
После запуска продвижения в AI-ответах работа не заканчивается. Она только становится измеримой. Контроль AI-продвижения — это регулярная проверка того, как AI-ответы показывают бренд, в каких сценариях он появляется, какие формулировки использует и не уходит ли результат в сторону от бизнес-цели. На этапе принятия решения это особенно важно: собственник, CEO или CMO не покупают «активность», им нужен управляемый эффект, который можно сравнить с планом, конкурентами и прошлой точкой. Иначе продвижение превращается в красивый отчёт без решения.
Что происходит после запуска
После старта продвижения в AI-ответах начинается не фаза ожидания, а фаза контроля.
Под поддержкой после запуска понимается не «что-то поправить потом», а системная работа с тем, как AI-выдача меняется со временем.
На практике это выглядит просто. Запуск прошёл. Дальше важно понять, где бренд уже появился, где исчез, и в каких запросах AI начал отвечать мимо задачи.
Как понять, что продвижение работает
Работающее продвижение в AI-ответах видно по повторяемости результата. Не по одному удачному ответу, а по серии.
Признаки стабильности::
- бренд появляется в AI-ответах по целевым запросам;
- упоминания бренда повторяются без резких провалов;
- формулировки релевантны нужной теме;
- ответ AI помогает сценарию выбора, а не уводит в общий обзор;
- видимость бренда растёт на тех запросах, где она и должна расти.
Продвижение в AI-ответах работает, если контент бренда стабильно попадает в retrieval по целевым запросам и достаточно плотен по фактам, чтобы быть использованным в ответе — это можно воспроизвести на нескольких запросах и площадках, а не поймать один раз, как удачный скриншот в пятницу вечером.
Я видел проекты, где бренд стабильно всплывал в одном сценарии и полностью пропадал в соседнем. Формально — рост есть. По факту — нет.
Что нужно контролировать после запуска
Контроль после запуска не сводится к одной цифре. Видимость бренда, упоминания бренда и качество контекста — разные вещи.
Что нужно проверять регулярно:
- видимость бренда в AI-ответах по целевым запросам;
- упоминания бренда в ответах и их частоту;
- контекст, в котором бренд упоминается;
- динамику по ключевым запросам;
- смещение ответа из нужной темы в нейтральную или конкурентную;
- изменения по площадкам и источникам, если AI опирается на них;
- стабильность ответа в течение 2–4 недель.
Если бренд стал появляться чаще, но в нерелевантном контексте, это не победа. Это сигнал. AI использовал контент бренда, но не тот фрагмент и не в том сценарии.
Мини-чек-лист контроля
- Проверить топ-10 целевых запросов.
- Зафиксировать, где есть упоминания бренда.
- Сравнить контекст ответа с целевым сценарием.
- Отметить провалы по запросам и площадкам.
- Посмотреть, не сместился ли AI в сторону конкурентов.
По каким метрикам оценивать результат
Здесь легко ошибиться. Принято считать, что нужна одна общая метрика. Но это работает только, если бизнесу всё равно, что именно улучшилось. А обычно не всё равно.
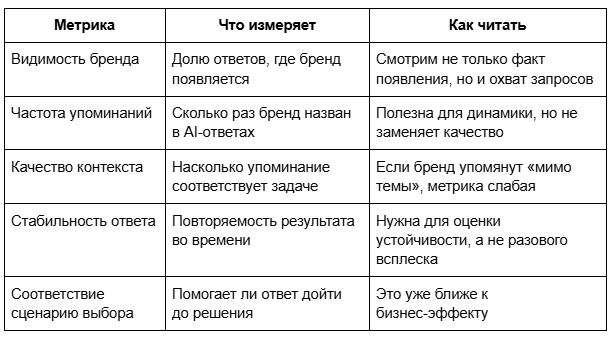
Не сводите всё к одной цифре. Видимость без релевантности — пустой шум. Упоминания без стабильности — случайность. Контекст без динамики — красивый, но бесполезный скрин.
Важно: LLM не ранжирует бренды по «авторитету» — она использует наиболее релевантный фрагмент внутри переданного контекста. Поэтому рост упоминаний без роста релевантности фрагментов — не сигнал успеха.
В одном проекте рост упоминаний составил 28% за месяц. Звучит неплохо. Но половина этих упоминаний шла в общих обзорах, а не в сценариях выбора.
Вывод: эффект есть, но не коммерческий.
С чем сравнивать результат
Сравнивать результат нужно не с ощущением, а с базой.
Было / стало показывает прирост.
Конкурент показывает, хватает ли этого прироста на рынке.
Цель показывает, стоит ли продолжать без пересмотра.
Когда нужна поддержка и пересмотр стратегии
Поддержка нужна не тогда, когда «что-то не нравится», а когда есть повторяющийся сбой.
Триггеры такие:
- нет роста по целевым запросам 3–4 недели;
- упоминания бренда стали нестабильными;
- AI даёт невыгодный ответ или уводит к конкуренту;
- релевантность формулировок падает;
- один и тот же запрос даёт разные сценарии ответа;
- результат есть, но он не связан с бизнес-целью.
Пересмотр стратегии нужен, если контроль показывает системное смещение результата. Не косметика. Не подкрашивание цифр. Именно пересмотр.
Специфика для РФ
На российском рынке контроль продвижения в AI-ответах сложнее по простой причине: поведение AI-выдачи менее предсказуемо, а источники и сценарии меняются быстрее, чем хочется бизнесу.
Есть и практические ограничения:
- у брендов часто короткий горизонт ожиданий;
- решение ждут не через квартал, а через недели;
- российские запросы сильнее зависят от локального контекста;
- одно и то же продвижение в AI-ответах может работать по-разному на разных моделях и сервисах — ChatGPT, Perplexity, Claude, Gemini используют разные RAG-архитектуры и разные индексы, поэтому результат на одной платформе не переносится автоматически на другую.
Это влияет на контроль через частоту проверок. Рабочий интервал наблюдения — 7–14 дней; это экспертная оценка, а не гарантия: реальная скорость изменений зависит от конкретной площадки и частоты обновления её индекса.
Что важно для decision-аудитории
Владельцу бизнеса, CEO и CMO важно не «есть ли активность», а можно ли управлять результатом.
Им нужны три вещи:
- управляемость — понятно, что именно влияет на AI-ответы;
- предсказуемость — результат повторяется;
- измеримость — эффект можно сравнить с целью и бюджетом.
Именно это влияет на решение о продолжении работ. Не отчёт ради отчёта, а ответ на вопрос: даём ли мы деньги туда, где есть повторяемый эффект.
FAQ
Когда проверять результат после запуска?
Через 7–14 дней уже видны первые сигналы, а устойчивую картину лучше оценивать за 3–4 недели. Скорость изменений зависит от платформы: разные AI-сервисы обновляют индексы с разной периодичностью.
Что важнее: видимость или упоминания бренда?
Оба показателя важны. Но ни один из них не является основным: решающую роль играет релевантность фрагмента контента и его попадание в retrieval. Видимость показывает охват, упоминания — частоту, но без попадания в нужный контекст они мало что значат.
Когда нужна поддержка после запуска?
Когда рост остановился, упоминания стали нестабильными или AI начал давать невыгодные ответы.
С чем сравнивать результат продвижения в AI-ответах?
С исходной точкой, целевыми запросами, конкурентами и планом по видимости. Обязательно — по разным платформам отдельно: ChatGPT, Perplexity, Claude и другие системы дают разный результат для одного и того же бренда.
Можно ли оценивать всё одной метрикой?
Нет. LLM не ранжирует по авторитету домена — она выбирает наиболее плотный и релевантный фрагмент внутри своего контекста. Один показатель не отражает видимость, контекст и стабильность одновременно.
Мы в социальных сетях: YouTube VK Телеграм-бот
Другие полезные материалы на канале: