Bing Chat).
Вывод: смена парадигмы от «SEO-текста» к «LLM-фиду»
В эпоху AEO и GEO ваш контент перестаёт быть просто текстом. Теперь это структурированный набор данных (dataset), который вы передаёте нейросетям.
Если страница не проходит тест на extractability, для B2B-рынка РФ это означает одно: вы добровольно отдаёте долю рынка конкурентам, чья вёрстка понятнее алгоритмам. Нейросеть не будет «додумывать» за вас или искать скрытый смысл в полотне текста. Она просто возьмёт ответ у того, кто упаковал его в быстрый ответ, список, таблицу или чёткий абзац и разместил на ресурсах, откуда ИИ чаще всего берут свои ответы в вашей нише.
Мы в социальных сетях: YouTube VK Телеграм-бот
Другие полезные материалы на канале: