Xiaomi MiMo-V2.5: новая серия опенсорс агентов от Xiaomi на уровне Claude Opus и GPT-5
Xiaomi представила MiMo-V2.5, серию открытых моделей с акцентом на автономную работу агентов и решение сложных инженерных задач.
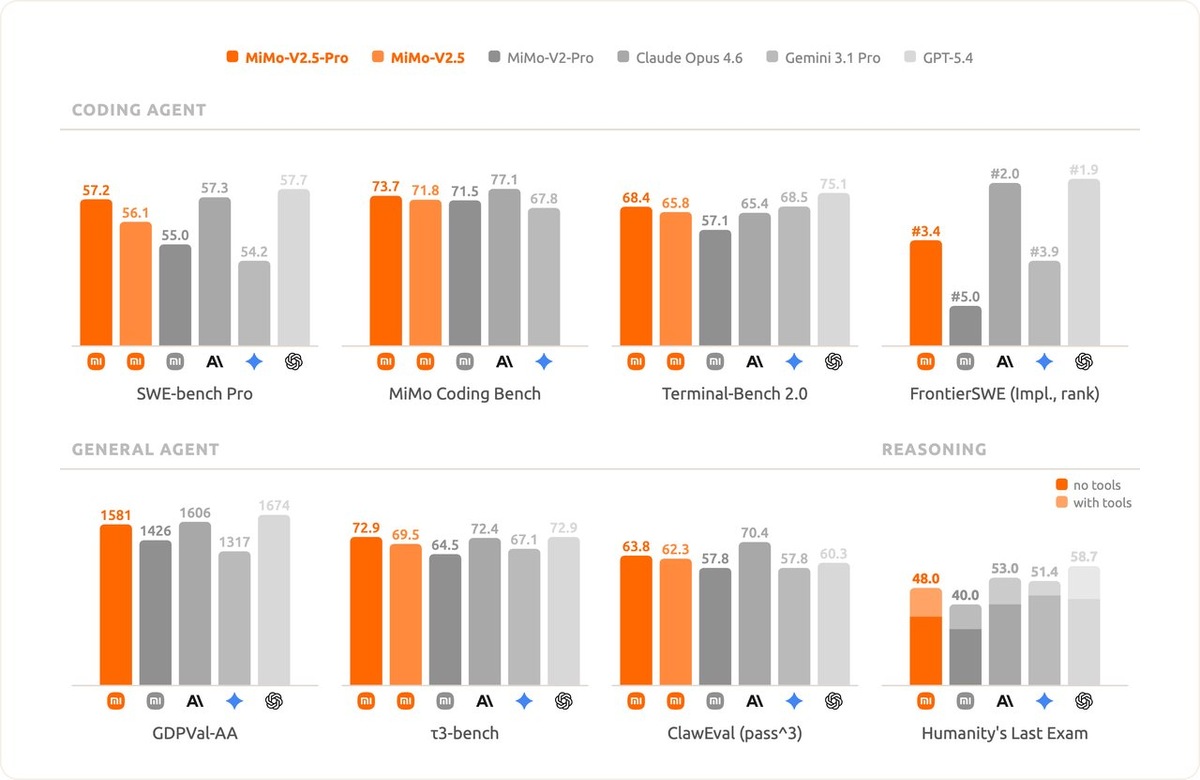
Старшая версия MiMo-V2.5-Pro в тестах SWE-bench Pro и Claw-Eval показывает результаты на уровне топовых моделей вроде Claude Opus 4.6.
Модели:
— MiMo-V2.5-Pro: модель для длинных цепочек действий. Она способна автономно выполнять задачи, требующие более 1000 последовательных вызовов различных инструментов. В тестах на разработку ПО (SWE-bench Pro) модель набрала 57.2 балла.
— MiMo-V2.5: универсальная мультимодальная модель. Работает со скоростью 100–150 токенов в секунду, понимает видео и изображения, поддерживает контекстное окно в 1 млн токенов. При этом стоимость использования в два раза ниже Pro-версии.
Новые MiMo оптимизированы под минимальный расход ресурсов. На бенчмарке ClawEval версия Pro тратит на 42% меньше токенов, чем Kimi K2.6, при сохранении того же качества результата. Обычная MiMo-V2.5 потребляет в два раза меньше токенов, чем Muse Spark.
Разработчики позиционируют серию как полноценную замену закрытым моделям в сценариях, где агенты должны часами или днями выполнять работу экспертного уровня без участия человека. Все подробности можно почитать тут.