🧠 In-Place TTT: LLM теперь учатся прямо во время разговора с вами
7 апреля 2026 команда ByteDance Seed и Peking University опубликовала исследование "In-Place Test-Time Training" — способ научить LLM обновлять свои знания прямо в процессе генерации ответа.
📍 Проблема: знания LLM "заморожены"
Обычная LLM работает так: обучилась на огромном датасете → веса зафиксированы → используется без изменений.
Проблема: после обучения модель не может "выучить" что-то новое прямо в диалоге. Если вы загружаете 100-страничный техдок, она загоняет его в контекст, но не "запоминает" — просто держит в оперативной памяти. Важные детали теряются, особенно из середины документа.
Старые попытки решить это (Test-Time Training) требовали перестройки архитектуры и переобучения модели с нуля — слишком дорого.
⚡️ Решение: используй то, что уже есть
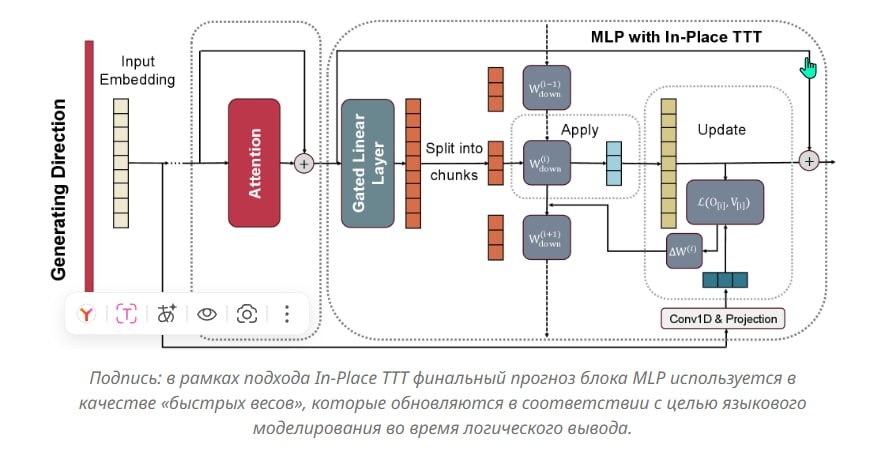
ByteDance нашли способ не добавлять новые слои, а переиспользовать MLP-блоки, которые есть в каждом Transformer.
Принцип простой:
- В MLP-блоке три матрицы весов
- Одну из них (W_down) сделали "быстрой" — она обновляется на лету
- Остальные остаются "медленными" (зафиксированными)
Пока модель читает ваш документ, она постепенно подстраивает эти "быстрые веса" под специфику текста.
🔧 Как это работает быстро
Обновлять веса после каждого слова — медленно. In-Place TTT обрабатывает текст кусками (512-1024 токенов):
- Читает кусок текста
- Обновляет веса на основе прочитанного
- Использует обновлённые веса для следующего куска
Это работает параллельно на GPU — скорость почти не падает.
💡 Учится предсказывать, а не просто запоминать
Ключевое отличие от старых методов: модель учится предсказывать следующий токен, а не просто "запоминать текущий".
Почему это важно: LLM работают как предсказатели следующего слова. In-Place TTT тренирует веса именно для этой задачи — получается эффективнее.
📊 Что показали тесты
Qwen3-4B + In-Place TTT:
✅На контексте 128k токенов: 77% точности vs 74.8% у обычной модели
✅На 256k токенов (экстраполяция): выигрыш сохраняется
Модель 4B, обученная с нуля:
✅Сложные научные вопросы (GPQA): +7.5 пунктов
✅Генерация кода: +3.1 пункта
✅Общие знания: +1.1 пункта
Главное: работает как drop-in замена — можно взять готовую модель и добавить TTT без переобучения.
🎯 Что это значит для пользователей
1️⃣ Работа с длинными документами: модель лучше запоминает детали из середины 100-страничных PDF, не теряет контекст.
2️⃣ Адаптация к специфике: если вы работаете с узкоспециализированными текстами (медицина, юриспруденция, код), модель подстраивается под терминологию прямо в процессе.
3️⃣ Шаг к постоянному обучению: вместо "обучили раз и навсегда" появляется возможность учиться постоянно, прямо в диалоге.
Попробуйте современные LLM в AI Wiz 2.0 — доступ из дашборда.
#AIWiz #ByteDance #InPlaceTTT #LLM #TestTimeTraining