Текст подготовил: Андрей Федорчук
Distillation-first AI-stack — это архитектура, где знания «тяжелой» LLM перегоняются в малые модели (SLM), а запросы в проде маршрутизируются по сложности. Выгода проста: оптимизация инференса дает минус 10-100x по стоимости, и качество на узких задачах часто даже растет.
Обычно в проде происходит так: один красивый прототип на GPT-4o превращается в счет за токены, который внезапно начинает жить своей жизнью. Потом команда «режет» контекст, урезает подсказки, выключает проверки и получает поток странных ответов.
Distillation-first подход решает это иначе: вы оставляете большую модель как «учителя» и страховку, а основную нагрузку сажаете на дешевые SLM. Ниже — 3 вывода, которые реально держат прод: как настроить каскадный роутинг, как собирать датасет через Make.com и как не утонуть в проверке качества.
Distillation-first AI-stack: 7 шагов до продовой экономии
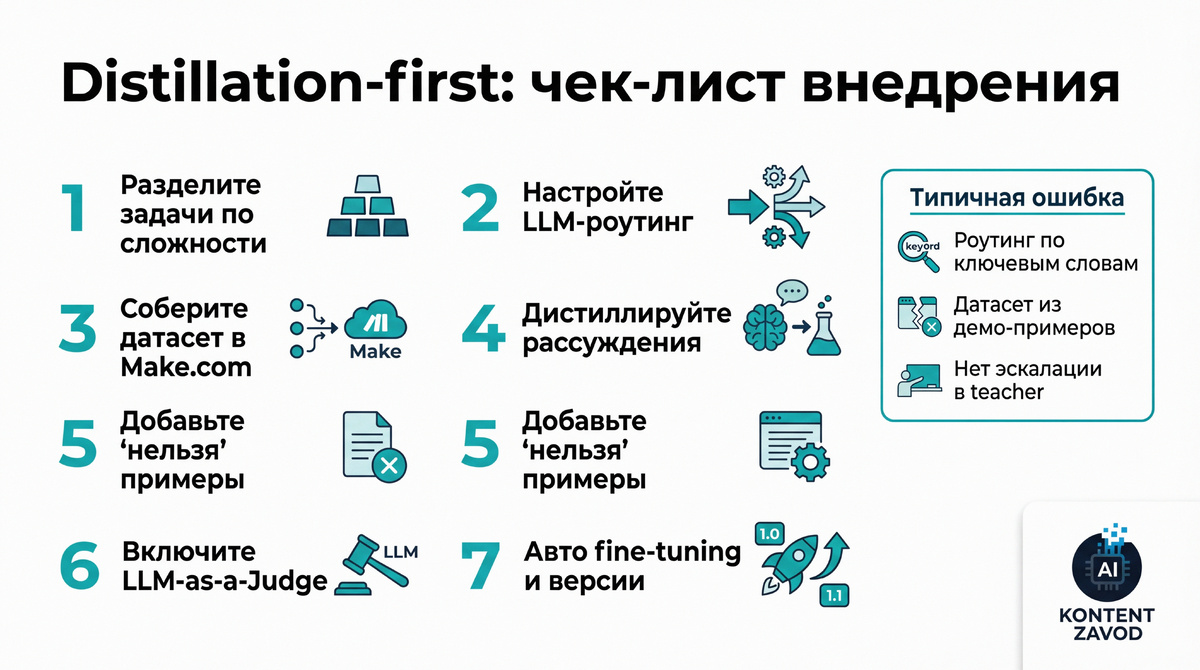
Шаг 1. Разрежьте задачи на «дешевые» и «дорогие»
Что делаем: выписываем типы запросов и решаем, где нужна логика и творчество, а где хватит строгого шаблона (извлечение полей, классификация, тональность, короткий ответ).
Зачем: дистилляция моделей работает лучше всего на узких сценариях. Там SLM (7B-8B) часто превосходит «гигантов», потому что не тащит лишние общие знания.
Типичная ошибка: пытаться одним «универсальным» SLM закрыть все, включая сложные кейсы и редкие исключения.
Мини-пример РФ: у поддержки интернет-магазина отдельные маршруты: «статус заказа/возврат/доставка» идут в SLM, а конфликтные кейсы с претензией и свободным текстом — в GPT-4o.
Шаг 2. Включите каскадную маршрутизацию (LLM Routing)
Что делаем: ставим роутер перед моделями. Он оценивает сложность и решает: SLM или teacher.
Зачем: не отправлять все запросы сразу в дорогую модель. Это самый быстрый рычаг экономии без обучения.
Типичная ошибка: роутить «по ключевым словам» без контроля качества, из-за чего сложные запросы утекают в дешевую модель и ломают опыт.
Мини-пример РФ: в Make.com роутер на логике: если пользователь просит «поясни причину, приведи пункты, сравни варианты» — сразу в teacher. Если запрос «вынь ИНН/сумму/дату из письма» — в SLM.
Шаг 3. Постройте «фабрику датасетов» в Make.com
Что делаем: автоматизируем сбор «золотых» пар промпт-ответ. Схема: входящий запрос — teacher (GPT-4) — оценка человеком (Slack/Email) — если ОК, запись в Airtable/PostgreSQL.
Зачем: около 90% успеха дистилляции сегодня зависит от качества синтетического датасета. Нужны правильные примеры именно вашего продового трафика.
Типичная ошибка: собирать датасет из «красивых» демонстрационных запросов, а не из реальных обращений пользователей.
Мини-пример РФ: маркетинг-отдел согласует tone-of-voice в Slack, и только принятые ответы попадают в базу для fine-tuning.
Шаг 4. Дистиллируйте не только ответы, но и рассуждения
Что делаем: teacher генерирует не только финальный текст, но и логические цепочки (Chain-of-Thought). Дальше вы используете методики дистилляции step-by-step (в духе Hugging Face «Distilling Step-by-Step»).
Зачем: так проще передать «почему так», а не только «что сказать». Отчеты по DeepSeek-V3/R1 показывают, что дистилляция логики помогает открытым моделям догонять закрытые в математике и кодинге при меньших затратах.
Типичная ошибка: выкинуть рассуждения полностью и оставить только короткие ответы, после чего SLM начинает угадывать.
Мини-пример РФ: для юр-отдела: teacher пишет краткий вывод + структуру аргументов, а SLM учится стабильно извлекать сущности и выдерживать стиль.
Шаг 5. Добавьте Negative Constraints Distillation
Что делаем: в датасет кладем не только правильные ответы, но и примеры «как нельзя»: запреты, опасные формулировки, типовые галлюцинации и неправильные действия.
Зачем: это резко повышает безопасность малых моделей в агентных сценариях и снижает риск «самоуверенной ерунды» в проде.
Типичная ошибка: учить только на идеальных кейсах и потом удивляться, что модель красиво ошибается на пограничных запросах.
Мини-пример РФ: в саппорте банка (или финтеха) фиксируете запреты: не обещать сроки, не выдумывать тарифы, не давать юридические трактовки. Эти «нельзя» уходят в дистилляцию.
Шаг 6. Включите LLM-as-a-Judge прямо в Make.com
Что делаем: SLM отвечает, затем GPT-4o-mini проверяет ответ по критериям (точность, отсутствие галлюцинаций). Если оценка низкая — запрос уходит на teacher или пересбор контекста.
Зачем: это продовый предохранитель. Вы получаете дешевые ответы там, где можно, и контролируемый «эскалатор» туда, где нельзя.
Типичная ошибка: проверять «на глаз» или проверять только токсичность, игнорируя фактические ошибки.
Мини-пример РФ: для обработки писем поставщиков: SLM вынимает реквизиты и условия, judge проверяет, что поля не пустые и не противоречат входному письму. Если не сходится — teacher делает разбор.
Шаг 7. Автоматизируйте fine-tuning и версионирование
Что делаем: по расписанию Make.com забирает накопившиеся «ОК» примеры, дергает API дообучения (OpenAI Fine-tuning или Lambda Labs), обновляет версию модели в проде.
Зачем: данные меняются. AutoFT позволяет подливать свежие примеры без ручного «кампейна обучения» раз в квартал.
Типичная ошибка: дообучить один раз и забыть, а потом получать деградацию из-за смены продуктов, терминов и политики ответов.
Мини-пример РФ: в компании с филиалами меняются регламенты. Вы обучаете одну базовую модель и подключаете разные LoRA-адаптеры под отделы (письма, код, саппорт), переключая их «мгновенно».
Что ставить в прод: сравнение подходов
Кому это сэкономит время и деньги
Distillation-first стек хорошо окупается там, где запросов много, а ответы должны быть одинаково «в форме» каждый день. Особенно если вы уже платите за токены и видите, что значимая часть запросов простая.
- Саппорт и колл-центр: выносите рутину в SLM, сложные кейсы эскалируете в teacher.
- Юристы и комплаенс: извлечение сущностей и классификация документов, плюс «нельзя»-примеры через Negative Constraints Distillation.
- Маркетинг и контент: один базовый стиль + разные LoRA под письма, лендинги и ответы в соцсетях.
- Интеграторы на Make.com: можете продавать не «чат-бота на GPT», а производственную линию с контролем качества и прогнозируемой себестоимостью.
Частые вопросы
Дистилляция моделей — это то же самое, что fine-tuning?
Близко, но не одно и то же. Дистилляция — когда teacher генерирует знания (ответы и/или рассуждения), и на этом обучается student. Fine-tuning — способ «посадить» эти знания в выбранную модель.
Почему говорят, что 90% успеха — это синтетический датасет?
Потому что именно датасет задает, что модель будет считать нормой: формат, стиль, ограничения, типовые исключения. Плохая синтетика обучает плохие привычки, даже если модель сильная.
Как начать оптимизацию инференса без обучения?
С каскадного роутинга: простые запросы отправляйте в дешевую модель, сложные — в teacher. Дальше добавьте LLM-as-a-Judge, чтобы автоматически ловить провалы и эскалировать.
Зачем LLM-as-a-Judge, если можно проверять человеком?
Человек не масштабируется на поток. Judge в Make.com дает быстрый автоматический фильтр по критериям (точность, галлюцинации), а человеку оставляет только спорные кейсы.
Что такое Negative Constraints Distillation на практике?
Это примеры запретного поведения в датасете: «не выдумывай», «не обещай сроки», «не ссылайся на несуществующие источники». Для продовых агентов это снижает риск опасных действий и ложных утверждений.
Какая модель подойдет в роли student?
В примерах часто используют SLM уровня 7B-8B (например, Llama 3 8B или Mistral-7B). На узких задачах они после дообучения могут давать до 95% точности учителя (пример Hugging Face для Mistral-7B на 10,000 примеров GPT-4 в извлечении данных из юрдокументов).
Как уменьшить latency, если даже SLM отвечает медленно?
Смотрите на структуру ответа. По данным исследований Microsoft, Skeleton-of-Thought помогает уменьшить задержку в 2-3 раза без потери структуры: модель сначала выдает «скелет», потом заполняет детали.
Какая часть ваших запросов правда требует «тяжелую» модель, а какая — чистая рутина? Если хотите, подпишитесь и напишите кейс — подскажу, где в Make.com быстрее всего собрать роутинг, judge и фабрику датасета.
#ai, #makecom, #llm