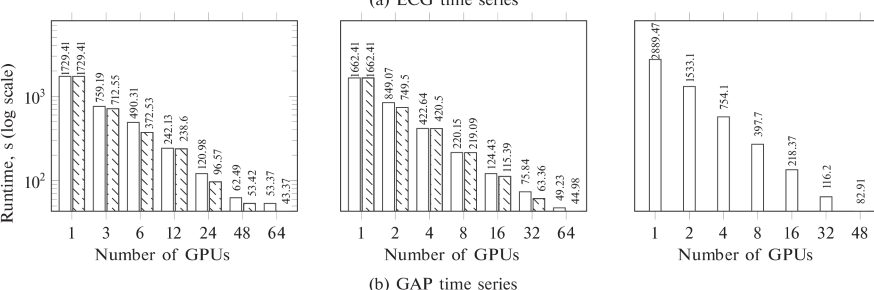
Согласно экспериментальным графикам, алгоритму поиска аномалий для переработки миллионов кардиограмм требуется от десятков до тысяч секунд, в зависимости от мощности системы.
Сотрудники НОЦ «Искусственный интеллект и квантовые технологии» ЮУрГУ, заместитель директора Михаил Цымблер и начальник отдела интеллектуального анализа данных и виртуализации Яна Краева, разработали новый параллельный алгоритм, который выполняет поиск аномалий в больших временных рядах с помощью кластерной системы с узлами на базе графических процессоров.
Результат опубликован в международном научном журнале «Lobachevskii Journal of Mathematics», который входит во второй квартиль научных изданий по версии Scopus (https://link.springer.com/article/10.1134/S1995080225606198).
Большие временные ряды присутствуют сегодня во многих, если не во всех сферах нашей жизни: устройства Интернета вещей, умное производство, персональная медицина, сейсморазведка, электронная торговля и многое другое. Такие ряды возникают там, где используются датчики с высокой частотой снятия показаний, за секунду генерирующие тысячи или даже десятки тысяч значений, интеллектуальный анализ которых направлен на улучшение качества нашей жизни.
Как отыскать аномалии в этой лавине данных, как автоматизировать поиск таких участков огромного ряда, которые не похожи на все остальное? Как организовать вычисления, если исходный ряд не только не охватить глазами, но и нельзя разместить целиком в памяти одного компьютера? Как обеспечить поиск аномалий временного ряда из любой предметной области, не используя дорогостоящую экспертизу специалиста в этой области?
На все эти вопросы отвечает новый алгоритм ученых из ЮУрГУ, получивший название PADDi (PALMAD-based anomaly discovery on distributed GPUs).
Алгоритм PADDi использует понятие диссонанса, которое формализует нечеткое понятие аномалии.
Диссонансы, найденные во временных рядах данных, отражают наличие аномального события в реальной жизни (хотя не всегда точно совпадают с ним по времени).
Это позволяет находить обнаруживать их при минимальном участии эксперта в конкретной предметной области. Со всем справится программа, алгоритму требуется знать лишь длину (количество точек) диссонанса.
«Обработка большого временного ряда организуется на двух уровнях, – объяснил принцип действия Михаил Цымблер. – Сначала данные разделяются на фрагменты, каждый из которых обрабатывается отдельным узлом кластера. Затем фрагмент разделяется на сегменты, и каждый сегмент обрабатывается графическими процессорами кластерного узла. За параллельную обработку одного сегмента отвечает разработанный авторами алгоритм PALMAD (см. выше расшифровку названия PADDi), который был опубликован нами ранее в топовом научном журнале Mathematics. В алгоритме PADDi используется важное ноу-хау авторов: на каждом из уровней узлы и GPU обмениваются полученными ими результатами. Если просто найти аномалии в отдельном фрагменте или сегменте, а затем предъявить все найденное как ответ, то это не сработает, ведь аномалия для какой-то части данных, очевидно, может не быть аномалией для всего объема анализируемых данных».
Разработка ученых из ЮУрГУ была опробована на двух современных суперкомпьютерах: «Ломоносов-2» (Московский государственный университет) и «Лобачевский» (Нижегородский государственный университет).
«В экспериментах были задействованы временные ряды с миллионами точек из различных предметных областей. Алгоритм PADDi с одной стороны, опередил передовые аналоги, а с другой – показал масштабируемость, близкую к линейной, – рассказал Михаил Цымблер. – Это значит, что при добавлении новых GPU в суперкомпьютер алгоритм адекватно увеличивает свое быстродействие. Это очень хороший результат, поскольку обмены данными между узлами кластера в общем случае снижают производительность параллельных алгоритмов. Однако в PADDi обмены промежуточными результатами организованы так, чтобы их число было как можно меньше. Этот ключевой момент позволяет PADDi опережать передовые аналоги».
В итоге можно сказать, что алгоритм PADDi, разработанный в ЮУрГУ – это в настоящее время единственный из известных параллельных алгоритмов, который способен эффективно искать аномалии в больших временных рядах из различных предметных областей на суперкомпьютерном кластере с мульти-GPU узлами.
Остап Давыдов