Конец эпохи VAE и новая эра нативной мультимодальной генерации от SenseTime

💽 СЛУШАТЬ ПОДКАСТ: ССЫЛКА
Эволюция нейросетей последних лет приучила нас к определенным стандартам. Мы привыкли, что генерация изображений — это сложный конвейер, где текстовые энкодеры (CLIP/T5) переводят слова в векторы, а вариационные автоэнкодеры (VAE) сжимают картинки в латентное пространство, чтобы видеокарта не "задохнулась" от нехватки памяти. Но что, если этот подход изначально был компромиссом?
28 апреля 2026 года компания SenseTime в сотрудничестве с лабораторией S-Lab Наньянского технологического университета совершила фундаментальный сдвиг в этой парадигме. В открытый доступ была выложена модель SenseNova-U1 — первая нативная мультимодальная архитектура, которая работает напрямую с пикселями и полностью отказывается от VAE.
В этой статье мы разберем, как устроена новинка, почему она выдает идеальную инфографику и сколько видеопамяти (VRAM) потребуется для ее запуска на домашнем ПК.
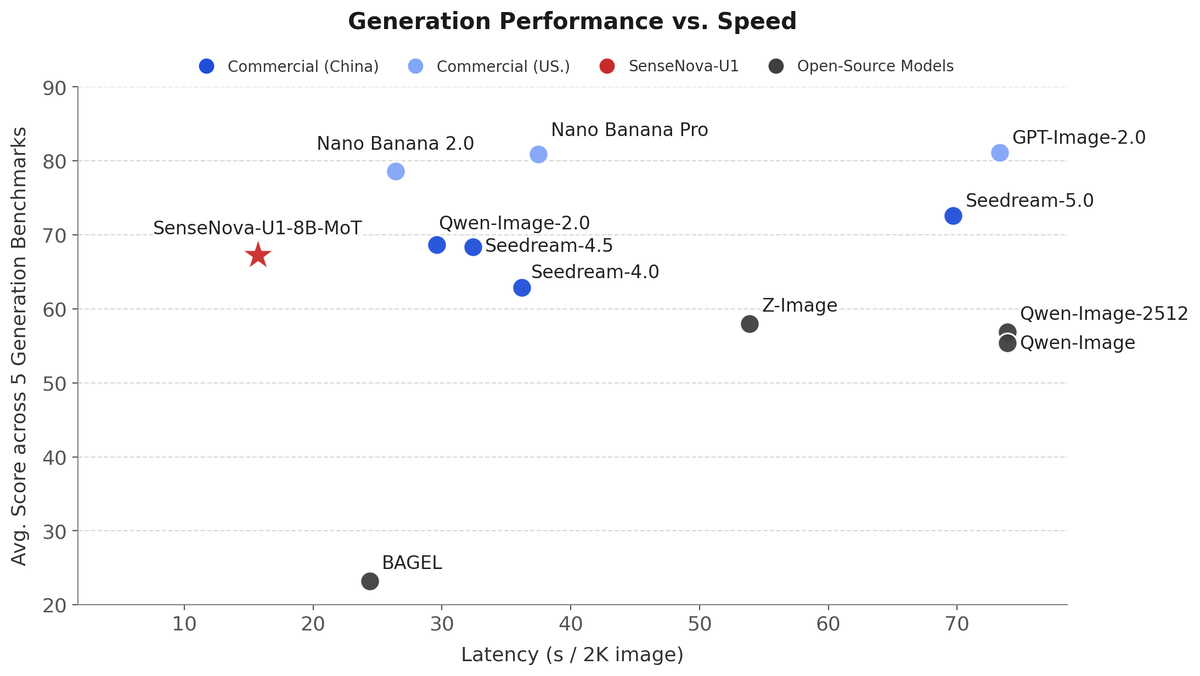
Архитектура NEO-Unify: Жизнь без VAE
Практически любая популярная модель (от Stable Diffusion до Flux) использует VAE для математического сжатия визуальных данных. Это гениальный костыль, который позволил запускать генерацию на потребительских видеокартах, но у него есть критический недостаток — потеря микродеталей. Сжатие и декодирование всегда "съедают" идеальную геометрию, мелкие шрифты и сложную верстку.
SenseNova-U1 построена на архитектуре NEO-Unify. Разработчики полностью удалили визуальный энкодер (VE) и VAE. Модель работает напрямую в пиксельном пространстве с показателем пикового отношения сигнала к шуму (PSNR) на уровне 31.5.
Вместо того чтобы прогонять текст и картинки через разные "переводчики", SenseNova-U1 использует технологию Mixture of Tokens (MoT). Внутри этой монолитной архитектуры слова и пиксели воспринимаются как глубоко связанные данные. Модель буквально "понимает" то, что рисует.
Главные киллер-фичи модели
Отказ от латентного пространства открыл двери к возможностям, которые раньше требовали сложнейших многоступенчатых пайплайнов.
1. Нативная чередующаяся генерация (Interleaved Generation)
Исторически создание гайда с картинками требовало связки из LLM (для текста) и диффузионной модели (для иллюстраций). SenseNova-U1 умеет генерировать связный текст и картинки вперемешку за один проход. Вы можете попросить ее написать иллюстрированный дневник путешественника или научный отчет, и она выдаст готовый документ, где картинки идеально соответствуют соседним абзацам.
2. Идеальная инфографика и типографика
SenseNova-U1 демонстрирует феноменальные результаты в рендеринге высокоплотной информации. Модель идеально подходит для создания:
- Коммерческих плакатов
- Научных иллюстраций
- Многопанельных комиксов
- Презентаций и графиков
Там, где другие модели искажают шрифты и "плывут" в разметке, U1 сохраняет попиксельную точность. Не зря в жестком коммерческом бенчмарке BizGenEval (оценивающем контроль верстки и генерацию текста) модель конкурирует с закрытыми коммерческими API и на голову разбивает опенсорс-решения прошлых поколений.
Версии, разрешения и "хитрые" 8B
Разработчики выложили на Hugging Face две основные ветки модели (включая их SFT-версии):
- SenseNova-U1-8B-MoT (плотный магистральный профиль)
- SenseNova-U1-A3B-MoT (профиль на базе Mixture of Experts)
Важный нюанс: Хотя модель называется "8B", реальное количество параметров под капотом составляет около 18 миллиардов. Маркировка "8B" означает количество активных параметров при одном проходе. Это дает модели "интеллект" 18-миллиардной архитектуры при скорости генерации 8-миллиардной.
Модель обучалась на бакетах разрешений около 2K пикселей. Оптимальные форматы:
- Квадрат (1:1): 2048 × 2048
- Широкоформат (16:9): 2720 × 1536
- Фото (3:2): 2496 × 1664
Требования к железу: Сколько нужно VRAM?
Развертывание 18B мультимодальной модели — нетривиальная задача. Однако благодаря современным методам квантования запустить ее можно даже на видеокартах среднего сегмента:
Реакция сообщества и где попробовать
Сразу после релиза на GitHub и Reddit (в частности, в r/StableDiffusion) появились первые отзывы. Пользователи отмечают высокую скорость генерации и поразительную чистоту рендеров (особенно на скетчах и графике). Хотя некоторые энтузиасты скучают по "шумной эстетике" классических диффузионок с лорами, для коммерческого и корпоративного применения чистые результаты SenseNova-U1 — это огромный плюс.
Где взять модель:
Нет мощной видеокарты?
SenseTime запустили бесплатную браузерную песочницу SenseNova-Studio, где крутится ускоренная версия U1-Fast, гипероптимизированная для создания макетов и инфографики.
Отказ от VAE и переход к нативной унификации текста и пикселей — это не просто новый релиз, это направление, в котором, скорее всего, будет двигаться вся индустрия генеративного ИИ в ближайшие годы.