Spotify почти всегда играет у меня на фоне, пока я работаю за компьютером. Оказывается, у сервиса есть открытые музыкальные данные для анализа — и меня не отпускал вопрос: есть ли у суперхитов что-то общее? Я решил проверить это и попытаться собрать модель идеального трека на основе реальных данных Spotify.
Как я собирал данные
Спасибо, Kaggle!
Чтобы искать закономерности в музыке, сначала нужно найти подходящий датасет. Конечно, Spotify даёт API для разработчиков: можно завести себе учётку и выгружать любимую музыку хоть сутками, но многие уже сделали это за нас и выложили огромные подборки на Kaggle.
Я скачал набор данных от Joakim Arvidsson — там собраны сведения о более чем 30 000 популярных треках. Для скачивания использовал утилиту Kaggle — удобно и быстро.
Анализ начал в Jupyter Notebook — результаты можно найти у меня на GitHub.
Дальше импортировал любимые библиотеки для статистики на Python:
Подключил NumPy для численных расчётов и линейной алгебры, pandas для работы с таблицами, Seaborn для красивых графиков. Функция sns.set_theme() задаёт стиль визуализации. "%matplotlib inline" делает так, чтобы графики сразу появлялись в тетрадке, а не в отдельном окне. Ещё подгружается Matplotlib для дополнительных визуализаций. statsmodels и его формульный API пригодятся для построения моделей. Плюс — несколько статистических функций из SciPy.
Пора загружать скачанную таблицу в pandas DataFrame:
Заглядываем внутрь данных
Что скрыто в датасете?
После загрузки я первым делом решил посмотреть на структуру таблицы — пробежаться по первым строкам и узнать, какие колонки вообще есть:
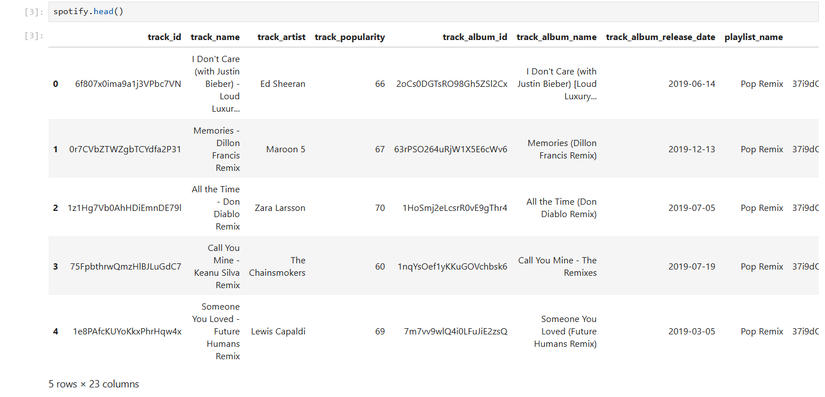
Что значат эти названия? На Kaggle есть подробное описание: "track_id" — уникальный номер трека, "track_title", "track_artist", "playlist_name", "playlist_genre" — всё понятно. А вот за "Acousticness" скрывается доля акустических инструментов (например, гитары), “Danceability” — насколько трек танцевальный, “Loudness” — просто о громкости, “Instrumentalness” — присутствует ли вокал, “Liveness” — есть ли эффект живого выступления (включая шум зала), “Energy” — насколько трек заряжен энергией, “Speechiness” — сколько речи внутри композиции, “Valence” — насколько трек звучит солнечно или хмуро.
Давайте взглянем на сводную статистику — для этого достаточно метода "describe":
Пара кликов — и перед нами количество треков, среднее, медиана, стандартное отклонение, минимальные и максимальные значения, а также квартильные разбивки. Видно, что масштаб данных впечатляет!
Теперь интересно оценить, как распределены параметры. Чтобы построить гистограммы сразу по всем числовым столбцам, достаточно одной строки кода — pandas тут рулит:
Меня сразу удивило: у многих показателей распределения сильно смещены! Например, у большинства треков популярность нулевая — на графике это ярко видно по огромной колонке с левого края.
Модель суперуспеха: что главное?
Из чего склеен хит?
Когда базу разобрал, пришло время выяснить, какие черты делают трек популярным. Для первого анализа я применил обычную МНК-регрессию (OLS) через statsmodels, используя формульный интерфейс.
И уже первый график предупредил меня: из-за мультиколлинеарности (слишком сильных связей между параметрами) результаты могут быть не супер-точными.
Поэтому я применил регуляризованную регрессию — модель, которая «карает» слишком влияющие параметры:
В итогах не будет подробной таблицы, но параметр params показывает, где коэффициенты положительные, а где отрицательные. Это сразу говорит — что реально помогает композиции взлететь, а что, наоборот, мешает.
Выводы такие:
Хуже всего на успех влияют высокая энергия, большое количество проговорённого текста и преобладание инструментальных композиций. Зато топовый хит чаще всего — танцевальный, громкий и с позитивным настроением (“valence”). Если ваша гитара «завела» весь вечер на квартирнике — самое время отправлять эту запись на лейблы! А вот если пока пишете только инструменталы, бросать всё ради шоу-бизнеса ещё не стоит.
Проверяю, как играет роль жанр
Какие жанры чаще взлетают?
Мне стало любопытно: а жанр плейлиста действительно влияет на шансы трека взлететь? Для этого я провёл дисперсионный анализ (ANOVA). Для большей наглядности построил boxplot (ящик с усами) популярности по жанрам:
График моментально показывает: между жанрами реально огромная разница по популярности! Я построил линейную модель, учитывая жанр как отдельную категорию:
Подпишитесь на самые свежие открытия о музыке и данных!
Дальше прогнал модель через anova_lm.
Микроскопическое p-value — железный аргумент в пользу того, что жанр напрямую влияет на популярность. Для яркости дополнил диаграммой популярности по жанрам:
Хотите попасть в топ? Ловите волну — выбирайте латинские или поп-плейлисты: чаще всего именно там появляются новые хиты.
Сможете угадать следующий хит?
Да, музыкальные вкусы у всех разные, но крупные тренды реально уловить: люди тянутся к определённым сочетаниям жанров и настроений. Конечно, свести искусство к чистой математике невозможно… Но как же захватывающе взглянуть на любимую музыку через призму цифр и кода!
Spotify
Если вам понравилась эта статья, подпишитесь, чтобы не пропустить еще много полезных статей!
Премиум подписка - это доступ к эксклюзивным материалам, чтение канала без рекламы, возможность предлагать темы для статей и даже заказывать индивидуальные обзоры/исследования по своим запросам!Подробнее о том, какие преимущества вы получите с премиум подпиской, можно узнать здесь
Также подписывайтесь на нас в:
- Telegram: https://t.me/gergenshin
- Youtube: https://www.youtube.com/@gergenshin
- Яндекс Дзен: https://dzen.ru/gergen
- Официальный сайт: https://www-genshin.ru