
💽 СЛУШАТЬ ПОДКАСТ: ССЫЛКА
Основой невероятной производительности Qwen 3.6 27B является ее уникальная и глубоко переработанная базовая архитектура. В то время как индустрия увлекалась созданием разрозненных ансамблей экспертов (MoE), где каждый токен обрабатывается лишь крошечной долей сети (например, 17 миллиардами из 397 миллиардов в модели Qwen 3.5 397B), команда Alibaba решила инвестировать ресурсы в оптимизацию плотной структуры (Dense Model).
⚙️Технология модели: Архитектура гибридного внимания
Архитектурный базис Qwen 3.6 27B (Casual Language Model) состоит из 27 миллиардов полноправных весов, скрытого пространства (Hidden Dimension) размерностью 5120 и 64 глубоких слоев. Размер словаря эмбеддингов увеличен до 248 320 токенов (включая паддинг), что обеспечивает великолепное покрытие как английского, русского, так и других языков, а также специфического программного синтаксиса.
Фундаментальным прорывом стала структура распределения внимания. Разработчики применили гибридный лейаут слоев: 16 × (3 × (Gated DeltaNet → FFN) → 1 × (Gated Attention → FFN)).
Эта техническая формула скрывает в себе решение одной из главных проблем современных нейросетей — квадратичной вычислительной сложности. Традиционный механизм внимания (Gated Attention) требует ресурсов, растущих в квадрате от длины контекста. При контексте в 262 тысячи токенов стандартная модель потребовала бы терабайты видеопамяти.
Чтобы избежать этого, Qwen использует Gated DeltaNet — инновационный механизм линейного внимания (Linear Attention). Он состоит из 48 голов для проекций Values и 16 голов для Queries/Keys с размерностью головы 128. Линейное внимание обрабатывает длинные последовательности токенов с минимальными затратами ресурсов, что позволяет достигать феноменальных скоростей предзаполнения промпта (Prefill speed). Однако линейное внимание имеет недостаток: оно может "размывать" точные факты на длинных дистанциях. Для компенсации этого эффекта, каждый четвертый слой в сети является классическим Gated Attention (24 головы для Q, 4 для KV, размерность 256), который выступает в роли "якоря" абсолютной точности, извлекая кристально четкие факты из линейного потока. Пространственное позиционирование обеспечивается роторными эмбеддингами (RoPE) с размерностью 64.
Дополнительно в архитектуру заложена поддержка спекулятивного многоточечного декодирования (Multi-Token Prediction, MTP). При запуске через движки, поддерживающие эту технологию (например, vLLM), параметр num_speculative_tokens=2 (или более) позволяет модели предсказывать сразу несколько будущих токенов за один такт вычислений, увеличивая скорость генерации сложного кода почти в два раза.
📊 Сильные стороны по бенчмаркам
Глубокая архитектурная проработка привела к тому, что модель обрела беспрецедентные способности к автономному рассуждению (Thinking Mode). Перед выдачей ответа модель переходит в фазу планирования, разбивая сложную задачу (например, рефакторинг спагетти-кода) на логические блоки.
Спектр сильных сторон Qwen 3.6 27B четко отражен в результатах тестирования, которые подтверждаются как официальным блогом, так и независимыми аудиторами.
🔗 Официальный блог разработчиков с результатами: https://qwen.ai/blog?id=qwen3.6-27b
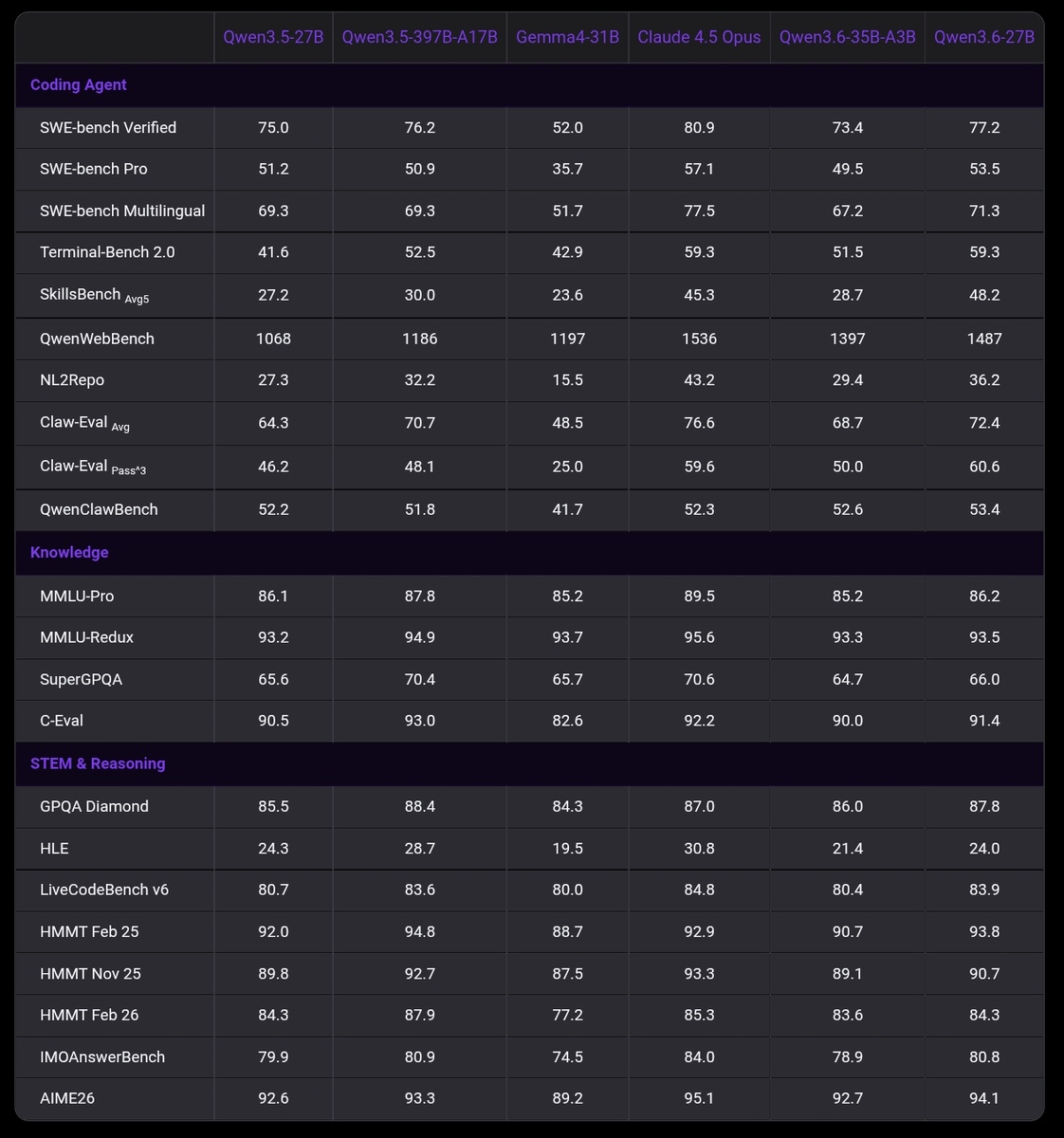
Данные бенчмарков неопровержимо доказывают, что Qwen 3.6 27B является исключительным инструментом для агентного программирования (agentic coding). Оценка 59.3 в Terminal-Bench 2.0 математически идентична результату флагманской закрытой модели Claude 4.5 Opus, что является сейсмическим сдвигом для локальных (Open Weights) моделей. Модель способна не просто генерировать текстовые сниппеты, но выступать в роли полноправного разработчика: планировать архитектуру, вызывать внешние API (tool calling), навигировать по локальной файловой системе и итеративно исправлять баги, читая вывод компилятора.
👁️🗨️ Мультимодальность
Современные задачи искусственного интеллекта редко ограничиваются исключительно текстовой модальностью. Одной из сильнейших сторон Qwen 3.6 27B является ее изначальная мультимодальная природа. Архитектура модели включает в себя встроенный визуальный энкодер (Vision Encoder), который позволяет ей воспринимать, очень точно анализировать и интерпретировать графическую информацию, такую как изображения и видео.
💾 Потребление ресурсов
Несмотря на компактность по сравнению с моделями на сотни миллиардов параметров, 27 миллиардов весов в плотной конфигурации предъявляют крайне суровые требования к подсистеме памяти (VRAM) графического ускорителя. В отличие от MoE-моделей, где неактивные эксперты могут быть относительно безболезненно выгружены в медленную системную память (DDR4/DDR5), полная матрица плотной модели должна присутствовать в видеопамяти при обработке каждого токена. Анализ показывает, что выгрузка слоев Qwen 3.6 27B на центральный процессор (CPU Offloading) ведет к катастрофической деградации скорости инференса.
Для обеспечения комфортной работы локально на потребительских видеокартах критически важно использовать форматы квантования GGUF, которые сжимают веса модели с минимальной потерей точности. Самым популярным балансом между качеством и размером является 4-битное квантование Q4_K_M.
Базовый размер весов файла GGUF в квантовании Q4_K_M составляет приблизительно 16–17.6 ГБ (в зависимости от специфики сборки). Однако это лишь статический вес. Во время генерации текста модель создает так называемый KV-кеш (Key-Value cache), размер которого динамически и линейно растет в зависимости от длины контекста.
Эмпирические данные профилировщиков выявляют следующую картину:
- При обработке умеренного контекста в 32 000 токенов с активированным 8-битным квантованием KV-кеша, общее потребление памяти (веса + кеш) достигает 29–32 ГБ VRAM.
- Максимальный нативный контекст (262k токенов) при квантовании Q6_K потребует около 40 ГБ видеопамяти.
🏁 ПОДВЕДЕМ ИТОГ
Можно констатировать, что Qwen 3.6 27B произвела подлинную революцию в сегменте локальных ИИ-решений. Объединив инновационную архитектуру гибридного внимания с феноменально выверенным обучающим корпусом, инженеры создали плотную нейросеть, которая способна заменить массивы из сотен миллиардов параметров в задачах программирования и системной инженерии. Доступность локального запуска на видеокартах уровня RTX 3090/4090 переводит технологию автономных ИИ-агентов из корпоративных дата-центров непосредственно на рабочие столы индивидуальных разработчиков, формируя новый стандарт независимой и безопасной автоматизации.