Гибридный поиск в энтерпрайзе вырос в 3 раза за квартал: рынок объединил старые добрые ключевые слова с эмбеддингами, потому что «наивный» RAG на одних векторах сыпется в реальном продакшене. Пока все ждали, что бесконечный контекст убьет поиск, стало ясно — гибриды работают лучше.
Поиск по вайбу против поиска по фактам
Большинство тех, кто начинал внедрять RAG в 2023-м, попали в одну ловушку. В демо на десяти файлах всё работает идеально: модель находит нужный кусок текста и выдает ответ. Но стоит засунуть в систему миллион документов, как наступает «стена масштабирования».
Проблема в том, что векторный поиск — это поиск по «вайбу». Эмбеддинги превращают текст в координаты в многомерном пространстве. Если ты ищешь «ошибку в API при оплате через СБП», векторный поиск найдет всё, что семантически похоже на «проблемы с платежами». Но если нужен конкретный код ошибки, например «ERR_PAY_502», векторный поиск может его проигнорировать, потому что для него этот набор символов не имеет «смысла».
Это как искать нужную папку в огромном государственном архиве, полагаясь только на общее ощущение от темы. Ты примерно помнишь, что папка была «про налоги», и идешь в сторону налогового отдела. Но найти в этом отделе конкретный лист с номером 402-Б, используя только интуицию, практически невозможно.
Гибрид: когда BM25 спасает эмбеддинги
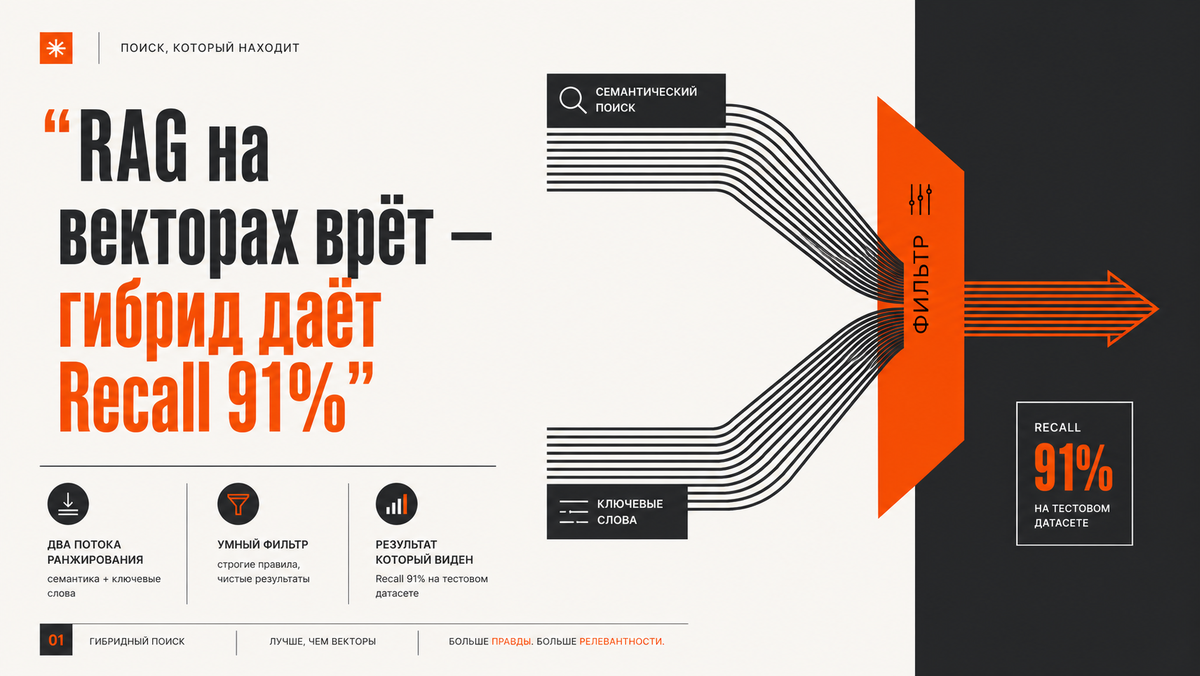
Чтобы перестать галлюцинировать на ровном месте, индустрия переходит на гибридные схемы. Суть проста: мы запускаем два поиска параллельно. Плотные векторы (Dense) понимают синонимы и контекст. Классический поиск по ключевым словам BM25 (Sparse) работает как старый добрый Ctrl+F.
Когда эти два потока объединяются через алгоритм RRF (простой математический способ склеить два рейтинга в один), точность взлетает. Разница в полноте колоссальна: если чистые векторы дают Recall@10 около 78%, то гибрид вытягивает его до 91%. При этом задержка вырастает всего на несколько миллисекунд, что в масштабах бизнес-процесса вообще незаметно.
Такой подход решает проблему ортогональных ошибок. BM25 железно находит артикулы, SKU и редкие технические термины, которые эмбеддинги часто «замыливают». В итоге система перестает путать разные версии одной библиотеки только потому, что их описания семантически похожи.
Реранкер как опытный архивариус
Но даже гибридный поиск возвращает слишком много лишнего. Чтобы модель не захлебнулась в мусоре, в продакшен-стек добавляют Cross-encoder реранкер. Если гибридный поиск служит для быстрого отбора топ-100 кандидатов, то реранкер — это тщательная проверка каждого из них.
Реранкер не ограничивается совпадением слов или близостью векторов — он буквально перечитывает пару найденных кусков текста вместе с вопросом пользователя. Это добавляет от 65 до 145 мс к ответу, но дает прыжок точности на 18–42%.
Это напоминает работу опытного архивариуса. Первый сотрудник быстро притащил из хранилища сто папок, которые «вроде как по теме». Архивариус же за минуту просматривает их все и оставляет только три листа, в которых действительно есть ответ. Без этого этапа RAG остается лотереей, где модель может уверенно сгенерировать бред, просто потому что поиск вернул релевантный по смыслу, но бесполезный по факту кусок текста.
Миф о бесконечном контексте
Параллельно с этим рухнула гипотеза о том, что огромные контекстные окна в миллион токенов убьют RAG. Казалось бы, зачем что-то искать, если можно просто скормить модели всю документацию целиком? На практике это оказалось дорого и нестабильно.
Появился эффект «потери в середине» (lost-in-the-middle): модель отлично видит начало и конец огромного текста, но совершенно забывает, что было в середине. К тому же бизнес требует прозрачности. Когда модель отвечает на основе RAG, ты видишь конкретную ссылку на документ. Когда она просто «помнит» что-то из миллиона токенов, ты получаешь черный ящик.
Современный стандарт — это Long-Context RAG. Гибридный поиск находит несколько целых документов, а огромное окно модели используется уже для глубокого синтеза и рассуждений над этими документами. Поиск отсекает лишнее, а контекст позволяет не терять нить рассуждения.
Кстати, если твой агент до сих пор галлюцинирует или тупит в базе знаний, я подбираю и внедряю модели под задачи бизнеса — за деталями пишите в телеграм @dmitra_ai.
В конечном счете важно помнить: RAG не лечит галлюцинации, он просто переносит их из головы модели в слой поиска. Если поиск вернул мусор, модель с самым большим контекстом в мире всё равно выдаст мусор, просто сделает это очень уверенно. RAG — это как очень быстрый библиотекарь, который за секунду находит нужную книгу, но если книга написана сумасшедшим, ответ всё равно будет безумным.