
💽 СЛУШАТЬ ПОДКАСТ: ССЫЛКА
В 2026 году индустрия локального искусственного интеллекта столкнулась со «стеной памяти». Гигантские нейросети сместили фокус с вычислительной мощности чипов на объем и скорость памяти. В ответ на это сформировались два противоположных лагеря: парадигма «Скорости» (RTX 5090) и парадигма «Объема» (DGX Spark).
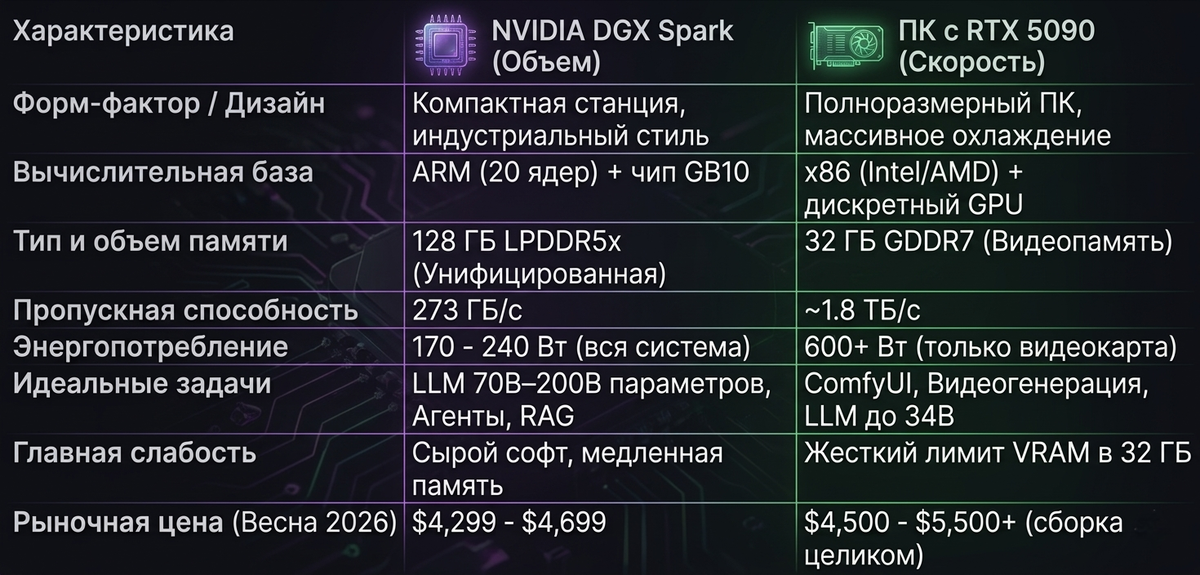
📊 Битва за локальный ИИ
Ниже представлено концептуальное сравнение обеих систем, отражающее их сильные и слабые стороны в реальных рабочих процессах.
1. NVIDIA DGX Spark: Укротитель гигантов
Изначально известная как Project DIGITS, эта микро-станция объединяет 20-ядерный ARM-процессор и GPU архитектуры Blackwell (GB10) с 128 ГБ унифицированной памяти.
Преимущества:
- Беспрецедентный объем: Позволяет локально запускать гигантские модели (например, GPT-OSS-120B или Qwen 3.5 122B) без использования облака.
- Стабильный инференс: Благодаря NVLink-C2C, CPU и GPU делят память напрямую. На тяжелых моделях система выдает стабильные 40–60 токенов/с, что идеально для мультиагентных систем.
Недостатки (Программный кризис):
- Микроархитектура SM121: Выяснилось, что чип GB10 лишен тензорных инструкций tcgen05 (присутствующих в серверных Blackwell). Из-за этого фреймворки вроде Triton и vLLM изначально работали нестабильно, откатываясь к старым алгоритмам.
- Энтузиастам пришлось создавать платформу Spark Arena для стандартизации патчей и оптимизации запуска моделей.
2. RTX 5090: Абсолютная скорость генерации
Классический подход с использованием флагманской дискретной видеокарты, обладающей феноменальной пропускной способностью памяти ~1.8 ТБ/с.
Преимущества:
- Доминирование в графике: В задачах диффузии (генерация картинок и видео) огромная пропускная способность позволяет моментально декодировать данные.
- Мгновенный отклик LLM: Если модель (до ~34B параметров) влезает в 32 ГБ VRAM, RTX 5090 генерирует сотни токенов в секунду, оставляя DGX Spark далеко позади.
Недостатки:
- Как только модель (например, 70B+) требует выгрузки части слоев в системную DDR5-память через узкую шину PCIe, скорость генерации падает до нерабочих 1-2 токенов в секунду.
3. Сравнительный бенчмаркинг
Прямое сравнение показывает, что выбор платформы строго зависит от типа нейросети.
4. Конкуренты: Mac Studio и AMD Strix Halo
- Mac Studio (M3/M4 Ultra): Предлагает до 512 ГБ памяти со скоростью 819 ГБ/с. Отлично генерирует токены, но проигрывает Spark в скорости обработки длинных промптов (Prefill) почти в 3.8 раза и не поддерживает CUDA.
- AMD Strix Halo (AI395): Бюджетная альтернатива на x86 со 128 ГБ памяти. Позволяет запустить 122B модели со скоростью ~20 токенов/с, но страдает от нестабильности графического API (Vulkan/ROCm) при пиковых нагрузках.
5. Экономика рынка и кризис памяти (2026)
Выбор оборудования усложняется глобальным дефицитом. Из-за ИИ-бума заводы перевели мощности на создание серверной памяти HBM для NVIDIA и AMD.
Как итог — острая нехватка GDDR7 для потребительского рынка. Розничная цена видеокарты RTX 5090 взлетела с рекомендованных $1,999 до $3,500–$5,000. В этих реалиях полностью готовая рабочая станция DGX Spark за $4,299 становится крайне конкурентоспособной по стоимости владения
6. Перспективы (2027+)
Индустрия движется к преодолению «стены памяти»:
- Архитектура Rubin: В 2027 году ожидается переход на память HBM4 с пропускной способностью более 3.6 ТБ/с на чип, что устранит текущие ограничения скорости в корпоративном сегменте.
- Модули LPCAMM2: В сегменте ПК на смену впаянной памяти и SO-DIMM приходят модули LPCAMM2, которые обеспечат высочайшую пропускную способность унифицированной LPDDR5X с возможностью апгрейда.
Итог: Если ваш профиль — генерация графики и видео или работа с моделями до 34B, ищите RTX 5090. Если вы разработчик RAG-систем, тестируете LLM на 70-200B параметров и вам нужна тихая машина с колоссальным объемом памяти, DGX Spark — единственный разумный выбор на сегодня.