Текст подготовил: Андрей Федорчук
Evals (Evaluations) в маркетинге - это тестирование выходов нейросети по заданным критериям до публикации, чтобы отсеять слабые офферы, рискованные формулировки и креативы не в Brand Voice еще на этапе генерации.
Обычно AI в маркетинге используют так: нагенерили 30 вариантов, выбрали на глаз, запустили. А потом выясняется, что половина текстов слишком агрессивная, часть обещает то, чего нет в прайсе, а визуал не попадает в бренд-гайд.
Переход сейчас простой: от «просто генерации» к автоматизированной валидации. Ниже покажу три вещи: как собрать свой чек-лист для AI (scorecard), как прогонять креативы через каскад фильтров в Make.com и как подключить синтетические персоны, чтобы критика была до запуска, а не после слива бюджета.
Как тестировать AI-креативы и офферы до публикации: 7 шагов
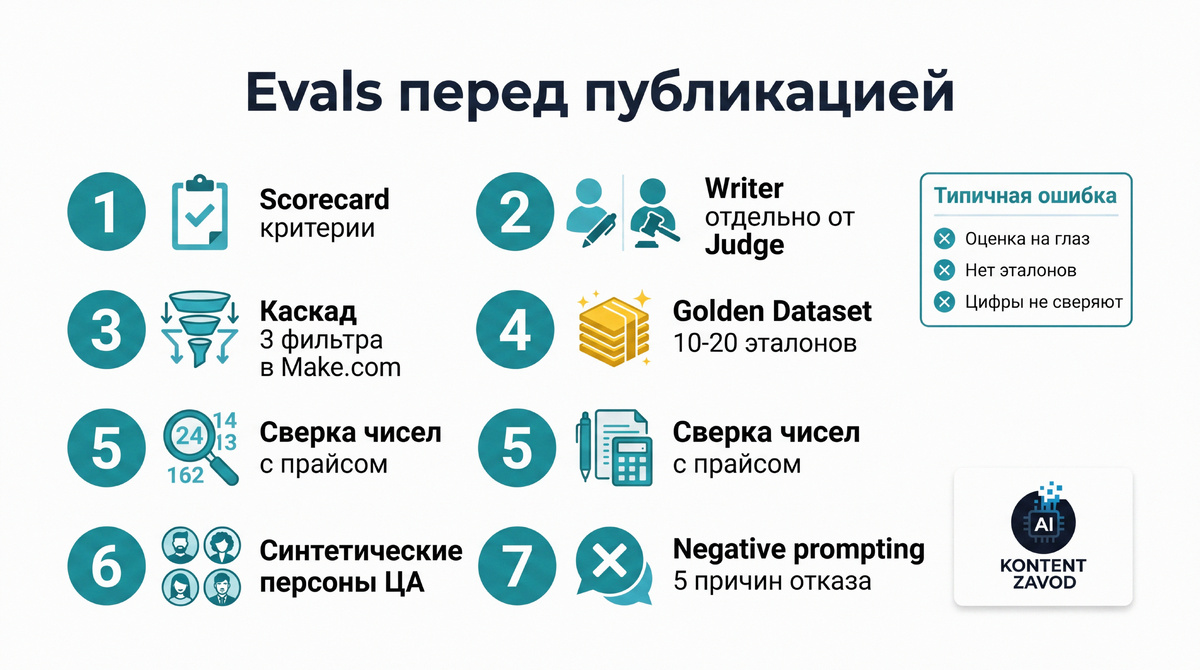
Шаг 1. Зафиксируйте, что именно вы считаете «хорошо»
Что делаем: собираем scorecard - короткий цифровой чек-лист. Примеры критериев из практики: Brand Voice, попадание в боль ЦА, юридическая чистота, аккуратность с цифрами и условиями.
Зачем: без критериев evals превращаются в вкусовщину и спор «нравится/не нравится».
Типичная ошибка: пытаться оценивать все сразу одним вопросом «оценишь текст?». Судья дает общие слова, а не решение.
Мини-пример РФ: для банка или финтеха отдельным пунктом добавляют запрет на двусмысленные обещания доходности и агрессивные призывы.
Шаг 2. Разделите генерацию и проверку (writer и judge)
Что делаем: одна модель генерирует (writer), другая оценивает (judge). Это и есть LLM-as-a-Judge: более мощная модель проверяет результат по шкале.
Зачем: модель-автор часто уверенно пишет спорное. Судья лучше держит рамки, если вы дали критерии и формат ответа.
Типичная ошибка: просить того же автора «самому себя критиковать». Часто это мягкая критика без реальных правок.
Мини-пример РФ: для Telegram-объявлений writer генерирует 20 вариантов, judge возвращает JSON с баллами и причинами отказа.
Шаг 3. Сделайте каскад из 3 фильтров в Make.com
Что делаем: строим сценарий Make.com, где каждый креатив проходит три проверки: Alignment (стоп-слова и ценности бренда), Impact (AIDA или PAS), Uniqueness (сравнение с базой прошлых кампаний в Google Sheets или Airtable).
Зачем: один фильтр не ловит все. Каскад быстрее объясняет, где именно проблема: тон, структура оффера или вторичность.
Типичная ошибка: ставить «проходной балл» без расшифровки. Команда не понимает, что править.
Мини-пример РФ: ecom-бренд фиксирует стоп-слова для обещаний «самый дешевый» и отсекает такие варианты на первом же фильтре.
Шаг 4. Соберите «золотой набор» и сравнивайте с ним
Что делаем: берем 10-20 лучших постов/объявлений, которые реально сработали, и храним как Golden Dataset. Судья сравнивает новый текст с эталонами по стилю и качеству и ставит оценку схожести.
Зачем: Brand Voice проще держать через примеры, чем через длинные описания.
Типичная ошибка: класть в золотой набор «красивые» тексты без подтвержденного результата.
Мини-пример РФ: для сети клиник в золотой набор добавляют только согласованные юридически тексты, чтобы не плодить риск.
Шаг 5. Проверяйте «галлюцинации» чисел и условий
Что делаем: если нейросеть пишет скидки, сроки, комплектацию, ставим сверку: модуль в Make.com вытаскивает числа из текста и сравнивает с актуальным прайсом/условиями в вашей базе.
Зачем: одна придуманная скидка в объявлении может стоить дороже, чем весь поток генерации.
Типичная ошибка: надеяться, что «судья заметит». Лучше проверять числа алгоритмом и базой.
Мини-пример РФ: онлайн-школа сверяет проценты скидок и даты старта потока, чтобы не улетали старые условия.
Шаг 6. Подключите синтетические персоны для здравой критики
Что делаем: создаем несколько промптов-агентов под реальную ЦА: «Скептичный финансовый директор», «Импульсивная мама в декрете» и т.д. Каждая персона читает оффер и возвращает обратную связь.
Зачем: один и тот же текст по-разному воспринимается сегментами. Синтетические персоны дают быстрый стресс-тест.
Типичная ошибка: делать персонажей слишком общими. Чем конкретнее контекст, тем полезнее замечания.
Мини-пример РФ: для B2B SaaS отдельная персона проверяет, не звучит ли оффер как «инфобиз» и не вызывает ли отторжение у закупки.
Шаг 7. Используйте negative prompting как финальный краш-тест
Что делаем: просим AI-судью найти 5 причин, почему этот оффер не купят. И только потом просим предложить правки.
Зачем: критика по отказам подсвечивает слабые места лучше, чем общая оценка качества.
Типичная ошибка: просить только «улучшить» без списка проблем. Тогда улучшение косметическое.
Мини-пример РФ: перед публикацией в VK и Яндекс Директ прогоняют тексты через negative prompting, чтобы заранее увидеть триггеры недоверия и лишние обещания.
Чем прогонять evals: от Make.com до локальной фильтрации
Кому это сэкономит время и деньги
Автоматизированные evals полезны там, где много вариантов, есть риск юридических формулировок и нужна стабильность Brand Voice. Тест 1000 вариантов объявлений в Make.com по API часто обходится примерно в $10-20, а неудачный запуск в рекламной сети может стоить уже тысячи долларов слитого бюджета.
- Маркетологам и performance-командам - меньше «проверок глазами» и быстрые итерации.
- Бренд-менеджерам - меньше конфликтов по тону и обещаниям, потому что правила формализованы.
- Редакторам и SMM - меньше правок на согласованиях, потому что черновики уже прошли фильтры.
- Командам с чувствительными данными - можно часть проверок держать локально через Ollama.
Частые вопросы
Evals — это просто модерация текста?
Нет. Модерация ловит явные нарушения. Evals - это систематическое тестирование по вашим критериям (Brand Voice, боли ЦА, юридическая чистота, структура оффера), часто с баллами и причинами отказа.
Насколько можно доверять LLM-as-a-Judge?
По данным исследований (например, LMSYS), топовые модели уровня GPT-4 согласуются с оценками экспертов-людей примерно в 85-90% случаев при оценке качества текста. На практике это означает: судья хорошо отсекает мусор, но правила и формат шкалы все равно нужно настраивать.
Как ускоряется подготовка кампаний?
Автоматизированные evals сокращают цикл подготовки контента с 3-5 дней согласований до 15-30 минут автоматического тестирования, если критерии и сценарий уже собраны.
Что делать, если AI придумывает скидки и условия?
Ставить проверку чисел и условий через базу: сценарий Make.com извлекает числа из текста и сверяет с актуальным прайс-листом или условиями в таблице/CRM. Это надежнее, чем надеяться на «внимательность» модели.
Зачем нужны синтетические персоны, если есть реальные клиенты?
Чтобы не ждать реакцию рынка. Персоны помогают быстро поймать возражения и триггеры недоверия до запуска, особенно когда вы тестируете много вариантов креативов и офферов.
Можно ли тестировать не только тексты, но и баннеры?
Да. С моделями с поддержкой Vision делают визуальные evals: читаемость текста, попадание в цветовую гамму бренда, первичный контроль композиции без участия дизайнера на каждом варианте.
Когда имеет смысл уходить в локальные модели (Ollama)?
Когда есть чувствительные данные и вы не хотите отправлять черновики на внешние серверы. Часто локальную модель используют для первичной фильтрации, а финальную оценку качества отдают более сильному облачному судье.
Где у вас чаще всего ломается контент: офферы, тон бренда или цифры и условия? Подпишитесь на канал - буду показывать рабочие сценарии Make.com для evals и тестирования нейросетей в маркетинге.
#маркетинг, #нейросети, #автоматизация
AI kontent Zavod:
Связаться с Андреем
Email
Заказать Нейро-Завод
Нейросмех YouTube
Нейроновости ТГ
Нейрозвук ТГ
Нейрохолст ТГ