
Извлечение текста с сайтов в прошлом было довольно простым процессом. Вы просто брали HTML, вытаскивали текст и на этом заканчивали работу. В 2026 году всё работает совсем иначе.
Теперь это больше похоже на полноценную систему. Вы не просто извлекаете текст. Вы работаете с автоматизацией, браузерной инфраструктурой и пытаетесь понять, как вообще использовать полученные данные.
Если вы строите датасеты, занимаетесь SEO-исследованиями или работаете с арбитражем трафика, парсинг — это только одна часть процесса. Настоящая ценность появляется на этапе обработки и применения данных.、
Что на самом деле означает парсинг сейчас
Когда говорят «вытащить весь текст с сайта», всё звучит просто. Но на практике это несколько уровней работы.
Нужно получить чистый читаемый контент без мусора вроде меню, рекламы и навигации. Затем масштабировать сбор на множество страниц или даже целые сайты. И после этого структурировать данные так, чтобы их можно было использовать в SEO или монетизации.
Дополнительно многие начали отслеживать, как этот контент работает, и подключать его к рекламным системам и воронкам.
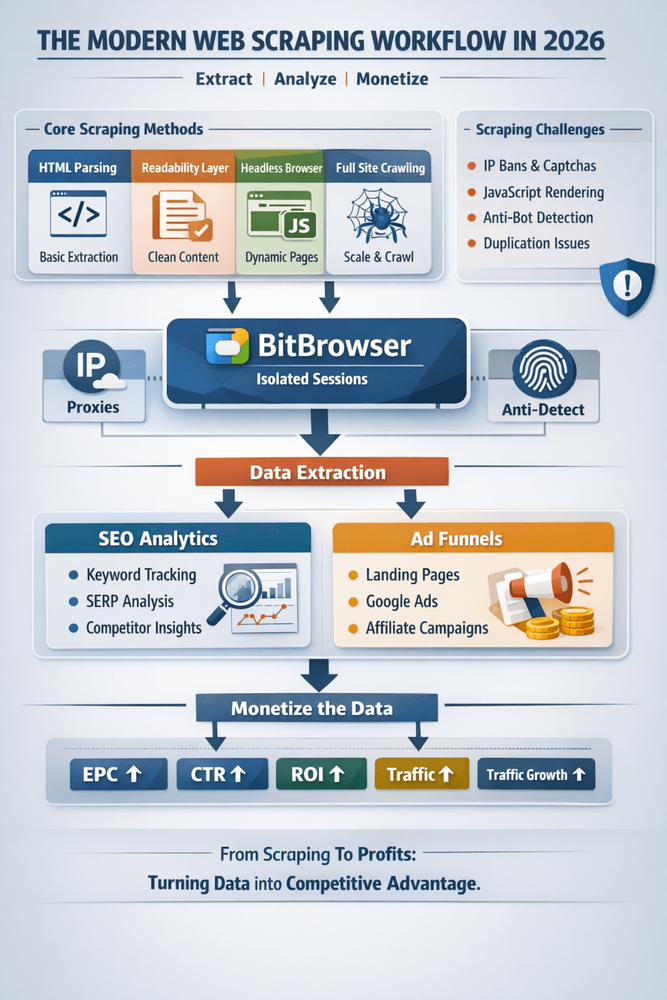
Основные способы парсинга
На базовом уровне всё ещё используется HTML-парсинг. Запрос страницы, разбор HTML и извлечение текста. Это быстро и подходит для простых статических сайтов, но современные веб-приложения часто этим не ограничиваются.
Поэтому используется извлечение контента через readability-инструменты. Они помогают выделить основную статью и убрать всё лишнее. Это особенно важно для SEO-данных, где важна чистота контента.
Для более сложных сайтов применяются headless-браузеры. Они загружают страницу как реальный пользователь, выполняют JavaScript и позволяют взаимодействовать с интерфейсом. Это необходимо для современных SPA-сайтов и динамического контента.
Следующий уровень — это краулинг сайтов целиком. Фреймворки вроде Scrapy позволяют обходить тысячи страниц, следовать по внутренним ссылкам и собирать структурированные данные для анализа или исследований.
Где здесь BitBrowser
Когда вы начинаете масштабировать процессы, появляются ограничения. Блокировки IP, антибот-системы, лимиты запросов и отслеживание браузерных отпечатков.
В таких условиях используют BitBrowser как часть инфраструктуры.
Суть в том, что вы создаёте изолированные браузерные профили. У каждого профиля свой цифровой отпечаток, cookies и поведение. Это снижает риск связывания сессий между собой.
Дополнительно можно подключать разные прокси к каждому профилю и работать с разными гео. Это помогает распределять нагрузку и снижает вероятность блокировок.
На практике схема выглядит так. Вы парсите страницы конкурентов, собираете ключевые слова и контент, передаёте это в систему создания лендингов и запускаете рекламу. BitBrowser используется как связующее звено для безопасной работы с множеством аккаунтов и сессий.
То, что большинство игнорирует
Сам по себе парсинг почти ничего не даёт без анализа.
Главная ценность появляется тогда, когда вы начинаете понимать, что именно вы собрали.
Можно извлекать ключевые слова и определять их намерение, например информационное или покупательское. Можно анализировать структуру страниц, заголовки, длину текста и плотность ключевых слов.
Если добавить данные из поисковой выдачи, такие как позиции и примерный трафик, получается уже не просто текст, а SEO-инсайты.
Ещё один важный момент — анализ конкурентов. Сравнивая несколько сайтов, можно увидеть, какие страницы у них работают лучше, какие воронки они используют и какие темы недооценены на рынке.
Как выглядит полный процесс
Типичный рабочий процесс сейчас выглядит так.
Сначала вы парсите сайты конкурентов и собираете контент и ключевые слова.
Затем анализируете данные и находите высокоценные поисковые запросы.
После этого структурируете информацию и создаёте лендинги в масштабе.
Далее запускаете рекламные кампании под эти запросы.
И параллельно управляете аккаунтами через изолированные браузерные среды.
В итоге парсинг становится частью бизнес-системы, а не просто технической задачей.
Основные сложности
Проблемы возникают постоянно. Дублированный контент, сложный JavaScript, антибот-защита и шумные данные.
Но самая большая сложность не в сборе информации, а в том, чтобы превратить её в действие.
Что работает лучше всего
Важно работать не с сырыми данными, а со структурированными.
Парсинг должен идти вместе с SEO-аналитикой, а не отдельно.
При масштабировании полезно использовать изолированные браузерные окружения и не делать слишком агрессивные запросы.
Также стоит сохранять метаданные вроде URL, заголовков и времени сбора, а дубликаты удалять как можно раньше.
Реальность 2026 года
Парсинг больше не выглядит как простое «взять текст с сайта».
Это уже система, которая собирает, анализирует и монетизирует данные.
Итог
Если объединить инструменты парсинга, инфраструктуру вроде BitBrowser, SEO-аналитику и рекламные системы, вы получаете не просто данные.
Вы получаете преимущество.
И в 2026 году выигрывают не те, кто собирает больше информации, а те, кто умеет её правильно использовать.