Почему возникает перерасход токенов
Перед обработкой текста модель разбивает его на токены - минимальные смысловые единицы, которыми могут быть целые слова, части слов или даже отдельные символы. Большинство современных LLM (GPT, Claude и другие) используют алгоритм токенизации Byte Pair Encoding (BPE), который строит свой словарь на основе частотности сочетаний символов в обучающих данных. Поскольку основная часть этих данных представлена на английском языке, токенизатор оптимизирован под латиницу и относительно простую английскую морфологию. В результате распространённые английские слова и их части часто кодируются одним токеном. Для языков с более сложной морфологией, например русского, и другой системой письменности токенизатор вынужден дробить текст на более мелкие и частые фрагменты, что увеличивает общее число токенов при передаче того же смысла.
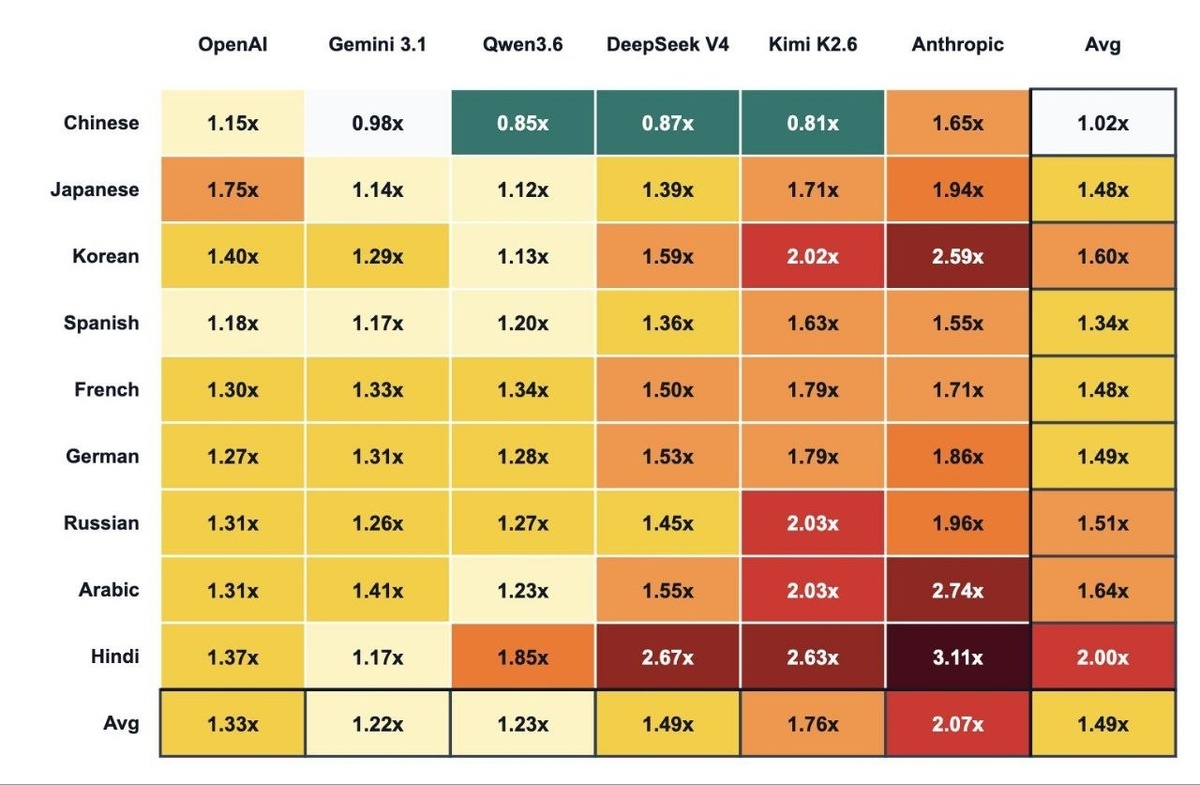
Таблица перерасхода токенов по языкам
Коэффициент перерасхода показывает, во сколько раз больше токенов требуется по сравнению с английским языком, коэффициент которого принят за 1.0. Значение зависит от модели и контекста, но можно выделить усреднённые показатели, основанные на данных из открытых источников.
- Английский — 1.0x (базовый уровень, самое эффективное использование токенов)
- Испанский — 1.2x–1.5x
- Французский — 1.2x–1.48x
- Немецкий — 1.27x–1.49x
- Китайский — 1.15x–2.0x (сильно зависит от модели; в некоторых, например Qwen, может быть даже меньше 1.0, в других, как Anthropic, до 1.71x и выше)
- Русский — ~1.5x (диапазон по разным оценкам: 1.31x–2.5x)
- Японский — 1.48x–2.12x
- Корейский — 1.6x–2.36x
- Хинди — 2.0x–5.0x
- Греческий — до 6.0x
Что означает коэффициент 1.5 для русского языка
Коэффициент 1.5 означает, что одна и та же по смыслу информация на русском языке обойдётся в среднем в 1.5 раза дороже, чем на английском. Это приводит к трём основным последствиям.
- Прямые финансовые расходы. Вы платите за каждый токен, и при больших объёмах сумма может быть заметной, на дорогих API.
- Сжатие полезного контекста. Контекстное окно модели ограничено по числу токенов. Русски текст занимает больше места, поэтому в окне помещается меньше истории диалога, инструкций или документов. Модель быстрее теряет из виду начало обсуждения.
Это приводит к снижение качества ответов. Нехватка контекста может привести к тому, что модель упустит важные детали, что напрямую сказывается на релевантности и полноте её ответов.
Что с этим делать
Существует несколько стратегий для снижения токенизационных потерь при работе с русскоязычным контентом.
- Стратегия «Английский как мост». Русский запрос переводится на английский через отдельный сервис (Google Translate, DeepL), отправляется в LLM, затем ответ переводится обратно. Это может сократить расход токенов на 30–50% за счёт более эффективного английского токенизатора. Недостатки: растёт задержка и добавляется стоимость перевода, поэтому выгоду нужно считать в каждом конкретном случае.
- Транслитерация. Запись русского текста латиницей (например, «Ya vstretil ogromnuyu sobaku» вместо «Я встретил огромную собаку»). Исследования показывают, что это может почти вдвое сократить число токенов. Недостаток: большинство моделей всё же лучше понимают стандартную кириллицу, что может ухудшить качество ответов.
Подобный метод может иметь положительный эффект на слабых локальных моделях. - Использование оптимизированных моделей. Выбор моделей, чьи токенизаторы изначально лучше адаптированы под русский язык. По данным тестов, более высокую эффективность для русского показывают YandexGPT, GigaChat и некоторые версии Qwen. В отдельных случаях адаптация токенизатора способна ускорить обработку до 60%.