
Потребность и актуальность
Чем
больше мы начинаем использовать свое собственное облако, тем больше
файлов туда загружаем. Из этого следует, что нам требуется быстрый поиск
по файлам и по возможности онлайн просмотр и редактирования файлов,
чтобы тратить минимум времени на операции поиска и
просмотра/редактирования документов. В этой статье постараемся настроить
полнотекстовый поиск (Elasticsearch) и on-line просмотр/редактирование файлов через Onlyoffice.
docker-compose
- Создаем необходимые файлы:
# Создаем файлы
touch {docker-compose.yml,.env}
Структура .env:
ONLYOFFICE_SECRET=<your_secret>
- Перед запуском Docker устанавливаем в Nextcloud:
# Устанавливаем необходимые компоненты для onlyoffice
docker exec --user www-data nextcloud-app php occ app:install onlyoffice
# Установка онлайн-редактора
docker exec --user www-data nextcloud-app php occ app:install documentserver_community
# Отключаем, в случае наличия
docker exec --user www-data nextcloud-app php occ app:disable fulltextsearch_sql
# Устанавливаем необходимые компоненты для elasticsearch
docker exec --user www-data nextcloud-app php occ app:install fulltextsearch
docker exec --user www-data nextcloud-app php occ app:install files_fulltextsearch
docker exec --user www-data nextcloud-app php occ app:install fulltextsearch_elasticsearch
# Устанавливаем страницу поиска
docker exec --user www-data nextcloud-app php occ app:install thesearchpage
Устанавливаем ПО для OCR:
# Войти в контейнер как root
docker exec -it --user root nextcloud-app /bin/bash
# Обновить список пакетов и установить Tesseract с русским и английским языками
apt-get update
apt-get install -y tesseract-ocr tesseract-ocr-eng tesseract-ocr-rus ocrmypdf
# Проверить, что установка прошла успешно
tesseract --version
# Выйти из контейнера
exit
Активируем приложение для OCR:
docker exec --user www-data nextcloud-app php occ app:enable files_fulltextsearch_tesseract
- В docker-compose.yml запускаем только необходимые сервисы, структура docker-compose.yml:
services:
elasticsearch:
image: nextcloud/aio-fulltextsearch:latest
container_name: nextcloud-elasticsearch
stop_grace_period: 3m
hostname: elasticsearch
# depends_on:
# - db
# - app
environment:
- ES_JAVA_OPTS=-Xms4g -Xmx4g
- bootstrap.memory_lock=true
- cluster.name=nextcloud
- discovery.type=single-node
- logger.org.elasticsearch.discovery=WARN
- http.port=9200
- xpack.license.self_generated.type=basic
- xpack.security.enabled=false
- indices.query.bool.max_clause_count=8192
volumes:
- ./config_elasticsearch:/usr/share/elasticsearch/data:rw
ports:
- 9200:9200
- 9300:9300
dns:
- 9.9.9.9
restart: unless-stopped
ulimits:
memlock:
soft: -1
hard: -1
cap_add:
- IPC_LOCK
deploy:
resources:
limits:
cpus: '4'
memory: 8192m
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9200/_cluster/health?local=true"]
interval: 30s
timeout: 10s
retries: 5
start_period: 40s
networks:
- default
onlyoffice:
container_name: onlyoffice-documentserver
image: onlyoffice/documentserver:latest
# depends_on:
# - db
# - app
restart: always
volumes:
- ./config_onlyoffice:/var/www/onlyoffice/Data
environment:
- JWT_ENABLED=true
- JWT_SECRET=${ONLYOFFICE_SECRET}
ports:
- '8080:80'
env_file: ".env"
networks:
- default
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost/welcome/"]
interval: 30s
timeout: 10s
retries: 5
start_period: 60s
networks:
default:
name: nextcloud-network
driver: bridge
attachable: true
Секцию depends_on в итоговом файле можно раскомментировать, так как мы ждем запуска базы данных и самого Nextcloud. Для elasticsearch секция dns
имеет важное значение, так как иначе Вы не сможете скачать образ из-за
«блокировок». Также важно, чтобы все контейнеры были в одной сети и за
это отвечает секция networks.
Проверка запуска:
- Onlyoffice: http://<your_ip>:8080/welcome/ - должны увидеть страницу приветствия Onlyoffice.
- Elasticsearch:
$ curl http://localhost:9200/
{
"name" : "elasticsearch",
"cluster_name" : "nextcloud",
"cluster_uuid" : "****************",
"version" : {
"number" : "8.17.3",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "***************",
"build_date" : "2025-02-28T10:07:26.089129809Z",
"build_snapshot" : false,
"lucene_version" : "9.12.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
Настройка поиска по файлам
Эти действия не влияют на полнотекстовый поиск, но сильно ускоряют поиск внутри самого Nextcloud.
# Настраиваем базу данных для поиска по файлам
docker exec -it nextcloud-postgres psql -U nextcloud -d nextcloud -c "CREATE EXTENSION IF NOT EXISTS pg_trgm;"
docker exec -it nextcloud-postgres psql -U nextcloud -d nextcloud -c "CREATE INDEX CONCURRENTLY IF NOT EXISTS fs_name_gin_trgm ON oc_filecache USING GIN (name gin_trgm_ops);"
docker exec -it nextcloud-postgres psql -U nextcloud -d nextcloud -c "CREATE INDEX CONCURRENTLY IF NOT EXISTS fs_path_gin_trgm ON oc_filecache USING GIN (path gin_trgm_ops);"
Настройка полнотекстового поиска
Настраиваем Elasticsearch:
# Выбираем платформу поиска
docker exec --user www-data nextcloud-app php occ config:app:set fulltextsearch search_platform --value="OCA\\FullTextSearch_Elasticsearch\\Platform\\ElasticSearchPlatform"
# Отключаем строку поиска
docker exec --user www-data nextcloud-app php occ config:app:set fulltextsearch app_navigation --value="0"
# Настройка ElasticSearch
docker exec --user www-data nextcloud-app php occ fulltextsearch_elasticsearch:configure '{"elastic_host": "http://nextcloud-elasticsearch:9200", "elastic_index": "cloud", "analyzer_tokenizer": "standard"}'
# Устанавливаем количество реплик равным 0
curl -X PUT "localhost:9200/cloud/_settings" -H 'Content-Type: application/json' -d '{"index": {"number_of_replicas": 0}}'
# Индексировать локальные файлы
docker exec --user www-data nextcloud-app php occ config:app:set files_fulltextsearch files_local --value="1"
# Индексировать внешние файлы
docker exec --user www-data nextcloud-app php occ config:app:set files_fulltextsearch files_external --value="1"
# Индексировать групповые папки
docker exec --user www-data nextcloud-app php occ config:app:set files_fulltextsearch files_group_folders --value="1"
# Максимальный размер файла для индексации (в МБ)
docker exec --user www-data nextcloud-app php occ config:app:set files_fulltextsearch files_size --value="50"
# Индексировать PDF
docker exec --user www-data nextcloud-app php occ config:app:set files_fulltextsearch files_pdf --value="1"
# Индексировать офисные документы
docker exec --user www-data nextcloud-app php occ config:app:set files_fulltextsearch files_office --value="1"
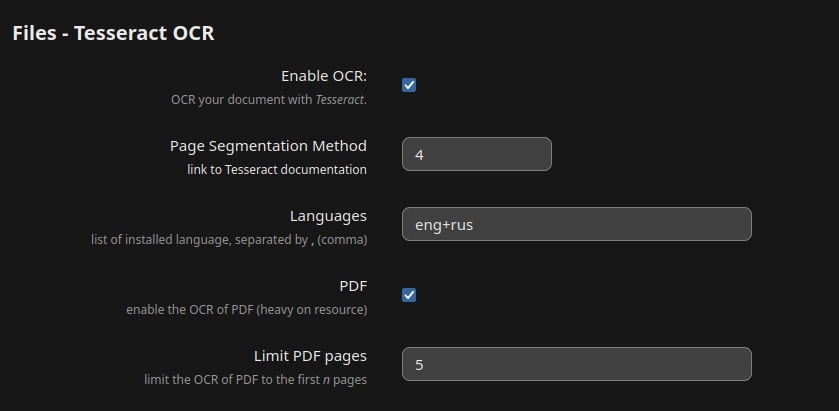
Для Tesseract
не понял, как сделать через команды, поэтому делаем через UI (Параметры
сервера -> Полнотекстовый поиск): Сброс индекса в случае его
наличия:
docker exec -it -u www-data nextcloud-app php occ fulltextsearch:stop
docker exec -it -u www-data nextcloud-app php occ fulltextsearch:reset
Создание файла стоп-слов:
mkdir -p config_elasticsearch/stopwords/
touch config_elasticsearch/stopwords/ru_RU.txt
echo "и\nв\nне\nна\nс\nпо\nчто" > config_elasticsearch/stopwords/ru_RU.txt
Запустить процесс индексирования в фоне:
# Запуск в фоне индексации
nohup docker exec -u www-data nextcloud-app php -d memory_limit=-1 occ fulltextsearch:index > /tmp/fulltext_index.log 2>&1 &
# Просмотр лога
tail -f /tmp/fulltext_index.log
Просмотр результатов индексирования:
$ curl http://localhost:9200/_cat/indices\?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size dataset.size
yellow open cloud V_uK0nSIQliHcQZfOJEEmA 1 1 111064 1 12.2gb 12.2gb 12.2gb
$ curl -s "http://localhost:9200/cloud/_count" | jq .count
111104
После окончания индексирования включаем индексацию измененных файлов:
# Создаем конфиг
$ sudo nano /etc/systemd/system/nextcloud-fulltext.service
[Unit]
Description=Nextcloud Full Text Search Live Worker
After=docker.service
Requires=docker.service
[Service]
Type=simple
ExecStart=/usr/bin/docker exec -u www-data nextcloud-app php -d memory_limit=-1 occ fulltextsearch:live
Restart=always
RestartSec=10
User=root
[Install]
WantedBy=multi-user.target
# Запустить сервис
$ systemctl daemon-reload
$ systemctl enable --now nextcloud-fulltext
# Перезапустить
$ sudo systemctl restart nextcloud-fulltext.service
# Посмотреть логи
sudo journalctl -u nextcloud-fulltext.service -f
В
процессе индексации столкнулся с такой проблемой, которую не знал, как
решить, и только после множества попыток и поисков ответов на вопросы
нашел решение. Оказывается, Elasticsearch очень плохо работает с большим
количеством мелких файлов, которые у меня были в папках .git и .env. Решил это созданием в этих папках файла .noindex, который указывает Elasticsearch не индексировать этот путь:
# Найти папки .git/.venv*/.env* и создать внутри .noindex
find /main/documents -type d -name ".git" -exec touch {}/.noindex \;
find /main/documents -type d -name ".venv*" -exec touch {}/.noindex \;
find /main/documents -type d -name ".env*" -exec touch {}/.noindex \;
Работа
с ошибками Elasticsearch отдельная тема, так как не нашел, как точечно
работать с ними. Если ошибка возникает, то она указывает на конкретный
идентификатор файла внутри базы данных Nextcloud.
# Пример ошибки в логе
┌─ Errors ────
│ Error: 4/4
│ Index: files:83013800
│ Exception: OCA\FullTextSearch_Elasticsearch\Vendor8\Elastic\Elasticsearch\Exception\ClientResponseException
│ Message: unknown error
│
│
└──
То есть Вы не можете по идентификатору понять, какой это файл, но есть способ, как увидеть путь к нему:
# Заходим в контейнер базы данных
$ docker exec -it nextcloud-postgres psql -U nextcloud -d nextcloud
# Выполняем запрос
SELECT fileid, path, name, size, mtime
FROM oc_filecache
WHERE fileid = 83013800;
# Удалить файл из индекса
docker exec -it nextcloud-elasticsearch curl -X DELETE "http://localhost:9200/cloud/_doc/files:83094143?pretty"
Также можно создать файл .noindex, если хотите исключить папку из индексирования.
Настройка онлайн-редактора
Параметры сервера -> ONLYOFFICE. В поле «Адрес ONLYOFFICE Docs» прописываем адрес нашего сервера http://<your_ip>:8080.
Далее можно настроить какие типы файлов открывать при необходимости или
ставить настройки по умолчанию. На этом настройка закончена.
Итог
В сухом остатке:
- Мы значительно ускорили поиск по файлам внутри самого Nextcloud, так как настроили соответствующие индексы.
- У нас появился полнотекстовый поиск по документам, в том числе по изображениям.
- У нас появилась удобная страница с выводом результатов поиска и взаимодействия с ним.
- Мы имеем возможность открывать и редактировать документы онлайн, без необходимости их скачивать к себе на устройство.
Ссылки:
- Как запустить прокси-сервер для сервисов?
- Как установить Docker?
- Как запустить сервис с собственным облаком?
*.wikipedia.org - РКН: иностранный владелец ресурса нарушает закон РФ.