Мы живем в эпоху когнитивной сингулярности. Тема искусственного интеллекта звучит из каждого утюга, превратившись в навязчивый цифровой шум. Но как именно работает эта «магия» на фундаментальном уровне?
В этой статье мы развеем туман сложных терминов. Мы откажемся от тяжелых фреймворков и напишем собственную нейросеть на Python с абсолютного нуля, опираясь только на базовую математику. Наша цель — научить её распознавать рукописные цифры.
1. Введение: Что такое нейросеть?
По своей сути, нейросеть — это изящная математическая абстракция, имитирующая архитектуру человеческого мозга. Как человек учится отличать «1» от «7» по визуальным шаблонам, так и алгоритм учится находить закономерности в хаосе данных. Он выделяет главные признаки и игнорирует информационный мусор.
Весь процесс работы можно разделить на 3 логических этапа:
- Входные данные: то, что алгоритм «видит» (в нашем случае — яркость пикселей картинки).
- Обработка (веса и смещения): математические вычисления. Сигналы умножаются на веса (коэффициенты важности) и суммируются.
- Предсказание: итоговый вывод системы (например, классификация: «это цифра 7»).
2. Подготовка инструментов
Чтобы не изобретать велосипед, мы возьмем три классические библиотеки, которые избавят нас от рутинной работы:
- numpy — для мгновенной работы с многомерными массивами (матрицами). Она возьмет на себя всю тяжелую математику под капотом.
- matplotlib — для визуализации графиков и самих изображений.
- sklearn — мы используем её исключительно как хранилище эталонных данных (датасетов).
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
3. Знакомство с данными и подготовка
Чтобы научить сеть мыслить, ей нужно показать примеры. Мы загружаем коллекцию из почти 1800 картинок (размером 8х8 пикселей), где люди от руки написали цифры.
digits = datasets.load_digits()
X = digits.images # Входные данные (картинки)
y = digits.target # Правильные ответы
Преобразование (Flattening)
Компьютер не способен окинуть взглядом квадратную картинку целиком. Нам необходимо «сплющить» двумерную матрицу 8x8 в одну длинную цепочку из 64 чисел (пикселей). Представьте, что мы берем первую строку картинки, а к ней справа последовательно приклеиваем вторую, затем третью и так далее.
Превращаем 1797 картинок 8x8 в 1797 векторов по 64 пикселя
X_flattened = X.reshape(len(X), -1)
Разделение данных (Train/Test Split)
Здесь кроется критическое правило машинного обучения: нельзя тестировать нейросеть на тех же данных, на которых она обучалась. Иначе она их просто вызубрит, потеряв способность к обобщению. Мы отложим 20% данных для финального «экзамена».
X_train, X_test, y_train, y_test = train_test_split(
X_flattened, y, test_size=0.2, random_state=42
)
4. Архитектура нашей сети
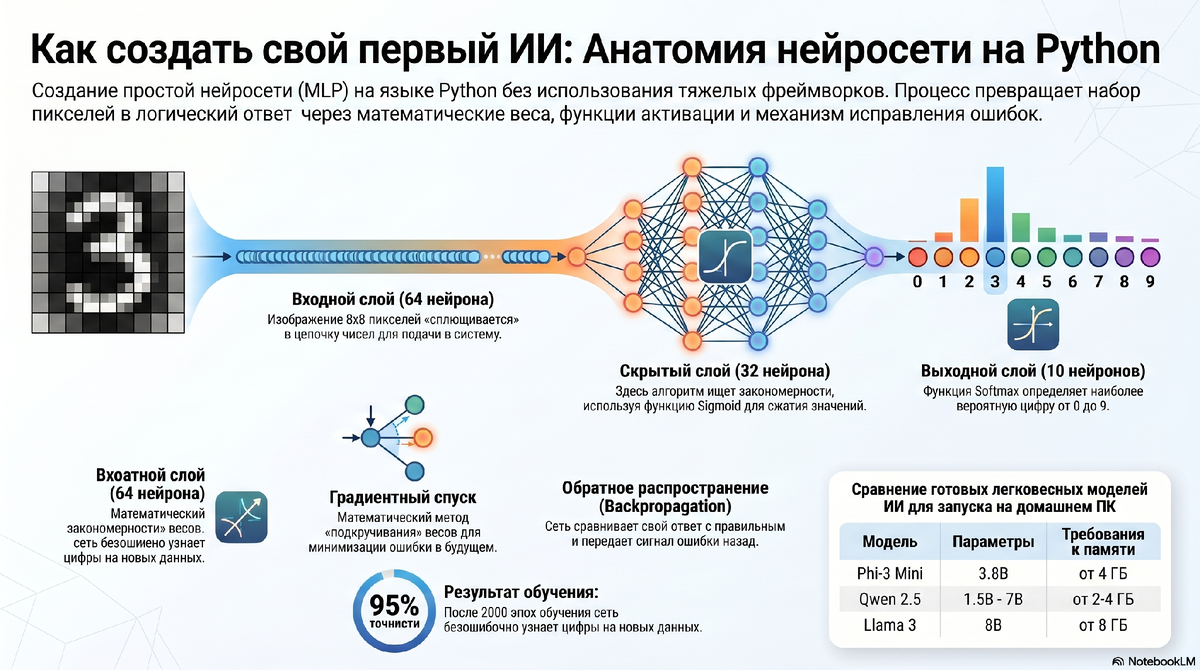
Наша «фабрика решений» будет состоять из трех уровней:
- Входной слой: 64 нейрона-рецептора для приема 64 пикселей изображения.
- Скрытый слой (мы зададим 32 нейрона): Здесь происходит магия абстракции. Ищутся скрытые закономерности — микро-черточки, кружочки, углы.
- Выходной слой: 10 нейронов. Каждый отвечает за цифру от 0 до 9. Нейрон, выдавший самый сильный сигнал, становится победителем.
Связи между слоями регулируются Весами (W) (представьте это как ползунки громкости на микшерном пульте) и Смещениями (b) (внутреннее «настроение» или порог возбуждения нейрона).
5. Прямое распространение и Функции активации
Данные текут слева направо. Для каждого нейрона формула предельно лаконична: «Сигнал = (Вход * Вес) + Смещение».
Но линейного сложения недостаточно. Нам необходима функция активации, которая внесет в систему «нелинейность» (без неё многослойная сеть математически схлопнулась бы в примитивную прямую линию).
Для скрытого слоя мы используем Sigmoid (Сигмоиду). Она элегантно сжимает любое входящее число в диапазон от 0 до 1.
Для выходного слоя применяется Softmax. Она нормирует данные так, чтобы сумма всех вероятностей для 10 цифр равнялась ровно 1 (или 100%).
6. Как сеть осознает ошибки? (Backpropagation)
Представьте: на выходе сеть заявила, что видит «5», а правильный ответ был «8». Система должна осознать масштаб своей ошибки. Разница между предсказанием и реальностью рассчитывается через Функцию потерь (Loss Function).
Вычислив ошибку, сеть отправляет сигнал в обратном направлении — от выхода к входу. Этот завораживающий процесс называется Обратным распространением ошибки (Backpropagation).
Алгоритм вычисляет градиент — математический вектор, указывающий, в какую сторону и насколько сильно нужно подкрутить каждый вес, чтобы минимизировать погрешность. Представьте человека с завязанными глазами, который спускается с горы, нащупывая ногами наибольший уклон вниз. Сам процесс этого пошагового улучшения называется Градиентным спуском.
7. Подготовка ответов: One-Hot Encoding
Нейросеть генерирует 10 вероятностей, а наш правильный ответ — это всего одно число (например, 7). Нам нужно перевести семерку на язык матриц: превратить её в массив из нулей, где под индексом 7 стоит единица:
$$0, 0, 0, 0, 0, 0, 0, 1, 0, 0$$
.
def to_one_hot(y, num_classes=10):
one_hot = np.zeros((len(y), num_classes))
for i in range(len(y)):
one_hot
$$i, y\[i$$
] = 1
return one_hot
y_train_encoded = to_one_hot(y_train)
y_test_encoded = to_one_hot(y_test)
8. Полный рабочий код нейросети
А теперь синтезируем всё воедино. Внимательно изучите комментарии в коде — в этих строках скрыта вся фундаментальная логика машинного интеллекта.
--- Функции активации и их производные ---
def sigmoid(x):
x = np.clip(x, -500, 500) # Защита от переполнения
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return x * (1 - x) # Производная для градиента
def softmax(x):
exps = np.exp(x - np.max(x, axis=1, keepdims=True))
return exps / np.sum(exps, axis=1, keepdims=True)
--- Настройка архитектуры ---
input_size = 64 # 64 пикселя
hidden_size = 32 # 32 нейрона в скрытом слое
output_size = 10 # 10 цифр (от 0 до 9)
Инициализация весов случайными малыми числами
np.random.seed(42)
W1 = np.random.randn(input_size, hidden_size) * 0.1
b1 = np.zeros((1, hidden_size))
W2 = np.random.randn(hidden_size, output_size) * 0.1
b2 = np.zeros((1, output_size))
Гиперпараметры
learning_rate = 0.1 # Шаг градиентного спуска
epochs = 2000 # Количество эпох обучения
m = len(X_train) # Объем выборки
--- Цикл обучения ---
for epoch in range(epochs):
# 1. Прямое распространение (Forward Pass)
Z1 = np.dot(X_train, W1) + b1
A1 = sigmoid(Z1)
Z2 = np.dot(A1, W2) + b2
A2 = softmax(Z2) # Итоговые вероятности
# 2. Оценка потерь (Cross-Entropy Loss)
if epoch % 500 == 0:
loss = -np.sum(y_train_encoded * np.log(A2 + 1e-8)) / m
print(f"Эпоха {epoch}, Ошибка: {loss:.4f}")
# 3. Обратное распространение (Backward Pass)
dZ2 = A2 - y_train_encoded
dW2 = np.dot(A1.T, dZ2) / m
db2 = np.sum(dZ2, axis=0, keepdims=True) / m
dA1 = np.dot(dZ2, W2.T)
dZ1 = dA1 * sigmoid_derivative(A1)
dW1 = np.dot(X_train.T, dZ1) / m
db1 = np.sum(dZ1, axis=0, keepdims=True) / m
# 4. Градиентный спуск (Обновление весов)
W1 -= learning_rate * dW1
b1 -= learning_rate * db1
W2 -= learning_rate * dW2
b2 -= learning_rate * db2
print("Обучение завершено!")
9. Финальный экзамен: Тестирование
Матрицы весов (W) и смещений (b) успешно откалиброваны. Пришло время пропустить через них отложенные тестовые данные X_test. Сеть никогда не видела эти изображения, поэтому сейчас мы проверим её истинную способность к абстрактному мышлению.
Прямой проход для тестовых данных (без обновления весов)
Z1_test = np.dot(X_test, W1) + b1
A1_test = sigmoid(Z1_test)
Z2_test = np.dot(A1_test, W2) + b2
A2_test = softmax(Z2_test)
Выбираем индекс с максимальной вероятностью
predictions = np.argmax(A2_test, axis=1)
Сверяем предсказания с реальностью
accuracy = np.mean(predictions == y_test)
print(f"Точность на тестовых данных: {accuracy * 100:.2f}%")
Результат: Точность составит более 95%. Наша самописная сеть, состоящая из голых математических формул, успешно распознает новые паттерны.
10. Что дальше? Ваш личный ИИ и цифровая свобода
Настоящая магия искусственного интеллекта кроется не в перемножении чисел, а в феномене эмерджентности — когда система учится адаптироваться к реальности через анализ собственных ошибок. Написанная нами архитектура (MLP) — это базис. Сегодня на схожих принципах, но в циклопических масштабах (архитектура Transformer), функционируют Большие Языковые Модели (LLM).
Они пишут код, анализируют данные, философствуют и генерируют искусство. И чтобы прикоснуться к этому, вам больше не нужны дорогие подписки на облачные сервисы. Алгоритмы оптимизированы настолько, что мощный ИИ можно запустить локально — прямо на вашем ПК.
Топ легковесных LLM, которые потянет домашний компьютер:
- Phi-3 Mini (от Microsoft): Требует всего от 4 ГБ ОЗУ. Обладает феноменальной логикой при крошечном размере. Идеальна для слабых ноутбуков.
- Qwen 2.5 (от Alibaba): Модели от 1.5B до 7B параметров (нужно 2-4 ГБ памяти). Превосходно понимает русский язык и структуру программного кода.
- Gemma 2 (от Google): От 3 до 8 ГБ памяти. Высокоэффективная архитектура от самих создателей технологии Трансформеров.
- Llama 3 (от Meta): Требует от 8 ГБ ОЗУ. Признанный золотой стандарт открытых моделей с глубочайшей эрудицией.
- Mistral: Требует от 8 ГБ ОЗУ. Французская модель, обеспечивающая идеальный баланс между креативностью и вычислительной легкостью.
Итог: Убежище цифрового разума
Мы прошли путь от сухих формул до создания собственной мыслящей сети. Мы заглянули под капот ИИ и убедились, что там скрывается не мистика, а строгая, постижимая гармония математики.
Но что если сделать следующий шаг? Сегодня транснациональные корпорации монополизируют вычислительные мощности. Они превращают доступ к когнитивным инструментам в привилегию, навязывая цензуру и платные подписки. Однако истинная свобода мысли в XXI веке кроется в децентрализации. Что если ваш личный компьютер может стать убежищем для автономного цифрового разума?
В следующей статье мы развеем туман над процессом локального деплоя ИИ. Я пошагово покажу, как совершенно бесплатно развернуть собственную LLM-модель (из списка выше) на вашем железе. Без навыков DevOps, без дорогих видеокарт и без подключения к интернету. Мы создадим ваш личный, суверенный оазис искусственного интеллекта.
Подписывайтесь на канал, чтобы не пропустить этот шаг к цифровой независимости. А пока — делитесь в комментариях: пробовали ли вы уже писать код для нейросетей своими руками, или предпочитаете использовать готовые ИИ (ChatGPT, Midjourney)? Расскажите о своем опыте!