


Пока большая часть IT-индустрии продолжает жить в состоянии почти религиозного поклонения NVIDIA, AMD тихо — и довольно хладнокровно — выкатила продукт, который может оказаться одним из самых неприятных сюрпризов для рынка AI-инфраструктуры за последние годы. Речь о AMD Instinct MI350P PCIe.
На бумаге всё выглядит почти вызывающе:
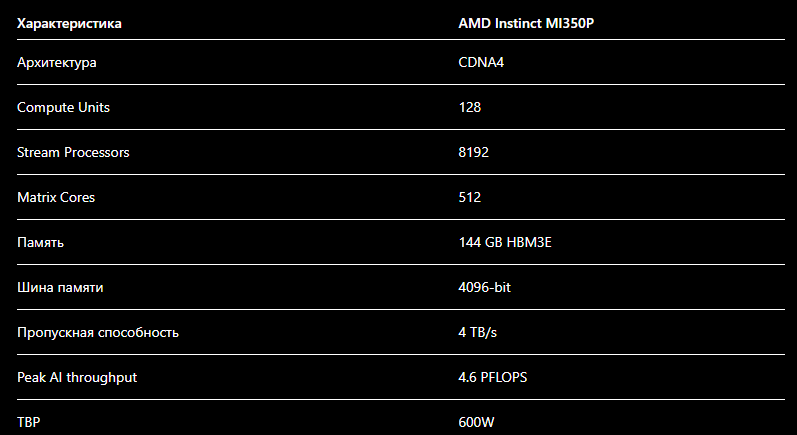
144 ГБ HBM3E, до 4.6 PFLOPS AI-производительности, 4 ТБ/с пропускной способности памяти, PCIe-формат, обычное воздушное охлаждение и возможность поставить всё это в стандартную серверную стойку без реконструкции половины дата-центра.
И вот тут начинается самое интересное.
Потому что MI350P — это не просто «ещё один AI-ускоритель AMD». Это очень точный удар в конкретную боль рынка. Причём боль, о которой последние два года предпочитали говорить шёпотом.
AI-бум оказался дорогим даже для богатых
Есть забавный парадокс современной AI-индустрии: все говорят про модели, но почти никто не любит обсуждать инфраструктуру. Хотя именно она сейчас определяет, кто вообще сможет играть в эту гонку.
Потому что обучить модель — это уже полбеды. Дальше начинается куда менее гламурная история:
- питание,
- охлаждение,
- стойки,
- сетевые фабрики,
- плотность GPU,
- счета за электричество,
- и, конечно, дефицит ускорителей.
Последние два года рынок жил в довольно странной реальности, где многие компании покупали AI-кластеры не потому, что экономика сходилась, а потому что «иначе мы отстанем». Иногда создавалось ощущение, что CFO крупных корпораций подписывали бюджеты на GPU примерно в том же психологическом состоянии, в каком люди покупают генератор во время масштабного блэкаута: дорого, неудобно, но страшно остаться без него.
И тут AMD выходит с довольно прагматичным сообщением:
«Вам не обязательно перестраивать дата-центр ради AI».
На фоне индустрии, где всё постепенно катится к 1000–1400 Вт на ускоритель и жидкостному охлаждению как новой норме, идея «drop-in PCIe AI GPU» звучит почти старомодно. Но именно поэтому она и выглядит опасно рациональной.
MI350P — это не “младшая версия”. Это другой класс продукта
Многие по инерции пытаются воспринимать MI350P как урезанный вариант MI350X. Формально — да, PCIe-версия действительно получила примерно половину ресурсов старшей OAM-модели:
- 128 CU вместо 256,
- 144 ГБ вместо 288,
- 4 ТБ/с вместо 8 ТБ/с.
Но логика здесь совсем другая.
AMD не пыталась сделать «дешёвый MI350X». Она пыталась решить проблему совместимости AI с существующей инфраструктурой.
Это принципиально иной подход.
Потому что большинство компаний сегодня не готовы:
- переделывать электрику в дата-центрах,
- переходить на жидкостное охлаждение,
- менять стойки,
- строить NVLink-фабрики уровня hyperscale.
Именно поэтому PCIe-ускорители внезапно снова становятся интересными. Хотя ещё недавно казалось, что рынок окончательно ушёл в сторону гигантских OAM-платформ.
Цифры, которые выглядят почти абсурдно для PCIe-карты
Когда AMD заявляет:
- 144 GB HBM3E,
- 4 TB/s,
- до 4.6 PFLOPS,
это сначала воспринимается как типичный AI-маркетинг. В индустрии сейчас вообще любят оперировать числами, которые мало кто интерпретирует правильно.
Но в случае MI350P интереснее другое: насколько плотно AMD упаковала всё это в классический PCIe-формат.
Вот что особенно бросается в глаза:
И здесь важно не попасть в маркетинговую ловушку.
4.6 PFLOPS — это не «обычная» производительность GPU. Не FP32 и не игровой equivalent. Речь идёт о MXFP4/MXFP6 — ультранизкой точности, которая сейчас активно используется в inference-нагрузках LLM.
Но индустрия AI постепенно приходит к довольно неудобному выводу: для огромного числа inference-задач высокая точность просто не нужна.
И это ломает старую логику GPU-рынка.
NVIDIA всё ещё впереди. Но ситуация уже не выглядит безнадёжной
AMD несколько лет подряд находилась в странной позиции догоняющего. Формально продукты были мощными, но экосистема — сырой. ROCm долго воспринимался как нечто, что «почти готово», но всегда с оговорками.
Иногда складывалось ощущение, что AMD продаёт не платформу, а обещание платформы.
Сейчас ситуация начала меняться.
Не потому что AMD внезапно обогнала NVIDIA. Этого пока нет. CUDA по-прежнему остаётся индустриальным стандартом. И любая компания, утверждающая, что миграция с CUDA «проходит безболезненно», либо лукавит, либо не мигрировала ничего серьёзного.
Но у рынка появилась другая проблема: стоимость владения AI-инфраструктурой начинает пугать даже крупных игроков.
И вот тут MI350P выглядит очень своевременно.
Потому что AMD продаёт не просто TFLOPS. Она продаёт:
- отсутствие необходимости переделывать дата-центр,
- возможность использовать существующие серверы,
- воздушное охлаждение,
- меньший CAPEX,
- отсутствие привязки к дорогой проприетарной инфраструктуре.
Это уже разговор не про «самый быстрый GPU в мире». Это разговор про экономику эксплуатации.
А экономика сейчас начинает побеждать хайп.
144 ГБ памяти — возможно, главный козырь карты
Любопытно, что многие обсуждают PFLOPS, хотя куда важнее здесь объём HBM3E.
144 ГБ — это очень серьёзно для PCIe-ускорителя.
Причём речь не только про размер модели. Всё упирается в inference latency и batching. Чем больше модель помещается локально в память ускорителя, тем меньше начинается цирк с offloading, NUMA-танцами и деградацией производительности.
Сейчас AI-индустрия постепенно приходит к довольно прагматичному пониманию:
память иногда важнее чистой вычислительной мощности.
Особенно в эпоху огромных LLM.
И здесь AMD играет очень грамотно.
Есть ли у MI350P слабые места? Конечно
Было бы странно делать вид, что их нет.
Во-первых, 600 Вт — это всё ещё очень много. Да, на фоне Blackwell это уже почти выглядит «умеренно», что само по себе звучит немного безумно. Но для классического PCIe-сегмента это серьёзная тепловая нагрузка.
Во-вторых, ROCm всё ещё уступает CUDA по зрелости. Особенно в enterprise-среде, где важны:
- стабильность,
- инструменты,
- совместимость,
- поддержка библиотек,
- документация,
- человеческий опыт эксплуатации.
И вот последний пункт часто недооценивают.
Найти инженера с большим CUDA-опытом сегодня проще, чем команду, глубоко понимающую AMD AI stack.
Это не фатально. Но это реальность рынка.
Самое интересное — AMD неожиданно попала в правильный момент
Есть ощущение, что рынок AI-инфраструктуры начинает уставать от гигантомании.
Последние поколения ускорителей всё сильнее напоминают не PCIe-карты, а отдельные энергетические проекты. Иногда новости о новых AI-кластерах читаются как описание строительства мини-электростанции.
На этом фоне MI350P выглядит почти консервативно:
- обычные стойки,
- обычное охлаждение,
- PCIe,
- знакомая серверная инфраструктура.
И именно это может оказаться её главным преимуществом.
Потому что не всем нужен hyperscale-кластер уровня OpenAI или xAI. Большинству компаний нужен AI, который можно внедрить без капитального ремонта всего дата-центра.
AMD, похоже, это поняла раньше многих.
И если несколько лет назад Instinct-линейка воспринималась скорее как «альтернатива для энтузиастов», то теперь разговор становится куда серьёзнее.
Рынок AI постепенно выходит из стадии эйфории и начинает считать деньги. А это уже совсем другая игра.