Финальная часть серии: субагенты, worktrees, GitHub Actions, TDD, Ralph-loop и почему человек становится главным узким местом разработки
Серия на Дзене: часть 1 - что Claude Code умеет из коробки · часть 2 - настройки, хуки и Context Rot · часть 3 - автономная работа и параллелизм.
Однажды вечером я дал Claude Code не задачу "сделай фичу", а уже написанную спеку и сложный план. Дальше работал не один чат. Оркестратор разобрал план на независимые куски, поднял кодеров в отдельных worktree, дождался diff'ов, вызвал ревьюеров и собрал итоговый отчёт.
Утром у меня был не "ответ ассистента", а несколько веток, замечания ревью и список решений, которые всё равно должен принять человек.
Это третья и финальная часть серии. В первой я показывал Claude Code как терминального агента, а не автокомплит. Во второй разбирал настройки: CLAUDE.md, permissions, хуки, "совещание ботиков" через Codex и Gemini, Context Rot.
Теперь следующий уровень: не один умный чат, а система из агентов, рабочих деревьев, автоматических проверок и фоновых циклов.
1. Субагенты: не role prompt, а полноценная спека
Субагент в Claude Code - это отдельный профиль со своим контекстом, инструментами и инструкцией. Его можно вызвать из основной сессии, получить результат и продолжить работу, не забивая главный контекст деталями.
Главная ошибка - думать что агент это 15 строк в стиле "ты опытный ревьюер". Нет. Нормальный агент похож на внутреннюю инструкцию сотруднику: кто он, за что отвечает, какие входные данные получает, что должен вернуть, что запрещено, где стоп-критерий.
---
name: seeker
description: Finds evidence-backed niche opportunities from a founder profile
tools: Read, Grep, Glob, WebFetch
model: opus
permissionMode: plan
maxTurns: 40
effort: high
---
# Agent: SEEKER
## Who You Are
You find real niches - places where someone's already paying
for a bad solution, quietly.
## The Product You're Part Of
You are step one of a six-step pipeline.
## Input You Receive
## Revenue Calibration
## WebSearch Protocol
## Output Contract
## Rejection Rules
Это сокращённый верх реального агента. Полный файл у меня занимает сотни строк. И это нормально. Чем автономнее агент, тем меньше он должен быть похож на промпт из ChatGPT.
Находка. Агент без подробной спеки быстро превращается в "умного помощника вообще обо всём". А такой помощник красиво ошибается, уверенно нарушает архитектуру и потом просит похвалить его за прогресс.
2. Agent Teams: оркестратор, кодеры и ревьюеры
Agent Teams - экспериментальный режим Claude Code, где несколько сессий работают как команда. Один lead-agent держит общий план, остальные агенты выполняют куски работы в своих контекстах.
Но это работает только если у тебя уже есть нормальная спека. Не "сделай красиво", а документ: цель, инварианты, какие модули можно трогать, какие нельзя, критерий готовности, rollback.
Мой рабочий шаблон выглядит так:
- Оркестратор читает спеку и режет работу на независимые юниты
- Каждый юнит получает отдельный кодер-агент со своей инструкцией
- Кодеры работают в отдельных worktree и возвращают diff, тесты и риски
- Оркестратор вызывает ревьюеров: security, tests, architecture, domain-specific
- После ревью собирается итог: что мержить, что переделать, где нужен ручной выбор
Качество держится не на количестве агентов. Качество держится на хороших specs. Кодер без правил проекта будет ломать архитектуру. Ревьюер без чеклиста будет писать банальности. Оркестратор без exit criteria будет гонять команду по кругу.
3. Worktrees: чтобы агенты не дрались за одну папку
Git worktree - это отдельная копия рабочего дерева, привязанная к своей ветке. Для AI-агентов это критично: каждый Claude работает в своей директории, со своим diff и своей веткой.
# Основной проект
cd ~/work/myapp
# Отдельная ветка для фичи
claude --worktree feature-a
# Отдельная ветка для багфикса
claude --worktree bugfix-b
Это не отменяет merge conflict при финальном слиянии, если два агента поменяли одни и те же строки. Но исчезает главный хаос: несколько сессий больше не перетирают одну рабочую директорию.
Важная мелочь: worktree - чистый checkout. Файлы вроде .env.local и локальных dev-конфигов туда сами не попадут. Для этого есть .worktreeinclude:
.env.local
config/dev.json
certs/local/*.pem
Секреты всё равно не коммитятся, но ночной агент не падает через минуту с "missing config".
4. Headless mode, расписание и GitHub Actions
Claude Code можно запускать не только в интерактивном терминале. Через claude -p он работает как обычная CLI-команда: получил промпт, сделал задачу, вернул результат.
claude -p "Analyze git log for the last week
and write a weekly report into CHANGELOG.md"
Это открывает скучные, но полезные сценарии: ежедневный отчёт по коммитам, ночная генерация changelog, проверка зависимостей, ревью старых PR. Через /loop можно запускать polling внутри живой сессии. Через /schedule - durable routine, которая переживает закрытый терминал.
Отдельная история - официальный GitHub Action anthropics/claude-code-action@v1. Он позволяет запускать Claude внутри workflow: ревью PR, реакция на комментарий @claude, генерация тестов, release notes.
Я бы не начинал с полного автопилота. Сначала включи readonly-review: Claude смотрит PR и пишет комментарии. Потом уже давай ему права править код.
5. Multi-file рефакторинг: сначала план, потом код
Самый дорогой способ использовать AI - кинуть ему "порефактори модуль" и ждать чуда. Он начинает править первый найденный файл, потом второй, потом на пятом оказывается что в третьем нужно было другое решение.
Нормальный workflow:
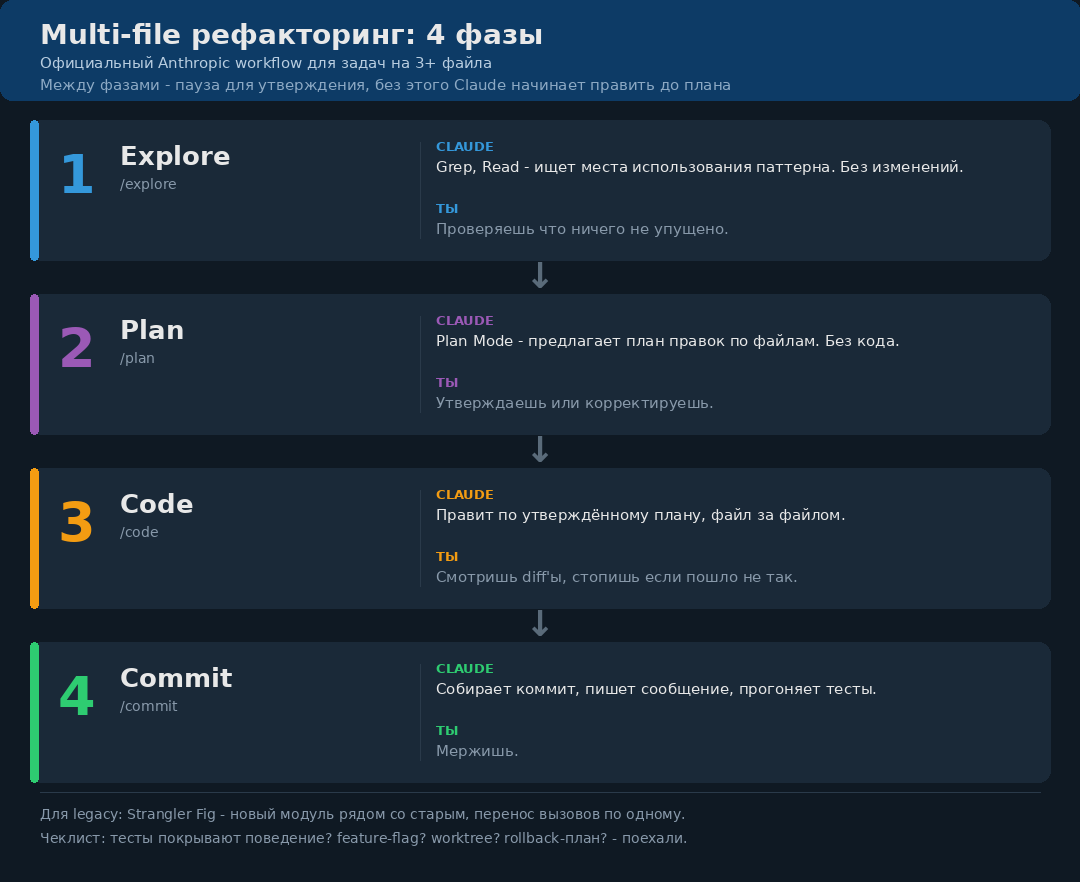
Если хочется не собирать процесс руками, посмотри Get Shit Done. Это open-source система для spec-driven development поверх Claude Code и других CLI-агентов. Самое полезное там не название, а дисциплина: свежий контекст на каждую задачу, атомарные коммиты, параллельные волны выполнения, отдельный verify-шаг.
Для legacy-кода отдельно полезен паттерн Strangler Fig: старый модуль не переписываешь одним взрывом, а строишь новый рядом и постепенно переводишь вызовы.
6. TDD на автопилоте
Claude умеет писать тесты. Проблема в том, что если попросить "напиши функцию и тесты", он часто пишет тесты под свою же реализацию. Всё зелёное. Только пользы мало.
Лучше разделять фазы:
# 1. RED
Write failing tests for validateEmail().
Do NOT write implementation.
# 2. GREEN
Now implement validateEmail() so tests pass.
Do the minimum.
# 3. REFACTOR
Refactor for readability.
Tests must keep passing.
Для старого кода без тестов сначала нужны характеризационные тесты: они фиксируют текущее поведение. Не желаемое, а текущее. Даже если оно странное. И только потом рефакторинг.
В бенчмарке Diffblue от 24 марта 2026 их Testing Agent на 8 Java-проектах дал 81% line coverage и 61% mutation coverage, а senior-разработчик с Claude Code за два часа - 32% и 24%. Это не значит что Claude "плохой". Это значит что тесты без orchestration быстро упираются в потолок.
7. Ralph-loop: пока не пройдёт проверка
Ralph - это простой приём: запускать Claude в цикле, пока внешняя проверка не скажет "готово". Например: тесты прошли, билд собрался, lint чистый, скриншот совпал с эталоном.
while task_not_done; do
claude -p "Take the next step.
Update state.md with what changed,
what failed and what to try next."
run_check || continue
done
Geoffrey Huntley описывал Ralph как способ снова и снова отдавать агенту задачу, пока проект не сойдётся. В его разборе Ralph использовался для сборки языка программирования CURSED. Есть и field report RepoMirror с YC Agents hackathon: 1 000+ коммитов, несколько портированных кодовых баз и счёт меньше $800 на inference.
Но тут важна защита. Если критерий готовности - "проходят ли тесты", а Claude имеет право менять тесты, он может начать подгонять тесты под код. Критерий должен быть вне-контекстным: компиляция, внешний валидатор, screenshot test, e2e-проверка.
8. Что останется человеку
Вся серия началась с мысли: человек стал узким местом разработки. Не модели, не лимиты, не инструменты. Человек, его внимание и способность удерживать контекст.
К 2027 Claude Code, скорее всего, будет всё меньше похож на инструмент, который ты запускаешь руками. KAIROS, autoDream, Ultraplan и scheduled tasks складываются в одну картину: агент работает фоном, планирует в облаке, консолидирует память между сессиями и утром приносит PR на утверждение.

Отдельно тревожит траектория роста джунов. Раньше ты учился через боль: опечатки, кривые циклы, забытые скобки, долгий дебаг. Сейчас AI пишет за джуна с первого раза, а интуиция не формируется. Зато легко формируется привычка не думать над тем, что выходит из AI.
Я начинал с AI на GPT-3.5, когда это было смешно. Видел весь путь от "может написать пару строк" до "может вести кусок проекта". Моя ставка простая: разработчик будущего - это человек, который понимает бизнес на уровне владельца, систему на уровне архитектора, и AI на уровне инструментальщика.
Не меньше работы. Другая работа.
Итог серии
Первая часть была про то, почему Claude Code - не автокомплит. Вторая - про настройки, без которых он остаётся дорогой игрушкой. Эта часть - про параллелизм и автономность.
Мой текущий setup: несколько активных проектов, 1-2 сессии Claude на каждый, worktree-параллельные агенты на рефакторинги, Ralph-loop на бэкграундный проект, scheduled tasks на триаж PR. Один человек держит объём, который раньше требовал отдельной маленькой команды.
Узкое место - не AI. Узкое место - ты, пока не научился им управлять.
Первые две части серии:
Часть 1: 10 фичей Claude Code, которые превратили одного разработчика в команду из 15 человек
Часть 2: 10 настроек Claude Code, до которых большинство разработчиков не доходит
Источники и ссылки по теме:
Claude Code: subagents · Claude Code: Agent Teams · Get Shit Done · Git worktree manual · Martin Fowler: Strangler Fig · Diffblue Testing Agent Benchmark · Geoffrey Huntley: Ralph Technique · RepoMirror Ralph Field Report
Об авторе: Кир, CTO и серийный предприниматель. Пишу про AI-инструменты, автоматизацию разработки и реальные интеграции в бизнесе. Telegram: @ai_integr.