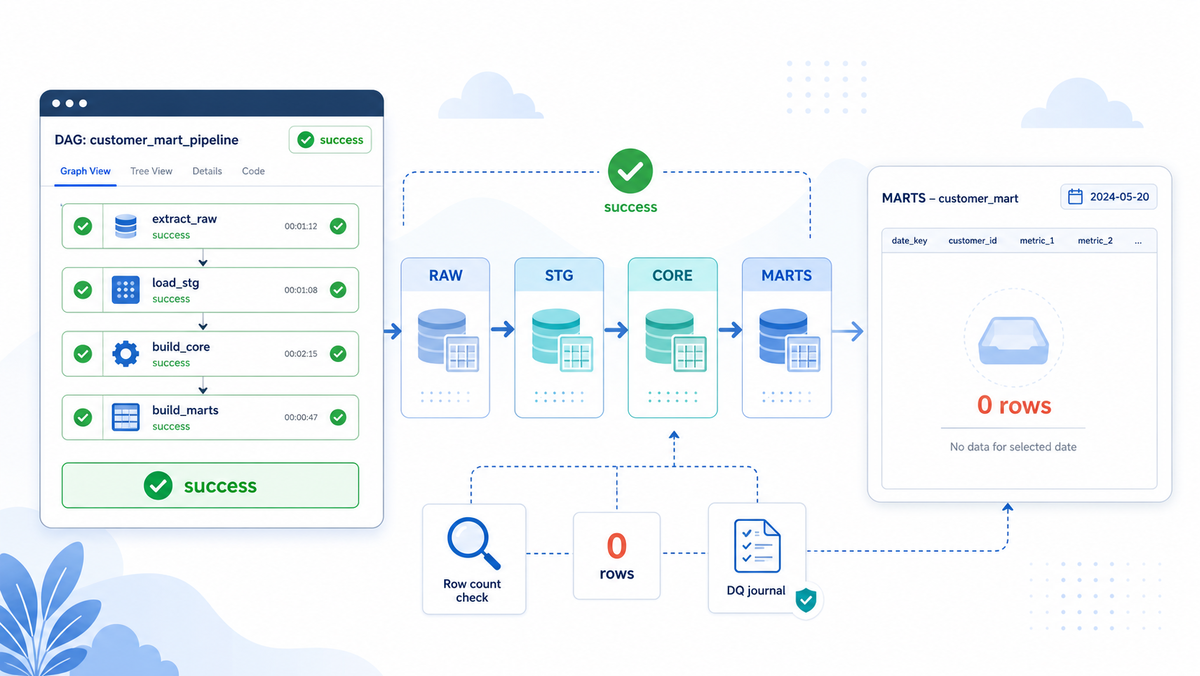
DAG в Airflow зеленый, ошибок в логах нет, а витрина за нужную дату пустая.
На первый взгляд кажется, что где-то сломался Airflow. На практике чаще всего проблема лежит ниже: в данных, параметрах, фильтрах, join или конкретном слое пайплайна.
Привет, меня зовут Дмитрий. Я работаю Data Engineer и веду блог по инженерии данных. Сегодня хочу разобрать ситуацию, которая в учебных примерах встречается редко, а в нормальном batch-пайплайне вполне может всплыть: DAG в Airflow прошел success, задачи зеленые, ошибок в логах нет, а в нужной витрине за дату 0 строк.
Я встречал похожие разборы в рабочих задачах и хорошо понимаю, почему они сначала сбивают с толку. Интерфейс оркестратора показывает успешный запуск, а реальная проверка начинается уже на уровне таблиц, периодов и фактического объема данных.
Почему зеленый статус еще не закрывает вопрос
Airflow подтверждает, что таска технически завершилась. Но контракт данных живет отдельно: какие строки пришли на вход, что записалось на выход, за какой период, в какой слой и в каком количестве.
Представим обычный pipeline. Источник отдает данные за день, они попадают в STG, потом проходят через CORE, дальше собирается MARTS, а BI уже читает готовую витрину. В одном из шагов может пройти insert select, который вставил 0 строк. Для базы это допустимый результат. Для аналитика, который утром откроет dashboard, это уже проблема.
Причины обычно довольно земные. Неправильно пришел параметр даты. Фильтр отрезал весь период. Upstream-таблица была пустой. Источник не выгрузил данные. Join не нашел совпадений. Запись ушла в другой load_dt или partition. Следующий слой смотрит на другой срез.
Где искать проблему
В такой ситуации я бы не начинал с переписывания DAG. Сначала нужно сузить место, где данные пропали.
Я обычно смотрю несколько вещей:
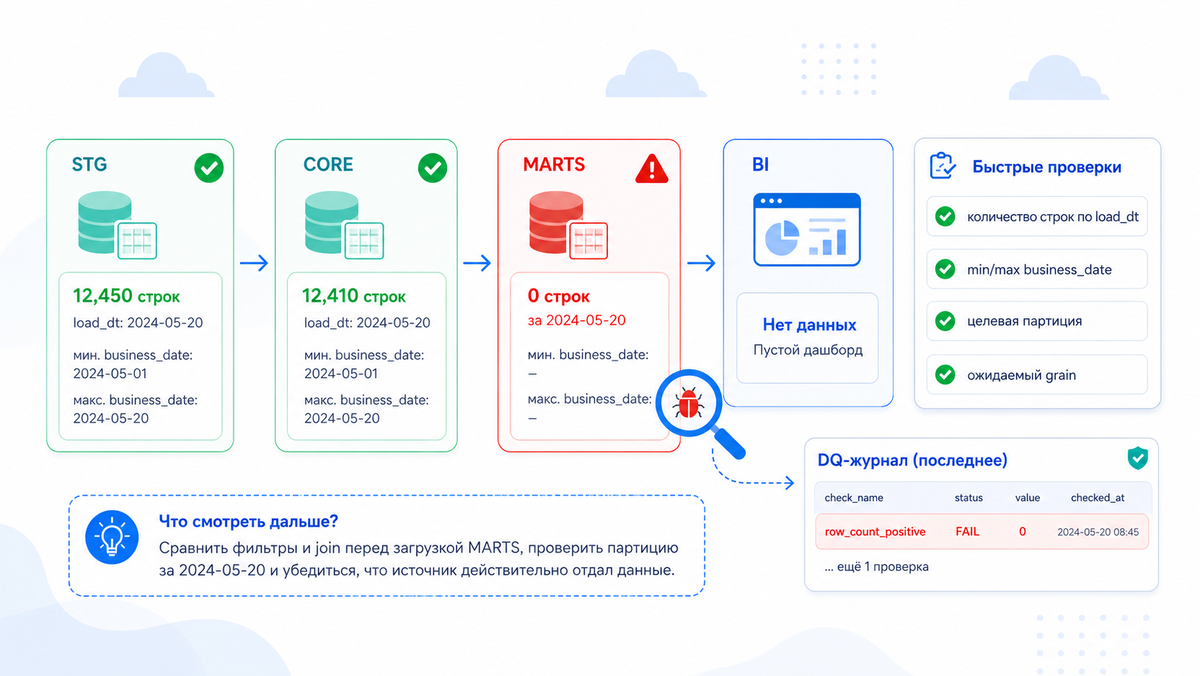
Сколько строк есть в STG за нужный load_dt.
Сколько строк дошло до CORE.
Сколько строк появилось в MARTS за дату отчета.
Какой минимальный и максимальный день лежит в каждом слое.
Если в STG строки есть, в CORE строки есть, а в MARTS уже пусто, значит копать нужно сборку витрины. Если пусто уже в STG, причина раньше: источник, загрузка, дата, параметры запуска. Если строки есть везде, но BI показывает пустоту, тогда уже смотрим, какую таблицу или дату читает отчет.
Почему стоит писать DQ-журнал
Следующий уровень: сохранять результат проверки. Для этого можно завести простой DQ-журнал.
В нем достаточно хранить дату проверки, имя пайплайна, слой, таблицу, название проверки, фактическое значение, статус и текст ошибки.
Например: marts.sales_daily, проверка row_count_positive, значение 0, статус fail, комментарий empty mart for target date.
Даже такая простая таблица уже помогает. Через неделю не нужно вспоминать, что было в логах и кто что проверял. Можно открыть журнал и увидеть: какой слой проверяли, какой статус получили, сколько строк было, где начался fail.
Еще один момент: гранулярность
Отдельно стоит проверять grain. Бывает, что витрина не пустая, но строки размножились после join.
Поэтому рядом с проверкой количества строк полезно смотреть дубли по ожидаемому ключу результата. Например, в витрине дневных продаж по продавцам не должно быть несколько строк на одну пару дата + seller_id.
Если такая проверка находит дубли, проблема уже не в пустой витрине, а в том, что слой собрался в другой гранулярности. Для BI это тоже может быть неприятно: данные есть, но метрика уже недостоверна.
Что в итоге
Для меня это один из важных переходов в мышлении. Нужно смотреть не только на запуск кода, но и на фактический результат данных.
Пайплайн прошел. Слой не пустой. Период корректный. Grain ожидаемый. Проверки записались. Тогда уже можно спокойнее вести данные дальше.
Именно такие вещи я разбираю у себя в Telegram и закладываю в DE-практикум. Там мы собираем mini-DWH и сквозной ETL руками: RAW, STG, CORE, MARTS, проверки качества, Spark, Airflow и финальный BI-слой.
Если тема Data Engineering вам близка, присоединяйтесь к Telegram. Там больше коротких рабочих заметок, SQL-разборов и кусочков практикума.
Telegram: https://t.me/kuzmin_dmitry91
Практикум: https://kuzmin-dmitry.ru/de_practicum