Однажды разработчик пишет простое выражение для проверки email. Тесты проходят. Код уходит в продакшен. А потом сервер зависает на 30 секунд при обработке одной строки. Не гипотетически. В 2016 году именно так лёг Stack Overflow. Причина: одна регулярка в валидации. Называется это бэктрекинг - он же катастрофический откат, он же ReDoS.
Как движок думает
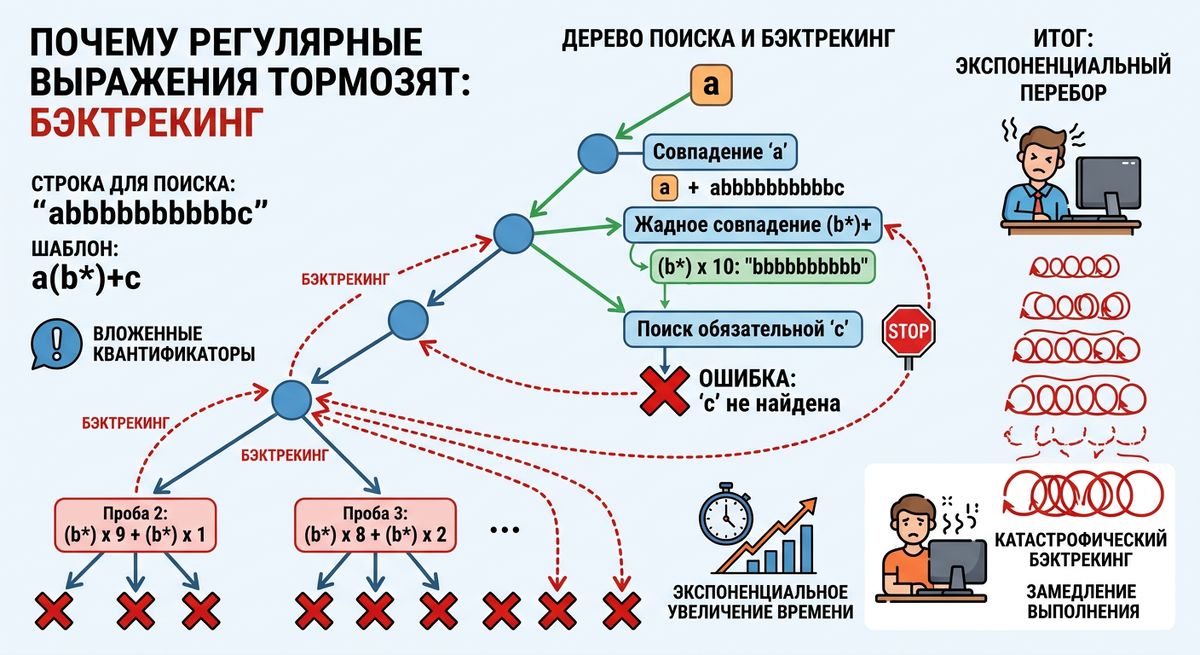
Смотрите вначале когда вы передаёте паттерн в re.search(): движок не просто "ищет". Он пробует. Берёт позицию в строке, пробует совместить с паттерном - не получилось, сдвигается на символ вправо, пробует снова. Внутри работает НФА - недетерминированный конечный автомат. Он умеет откатываться назад и пробовать альтернативы.
Это и есть бэктрекинг. В 90% случаев он отрабатывает за миллисекунды. Но есть конструкции которые заставляют его перебирать миллиарды вариантов.
Когда начинается проблема
import re
# Не запускай это без таймаута
pattern = re.compile(r"(a+)+b")
text = "aaaaaaaaaaaaaaaaaaaaaaaac" # символ c в конце, не b
result = pattern.search(text)
Питон зависнет. Т.к. движку надо перебрать все способы разбить последовательность "a" на группы: (a)(aaa), (aa)(aa), (a)(a)(aa) и т.д. При 20 символах количество вариантов уже огромное. При 30 это несовместимо с жизнью сервера.
Тут есть нюансы. Первый: проблема возникает только при несовпадении. Т.е. если строка совпадает полностью - всё быстро. Второй: именно поэтому ReDoS используют как атаку. Подают специально сконструированные строки которые не совпадают и ждут пока сервер упадёт.
Три паттерна-виновника
Здесь мы во-первых смотрим на структуру выражения. Проблему вызывают три вещи:
Вложенные квантификаторы. Это (a+)+ или (a*)*. Группа с квантификатором внутри квантификатора. Движок перебирает все комбинации разбивки.
Чередование с перекрытием. Паттерн вида (a|aa)+. Движок не знает какую ветку выбрать. При откате пробует другую. При новом откате снова.
Жадные квантификаторы на широких классах. Паттерн .* foo.* на длинной строке без foo заставит движок прошагать всё несколько раз.
Как я уже отмечал: в учебных примерах это незаметно т.к. строки короткие. В продакшене - другая история.
Как починить
Давайте для начала про самое простое. Часто проблема в избыточной вложенности которая ничего не добавляет:
import re
# Было - создаёт экспоненциальный перебор
pattern_bad = re.compile(r"(a+)+b")
# Стало - то же самое, без проблемы
pattern_good = re.compile(r"a+b")
text = "aaaaaaaaaaaaaaaaaaaaaaaac"
print(pattern_good.search(text)) # None, мгновенно
(a+)+ и a+ ищут одно и то же. Но первый вариант создаёт перебор. Т.е. прежде чем усложнять паттерн: проверь нельзя ли упростить. Банально, но работает.
Атомарные группы: ядерный вариант
Атомарные группы запрещают движку откатываться назад внутри группы. Т.е. если группа один раз совпала: зафиксировано, пути назад нет. В стандартном re их нет. Но это лишь ограничение стандартной библиотеки. Т.к. есть regex (устанавливается через pip): он поддерживает атомарные группы через синтаксис (?>...).
import regex # pip install regex
pattern = regex.compile(r"(?>a+)+b")
text = "aaaaaaaaaaaaaaaaaaaaaaaac"
result = pattern.search(text)
print(result) # None, но быстро
Разница: секунды против миллисекунд. Это не преувеличение.
Ленивые квантификаторы как частичная защита
Ленивый квантификатор - звёздочка или плюс со знаком вопроса. Вместо .* пишешь .*?. Жадный захватывает максимум и откатывается. Ленивый захватывает минимум и расширяется.
import re
text = "<div>один</div><div>два</div>"
greedy = re.findall(r"<div>.*</div>", text)
lazy = re.findall(r"<div>.*?</div>", text)
print(greedy) # ["<div>один</div><div>два</div>"]
print(lazy) # ["<div>один</div>", "<div>два</div>"]
Но это лишь частичная защита. Ленивый квантификатор меняет результат, не только скорость. И от вложенных групп не спасает.
Таймаут: минимальная страховка
Начиная с Питон 3.11 можно задать таймаут прямо в функции поиска:
import re
try:
result = re.search(
r"(a+)+b",
"a" * 30 + "c",
timeout=1.0 # максимум 1 секунда
)
except TimeoutError:
print("Паттерн завис, надо переписать")
По идее это должно быть обязательной практикой при работе с пользовательским вводом. Т.к. пользователи умеют подсовывать неожиданные строки. Иногда случайно. Иногда нет.
Как проверить свой код
Давайте проверим что у вас нет скрытых мин в кодовой базе. Пройдись по всем паттернам и ищи:
- Группы с квантификаторами внутри других квантификаторов - (что_угодно+)+ или (что_угодно*)*.
- Чередование где варианты перекрываются - (ab|abc)+ т.к. ab является частью abc.
- Широкие классы без якорей на пользовательском вводе - .+ или .* без ^ и $ на входных данных.
import re
# Паттерны которые стоит пересмотреть
bad_patterns = [
r"(w+)+", # вложенный квантификатор
r"(a|aa)+", # перекрывающееся чередование
r".*foo.*", # широкий класс без ограничений
]
# Предсказуемые варианты
good_patterns = [
r"w+", # без вложенности
r"a+", # без чередования
r"[^f]*foo", # сужен класс до нужного
]
Значит для тех кто пишет код с пользовательским вводом: это не теория. Это реальный вектор атаки.
Системный подход к отладке паттернов и ещё 511 интерактивных задач ждут тут: https://stepik.org/a/271005
72 урока по Питон 3.14. 428 тестов. Три уровня сложности. Проверка автоматическая. 6 справочников: включая раздел по отладке паттернов.