Реальные тесты на RTX 4060 (8 ГБ) и 24 ГБ ОЗУ. Честные цифры, никакой магии. И да — модель не зависла даже на 800К
1. Вступление
Все любят локальные LLM за приватность, но мало кто честно говорит о границах. Сколько контекста можно дать модели, чтобы она не превратилась в черепаху? Где та грань, после которой скорость падает в 5 раз, а память уходит в оперативку?
Я взял Nemotron 3 Nano 4B в квантизации Q8_0, посадил её на связку RTX 4060 (8 ГБ VRAM) + 24 ГБ ОЗУ и прогнал через 10 тестов — от скромного 1К токенов до экстремальных 800К.
Результаты вас удивят. Спойлер: качество ответа не деградирует даже на пределе. А вот скорость и память — совсем другая история.
2. Условия эксперимента (чтобы было честно)
- Модель: Nemotron 3 Nano 4B
- Квантизация: Q8_0
- Видеокарта: RTX 4060 (8 ГБ VRAM)
- Оперативная память: 24 ГБ ОЗУ
- Инструмент: LM Studio
- Тестовый промт: «Опиши историю ИИ с 1950 года — 2000 слов, структура: десятилетие — событие — значение»
- Фоновые процессы: Браузер (3 окна), музыка, Parsec, антивирус, лаунчер
Почему честно: тесты проводились не на голой системе, а в реальных условиях — с музыкой, удалёнкой и открытыми вкладками. Так работает 99% пользователей.
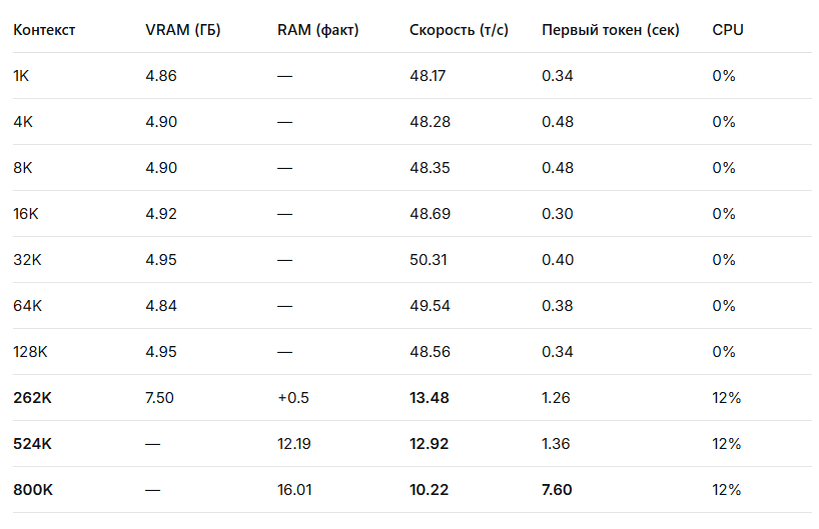
3. Сводные результаты (таблица)
4. Анализ результатов (что всё это значит)
Чтобы вам было проще понять таблицу, я разбил её на три зоны.
🟢 Зелёная зона (1K – 128K токенов) — ИДЕАЛ
Это комфортная зона для повседневной работы. Модель полностью помещается в видеопамять, процессор не используется, скорость максимальная.
- Память: Стабильно ~4.9 ГБ VRAM.
- Скорость: Космические 48-50 токенов в секунду.
- Первый токен: Мгновенно, 0.3-0.5 секунды.
- Вердикт: Выставляйте контекст до 128K и работайте в удовольствие.
🟡 Жёлтая зона (262K – 524K токенов) — ТЕРПИМО
Здесь модель начинает выходить за пределы видеопамяти и использовать оперативку. Скорость падает кардинально.
- Память: Резкий скачок до 7.5+ ГБ (VRAM закончилась).
- Скорость: Падение в 3.5-4 раза (до ~13 т/с).
- Первый токен: Заметная задержка ~1.3 секунды.
- Вердикт: Терпимо для анализа больших документов, если вы готовы ждать.
🔴 Красная зона (800K токенов) — ЭКСТРИМ
Это предел возможностей такой конфигурации ПК. Система не зависает, но работать в реальном времени невозможно.
- Память: Почти 16 ГБ общей памяти (VRAM + RAM).
- Скорость: Падение в 5 раз (всего 10 т/с).
- Первый токен: Очень долго — 7.6 секунд ожидания.
- Вердикт: Только для научных экспериментов или когда очень нужно, а другого ПК нет.
5. Что происходит с качеством ответа?
А вот это самое интересное. Модель не глупеет даже на 800K токенов.
- 1K–8K: Чётко следует структуре, без воды.
- 16K–32K: Начинает добавлять этические отступления, может вежливо спросить «нужны ли ссылки?»
- 64K–128K: Ответы становятся более развёрнутыми, но связность и логика сохраняются.
- 262K–800K: Модель пишет длинно, с фантазией, иногда уходит в далёкое будущее — но остаётся осмысленной и грамотной.
Главный вывод: качество не деградирует. Страдает только скорость и комфорт использования.
6. Хотите увидеть ответ модели?
Вместо того чтобы публиковать простыню текста здесь (ответ на 128K токенов занимает несколько экранов), я выложил полный ответ Nemotron в моём сообществе ВК.
Там вы увидите:
- как модель структурирует историю ИИ по десятилетиям
- какие ключевые события она выделяет
- как меняется стиль при увеличении контекста
👉 Перейти в ВК и прочитать ответ → https://vk.com/local_mozg
Подписывайтесь, чтобы не пропустить новые тесты и разборы.
7. Мои личные рекомендации
На основе этого эксперимента я сделал простые правила для себя:
- Для повседневных вопросов, чат, код - беру контекст до 128К (зелёная зона);
- Для анализа больших документов (книга, отчёты) - до 262К, понимая что скорость снизиться ( жёлтая зона);
- Для экспериментов, научных данных, ведения документов разработки - можно до 800К, модельне упадёт ( красная зона);
Золотое правило: держитесь в пределах видеопамяти. Как только модель начинает лезть в оперативку - скорость падает в катастрофически.
8. Что дальше?
Этот тест — только начало. В следующих статьях я:
- сравню Nemotron с другими моделями (Qwen, Mistral, Llama)
- покажу, как квантизация влияет на скорость и память
- расскажу, как я встроил эту модель в корпоративный мессенджер
Подписывайтесь на «Локальный мозг», чтобы не пропустить.
👉 ВК: https://vk.com/local_mozg
👉 Дзен: https://dzen.ru/lokal_mozg
Прохор
Инженер приватных AI-систем
🧷 Теги для Дзена
#Nemotron #локальныйИИ #LLM #тестирование #контекст #RTX4060 #нейросети #бенчмарк