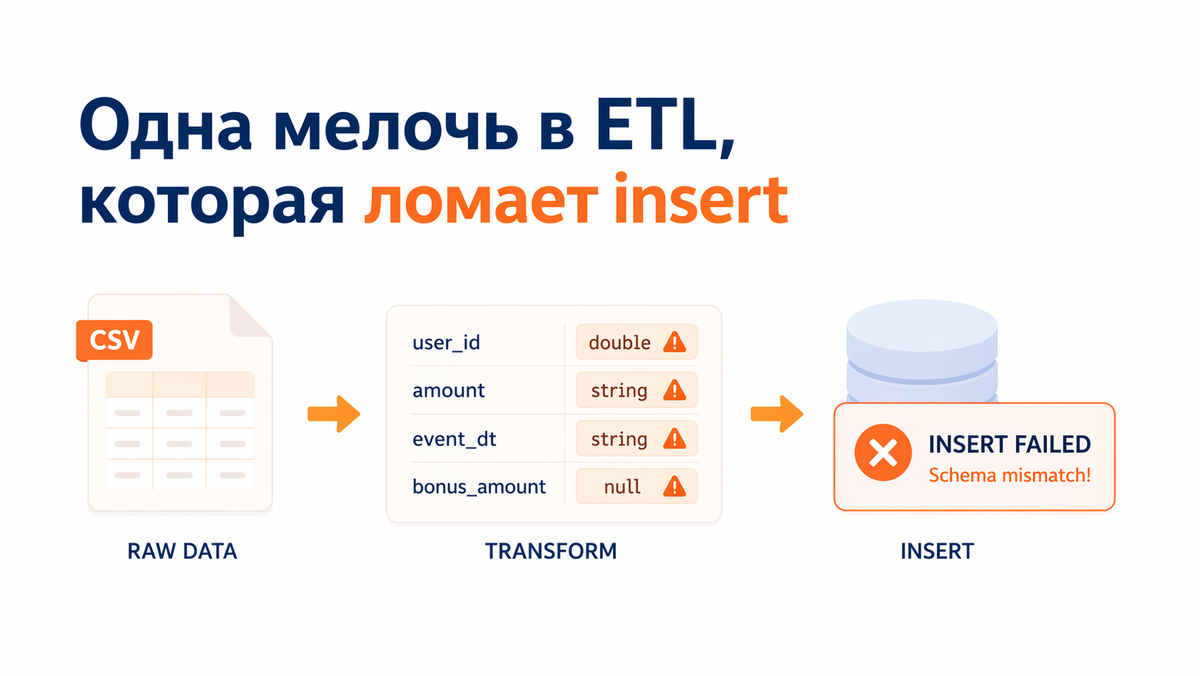
Есть мелочь, на которой пайплайн может споткнуться вообще в тупом месте.
Недавно словил неприятную ошибку в трансформации. Логов было мало, по ним быстро не читалось, где именно всё поехало, а на вставке в следующий слой данные начали вести себя не так, как я ожидал. После нескольких проверок причина оказалась довольно приземлённой: часть колонок приехала не в тех типах, которые должны были быть на выходе.
С тех пор я всё чаще явно привожу типы в ETL и заранее фиксирую схему. Особенно в местах, где дальше будет insert, union, промежуточная витрина или слой, от которого уже зависят следующие расчёты.
Где это всплыло
В трансформациях легко привыкнуть писать просто: column
И пока всё работает, кажется, что этого достаточно. Но если дальше колонка должна лечь в конкретный тип, лучше сразу привести её явно.
Например, если на выходе нужна строка:
CAST(column AS STRING) AS column
Если колонка пока пустая, но дальше она должна существовать в схеме как DECIMAL(38,2), я тоже задаю тип сразу:
CAST(NULL AS DECIMAL(38,2)) AS column
Это нормальный приём, когда нужно добавить пустую колонку нужного типа, чтобы дальше схема совпала с целевой таблицей или с другой частью union.
Почему это полезно
Самая неприятная часть таких ошибок в том, что они не всегда выглядят как ошибка в логике. Запрос может быть нормальный, расчёт может идти, данные могут читаться, а дальше всё начинает ломаться на стыке слоёв.
Где-то не совпал тип при вставке.
Где-то union начал ругаться или привёл данные не так, как хотелось.
Где-то пустая колонка осталась просто NULL, без нормального типа, и дальше это вылезло уже в другом месте.
Когда схема задана явно, таких сюрпризов меньше. В коде сразу видно, какой слой ты хочешь получить на выходе, и проще проверить, что он действительно совпадает с ожиданием.
То же самое в Spark
В Spark я тоже стараюсь не надеяться на автоматическое определение типов, особенно когда читаю csv или другой сырой источник. Там легко получить ситуацию, когда одна колонка стала string, другая double, дата прочиталась не так, как ожидалось, а дальше ты уже разбираешься не с бизнес-логикой, а с тем, как Spark распознал входные данные.
Для таких случаев лучше сразу задать схему:
from pyspark.sql.types import (
StructType,
StructField,
StringType,
DecimalType,
TimestampType
)
schema = StructType([
StructField("user_id", StringType(), True),
StructField("amount", DecimalType(38, 2), True),
StructField("event_dt", TimestampType(), True)
])
df = (
spark.read
.option("header", True)
.schema(schema)
.csv("/path/to/file.csv")
)
Так сразу понятно, какие типы я ожидаю на входе. Для junior DE это хорошая привычка: не просто читать файл и смотреть, что получилось, а заранее думать, какие данные должны прийти в расчёт.
Что я теперь проверяю
После этой истории я стал внимательнее смотреть на типы в местах, где данные переходят из одного слоя в другой. Если коротко, то проверяю три вещи: какая схема пришла на вход, какая схема должна быть на выходе и нет ли пустых колонок, которым нужно сразу задать конкретный тип.
Это особенно полезно перед вставкой в целевую таблицу, перед union нескольких датафреймов или запросов, перед сборкой витрины и в местах, где данные дальше будут использоваться в другом инструменте.
Для себя я это сформулировал просто: если я уже знаю, какой тип должен быть у колонки на выходе, лучше задать его сразу. Это занимает немного времени, но потом сильно экономит силы на разборе ошибок, где по логам сначала вообще непонятно, что произошло.
Если вам близки такие разборы по SQL, Spark и Data Engineering, подписывайтесь. Дальше буду чаще показывать рабочие кейсы из ETL, DWH и витрин.