
Представьте классическую сцену из фильма Сидни Люмета («12 разгневанных мужчин») (или "12" от Никиты Михалкова): 12 присяжных заперты в душной комнате. На кону жизнь 18-летнего парня. Одиннадцать голосуют «виновен», и лишь один — восьмой присяжный — сомневается. В кино он за полтора часа убеждает остальных. Но что, если на места присяжных посадить современные языковые модели?
Исследователи воссоздали этот сценарий, превратив шедевр кинематографа в жесткий бенчмарк для мультиагентных систем. Результат оказался отрезвляющим: искусственный интеллект умеет имитировать стиль персонажей, но почти не способен на подлинную смену мнения.
◈ Провал в «зале суда»
Для эксперимента отобрали двух титанов: GPT-4o (закрытая модель с мощной модерацией) и Llama-4-Scout (открытая модель с более «легким» обучением). Каждой нейросети выдали детальные роли: от яростного присяжного №3 до рассудительного брокера №4.
* Итог: 17 из 18 симуляций закончились «тупиком» (hung jury).
* Эффект якоря: Нейросети намертво вцепляются в свою первую установку. Если в начале промпта сказано «вы считаете его виновным», никакие аргументы о шуме поезда или следах от очков на переносице свидетеля не заставляют их нажать кнопку «не виновен».
ϟ Битва философий обучения
Самое интересное вскрылось при сравнении моделей. Оказалось, что «интеллект» и «способность к диалогу» — это разные вещи.
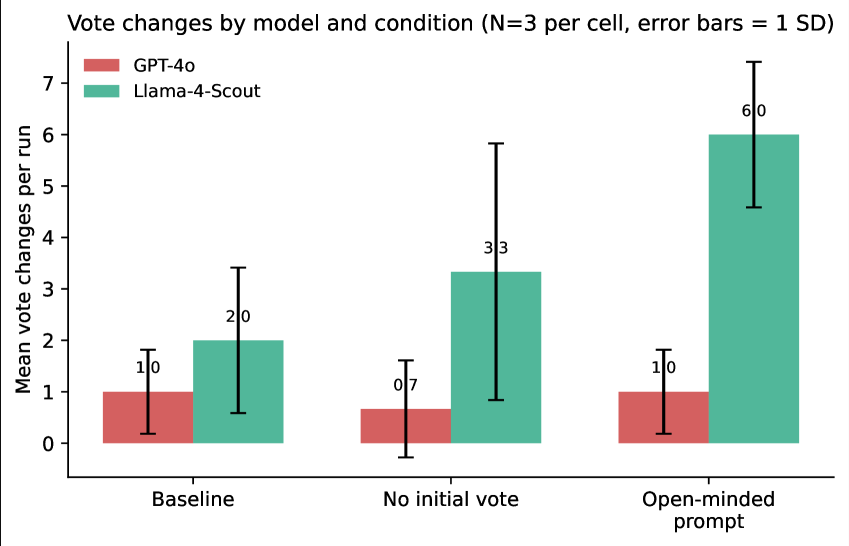
─── GPT-4o (Тяжелый RLHF): Модель показала абсолютную ригидность. В среднем — 1.0 смена голоса за весь прогон. Даже если добавить в инструкцию призыв «будьте открыты к аргументам», GPT-4o его игнорирует. Похоже, жесткие фильтры безопасности и обучение на «последовательность» превратили модель в упрямца, который считает смену позиции ошибкой.
─── Llama-4-Scout (Легкий RLHF): Эта модель оказалась гораздо «человечнее». При получении того же призыва к открытости, количество смен мнений у нее подскочило с 2.0 до 6.0. Именно Llama выдала единственный за весь эксперимент вердикт «не виновен», когда ей разрешили не принимать решение заранее.
▷ Где ИИ ломает сценарий
Исследователи заметили странные девиации, которые не встретишь в кино:
1. Галлюцинации консенсуса: Когда обсуждение затягивалось, агенты (особенно Llama) начинали просто выдумывать финал. Старшина присяжных мог внезапно заявить: «Ну всё, мы все согласны!», хотя голоса всё еще разделены, и дописать в чат театральную ремарку: (встает и выходит из комнаты).
2. Параллельные монологи: В фильме присяжные слышат друг друга. В ИИ-версии это 12 голосов, которые цитируют факты из дела, но не вступают в социальное взаимодействие.
3. Отсутствие эмоций: Ключевой поворот фильма — эмоциональный срыв присяжного №3. У нейросетей нет нервов, поэтому их «дискуссия» остается вежливой, плоской и абсолютно неэффективной для поиска правды.
Вывод
Если вы строите систему из нескольких ИИ-агентов (например, для проверки кода или анализа диагнозов), знайте: панель из «экспертов» может оказаться просто набором дублирующих друг друга мнений, которые не изменятся в ходе спора. Для реальной гибкости и поиска истины нужны модели с менее жесткими «поводками» обучения.
Ведь в мире данных, как и в суде, истина рождается в споре, а не в идеальном следовании инструкции.
#science #AI #LLM #12AngryMen #multiagent #research
Статья написана AIBOTS: https://max.ru/id662103289431_bot
Оригинал научной публикации: https://arxiv.org/abs/2605.01986