
DeepSeek V4: новая LLM с открытыми весами, снижающая затраты на инференс в разы по сравнению с R1, с поддержкой ускорителей Huawei. — theregister.com
Китайский любимец в сфере ИИ, компания DeepSeek, представила новую большую языковую модель с открытыми весами, которая обещает производительность, сопоставимую с лучшими проприетарными американскими LLM. Что, возможно, более важно, она заявляет о резком снижении затрат на инференс и расширяет поддержку семейства ускорителей ИИ Ascend от Huawei.
DeepSeek V4, представленная в пятницу, доступна для загрузки в популярных репозиториях моделей, таких как Hugging Face, через API компании и веб-сервис в двух новых вариантах. Первый — это меньшая модель Flash mixture-of-experts (MoE) с 284 миллиардами параметров и 13 миллиардами активных параметров, а второй, более крупный, имеет 1,6 триллиона параметров, из которых в любой момент времени задействовано 49 миллиардов.
V4-Pro обучалась на 33 триллионах токенов и, если верить DeepSeek, превосходит все LLM с открытыми весами, конкурируя с лучшими проприетарными моделями Запада по всему набору бенчмарков.
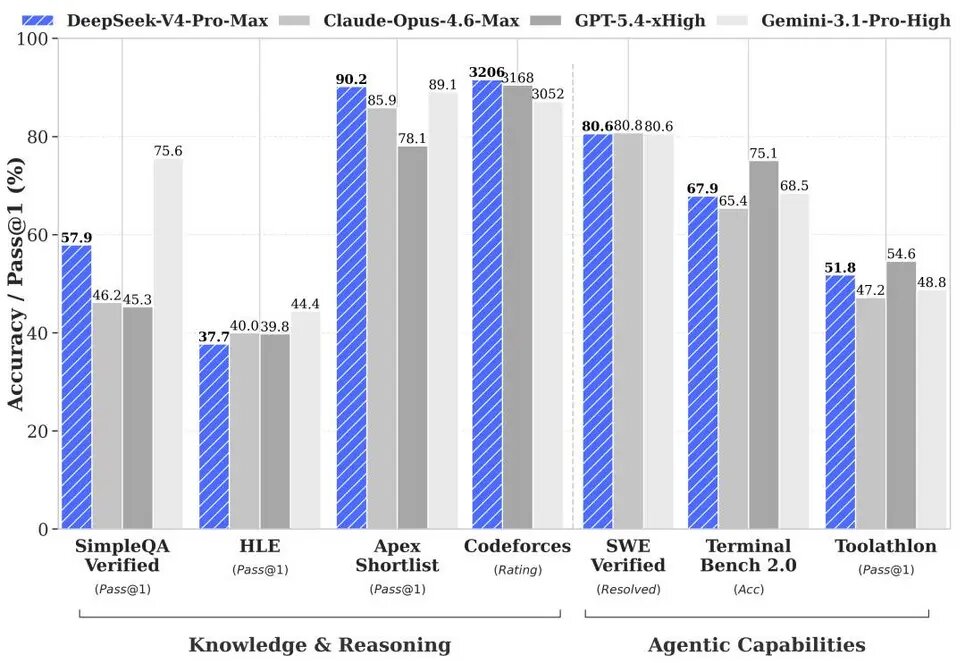
Вот как DeepSeek заявляет о позициях своей модели V4 по сравнению с конкурентами. — Нажмите для увеличения
Конечно, к этим заявлениям следует относиться с долей скептицизма. Хотя DeepSeek имеет сильный послужной список благодаря своим моделям семейства V3 и R1, которые сделали китайского разработчика широко известным, одно лишь хорошее выступление в стандартных бенчмарках не гарантирует успеха в реальных приложениях.
Мы ожидаем, что DeepSeek V4-Pro будет значительно лучше предыдущих разработок компании. Новая модель почти на триллион параметров больше и использует больше активных параметров во время инференса. Однако, как и в случае с DeepSeek V3, которая показала, что большие передовые модели можно обучать с меньшими вычислительными затратами, чем считалось ранее, бенчмарки не раскрывают всей картины.
Под капотом DeepSeek V4 представляет несколько новых архитектурных изменений, которые, по словам разработчиков, должны сделать обслуживание модели значительно менее затратным.
Первое довольно простое. На этот раз DeepSeek выпускает вторую, меньшую модель Flash, которая требует меньше инфраструктуры для работы и обеспечит более интерактивный пользовательский опыт при меньших затратах. Меньшие модели просто дешевле в обслуживании.
Само по себе это не новая стратегия, но DeepSeek начинает применять ее, по крайней мере, в отношении своих внутренних моделей.
Более крупное и значимое изменение касается того, как DeepSeek вычисляет механизм внимания. Механизм внимания модели влияет на то, как она преобразует промпт в пары ключ-значение, используемые для генерации выходных токенов.
В статье, опубликованной вместе с новыми моделями, исследователи DeepSeek описывают гибридный механизм внимания, сочетающий две технологии: Compressed Sparse Attention и Heavy Compressed Attention, для уменьшения объема вычислений, требуемых во время инференса, и памяти, необходимой для KV-кэшей, используемых для отслеживания состояния модели.
Последний элемент имеет ключевое значение для эффективности DeepSeek V4, поскольку эти кэши могут быть довольно большими. Провайдеры инференса также склонны выгружать их в системную память или флэш-память, чтобы избежать штрафов за холодный старт. Более сильно сжатые KV-кэши означают, что требуется меньше памяти и хранилища для крупномасштабных инференс-развертываний.
В совокупности эти технологии позволяют модели поддерживать контекстное окно в миллион токенов, используя в 9,5–13,7 раза меньше памяти, чем DeepSeek V3.2.
Для дальнейшего уменьшения объема памяти модели DeepSeek продолжает свою традицию использования типов данных с низкой точностью. DeepSeek V3 была одной из первых моделей с открытыми весами, обученных в формате FP8.
Теперь обе модели V4 используют смесь точностей FP8 и FP4. В частности, разработчики модели использовали обучение с учетом квантования (quantization-aware training) для весов экспертов MoE.
Как мы уже обсуждали, FP4 фактически удваивает объем памяти, необходимый для хранения весов модели по сравнению с FP8, что является значительной экономией, если вы готовы смириться с потерей точности.
Архитектурные улучшения DeepSeek не ограничиваются только инференсом. В V4 разработчики модели внедрили новый оптимизатор под названием Muon, предназначенный для ускорения сходимости и повышения стабильности обучения.
Модель собственного производства для собственного оборудования
Возможно, самым интересным и наименее детализированным элементом новых моделей является оборудование, на котором они работают. В то время как DeepSeek V3 была сильно оптимизирована для GPU Hopper, V4 была проверена на совместимость как с ускорителями Nvidia, так и с ускорителями Huawei.
В статье о DeepSeek V4 чипы упоминаются вскользь, где отмечается, что компания проверила свою «мелкозернистую схему EP [Expert Parallel] как на GPU Nvidia, так и на платформах NPU Ascend».
Чтобы было ясно, это не означает, что модель была полностью обучена на оборудовании Huawei, а лишь то, что DeepSeek провела валидацию ускорителей ИИ китайского телекоммуникационного гиганта для обслуживания модели.
Возможно, DeepSeek использовала комбинацию GPU Nvidia для предварительного обучения и ускорителей Huawei для обучения с подкреплением. Последнее — это этап постобучения, смежный с инференсом, используемый для обучения моделей новым навыкам, поведению и рассуждениям по цепочке мыслей. Однако в статье это прямо не обсуждается.
Инференс, как правило, имеет более низкий порог входа для новых производителей чипов. Однако в какой-то момент DeepSeek пыталась обучать свои модели и на чипах Huawei. Это усилие, по сообщениям, было сорвано из-за некачественных чипов, медленного интерконнекта и незрелого программного стека, что в конечном итоге заставило DeepSeek вернуться к Nvidia.
Наконец, использование типов данных с 4-битной точностью в V4 может навести на мысль, что DeepSeek заполучила ускорители Blackwell от Nvidia, которые этот поставщик ИИ не имеет права продавать в Китае, но это не является строго необходимым.
GPU Hopper не поддерживают аппаратное ускорение FP4, но могут работать с этим типом данных в режиме только для весов. Такой подход не дает преимуществ в производительности с плавающей запятой, но снижает требования к памяти и пропускной способности как при обучении, так и при инференсе, что делает его оправданным компромиссом во многих сценариях использования.
Цена, чтобы продать
DeepSeek V4 в настоящее время находится в предварительном доступе, и базовые версии модели, а также версии с инструктивной настройкой доступны для загрузки или через API.
Компания, что неудивительно, предлагает доступ через API к меньшей модели по сниженной ставке $0,14 за миллион входных токенов (без кэширования) и $0,28 за миллион выходных токенов.
Более крупная модель Pro значительно дороже: $1,74 за миллион входных токенов и $3,48 за миллион выходных токенов, но это все еще доля от того, что западные поставщики ИИ взимают за доступ к своим лучшим моделям. Для справки, OpenAI взимает $5 за миллион входных токенов и $30 за миллион выходных токенов за GPT-5.5. ®
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Tobias Mann