Текст подготовил: Андрей Федорчук
Выбор между open и closed моделями — это выбор стека, который снижает риски и стоимость под вашу задачу: закрытые модели дают стабильность и сервис «из коробки», а open source нейросеть дает контроль, локальность и дешевое масштабирование после !deepseek-эффекта.
Еще недавно спор выглядел просто: «хочешь качество — плати за закрытых». А потом вышли DeepSeek-V3 и DeepSeek-R1, и стало неудобно спорить лозунгами. Команды в РФ внезапно получили выбор не «про идеологию», а про деньги, безопасность и реальную эксплуатацию.
Я вижу один и тот же сценарий в проектах на Make.com: сначала берут одну «самую умную» модель на все, потом начинают считать токены, ловят ограничения комплаенса и упираются в стабильность провайдера. Дальше нужны три вывода: где closed правда проще, где open выгоднее, и как собрать гибрид так, чтобы переключать модели за минуту. Это и закроем ближе к концу.
Как выбирать open vs closed без фанатизма: 7 шагов
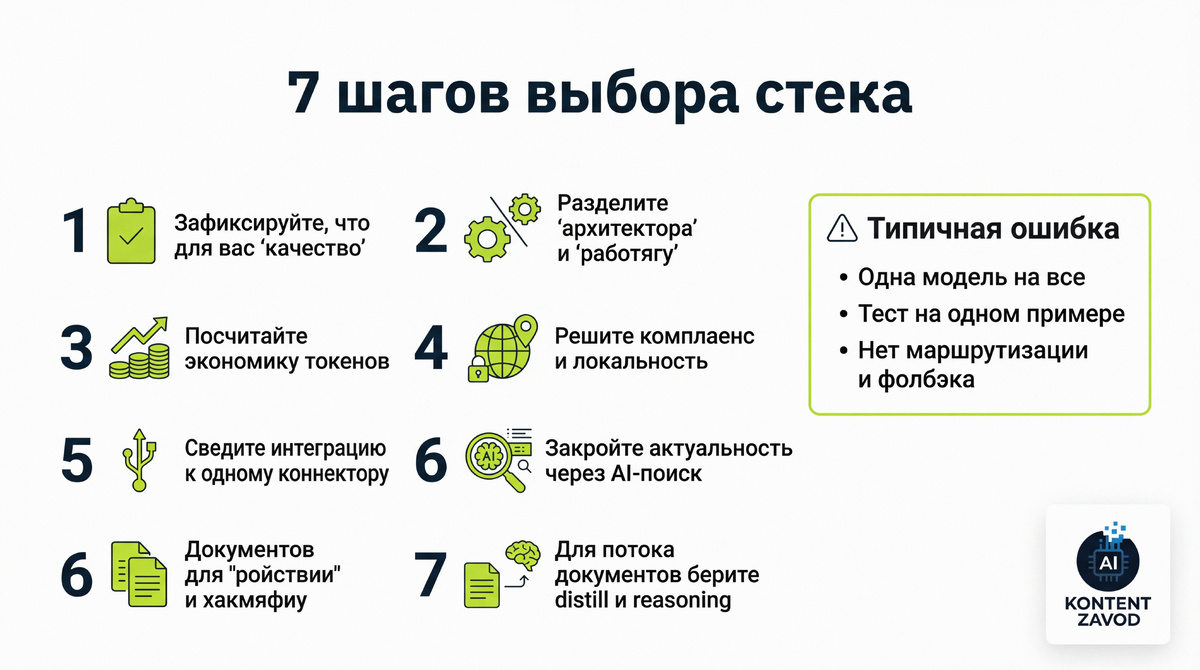
Шаг 1. Зафиксируйте, что для вас «качество»
Что делаем: выписываем 2-3 метрики под задачу. Для контента это формат и фактура, для саппорта — корректная классификация, для кодинга — валидный JSON/скрипт.
Зачем: после релиза DeepSeek-R1 качество перестало быть монополией закрытых моделей, и спор чаще про критерии, а не про «умнее/глупее».
Типичная ошибка: тестировать «по ощущениям» на одном примере и потом удивляться провалам на потоке.
Мини-пример (РФ): интернет-магазин в Москве оценивает AI не по красоте текста, а по тому, сколько карточек товара прошло модерацию на маркетплейс без ручных правок.
Шаг 2. Разделите «архитектора» и «работягу»
Что делаем: сложную логику и планирование отдаём в закрытую модель (Claude 3.5 Sonnet или GPT-4o), а рутину — в open (DeepSeek V3, Llama 3.1) через дешевые API.
Зачем: гибридная схема обычно дешевле и стабильнее на объеме, чем «одна модель на все».
Типичная ошибка: заставлять дорогую модель форматировать, парсить и классифицировать то, что отлично делает более дешевая.
Мини-пример (РФ): агентство в Санкт-Петербурге просит GPT-4o собрать структуру лендинга, а DeepSeek V3 дальше гоняет 200 вариантов заголовков под разные города и УТП.
Шаг 3. Посчитайте экономику токенов до запуска
Что делаем: оцениваем объемы (сколько запросов, сколько текста, сколько документов) и подбираем провайдера.
Зачем: у топовых open-source моделей через провайдеров типа DeepSeek или Groq цена за 1 млн токенов сейчас в 5-15 раз ниже, чем у сопоставимых закрытых.
Типичная ошибка: начинать пилот на закрытой модели, а потом «неожиданно» упереться в бюджет при масштабировании.
Мини-пример (РФ): колл-центр в Екатеринбурге хочет автоматизировать разбор обращений, но считает экономику на месячном объеме сразу, а не после «красивого демо».
Шаг 4. Решите вопрос комплаенса и локальности
Что делаем: если есть жесткие требования (GDPR, банковская тайна), сразу планируем локальное развертывание open-source через Ollama или vLLM.
Зачем: для части компаний это не «желательно», а единственный легальный путь внедрения AI без передачи данных наружу.
Типичная ошибка: пытаться «обойти» требования, а потом переделывать все интеграции и хранение данных.
Мини-пример (РФ): финтех-команда в Казани держит модель локально и в Make.com отправляет наружу только обезличенные поля.
Шаг 5. Сведите интеграцию к одному коннектору
Что делаем: подключаем модели через OpenRouter, чтобы в Make.com разница между GPT-4 и DeepSeek по API была фактически одной строкой/одним модулем.
Зачем: если модель «легла», подорожала или начала вести себя нестабильно, вы переключаете её в одном текстовом поле, а не переписываете сценарии.
Типичная ошибка: городить десяток разных модулей под каждого провайдера и потом бояться что-то менять.
Мини-пример (РФ): команда из Новосибирска держит один сценарий Make.com и переключает модель на запасную, когда меняется политика тарификации.
Шаг 6. Закройте «актуальность» через AI-поиск
Что делаем: для задач с свежими данными добавляем поиск: Make.com + Perplexity API или Search1API, а потом передаем найденный контекст в open-source модель.
Зачем: это снижает галлюцинации на новостях, ценах, регламентах и любых данных после даты отсечки знаний модели.
Типичная ошибка: требовать от модели «знать интернет» без инструмента поиска и источников.
Мини-пример (РФ): юрфирма в Краснодаре тянет свежие разъяснения и затем просит модель оформить выдержки в шаблон письма клиенту.
Шаг 7. Для массовой обработки документов берите distill и reasoning
Что делаем: если задача про логику и извлечение данных (например, 1000 PDF), пробуем DeepSeek-R1-Distill-Llama-70B вместо GPT-4o.
Зачем: «дистиллированные» модели переносят reasoning-поведение в более компактный формат и часто дают нужное качество за 10-20 раз дешевле на потоке.
Типичная ошибка: платить за максимум интеллекта там, где важнее стабильный разбор структуры и полей.
Мини-пример (РФ): бухгалтерия на аутсорсе в Перми вытаскивает из актов/счетов суммы и даты, а дорогую модель оставляет только для спорных случаев.
Сравнение нейросетей по подходам: что брать под задачу
Кому это сэкономит время и деньги
Этот подход особенно полезен, когда AI уже используется, но расходы и риски растут быстрее пользы. Обычно проблема не в модели, а в том, что всё сложили в одну корзину.
- Маркетинг и контент-команды: меньше затрат на рутину, больше контроля над форматами и шаблонами.
- Саппорт и продажи: дешевле классификация и разбор обращений на потоке, с эскалацией сложных случаев в closed.
- Бухгалтерия/документооборот: массовое извлечение данных из PDF через distill/reasoning, без бюджета уровня GPT-4o.
- Комплаенс-чувствительные компании в РФ: локальный open как базовый слой, облако только для обезличенных задач.
Частые вопросы
DeepSeek — это «open source нейросеть» или просто дешевый API?
В практике важнее режим использования: можно работать через провайдера по API (дешево и быстро подключить), а можно строить стек на открытых моделях локально (Ollama, vLLM) ради комплаенса. В статье «open» — это про контроль и переносимость, а не про идеологию.
После !deepseek-эффекта закрытые модели больше не нужны?
Нужны, если вы цените стабильность «из коробки», предсказуемое качество на сложной логике и не хотите тратить время на тонкую настройку и маршрутизацию разных провайдеров.
Как быстро переключать модели в Make.com, если одна подорожала или стала нестабильной?
Держать интеграцию через OpenRouter и не размазывать провайдеров по разным модулям. Тогда смена модели — это правка одного поля в сценарии, а не переделка всей цепочки.
Что делать, если модели не хватает актуальных знаний?
Добавить инструмент поиска и передавать модели найденный контекст. Для этого подходят связки Make.com + Perplexity API или Search1API. Это снижает галлюцинации там, где важны свежие источники.
Где open сейчас особенно силен?
На поточных задачах и в кодинге. По LiveCodeBench DeepSeek-V3 сравнялась или обошла GPT-4o в задачах написания кода, поэтому в Make.com она часто хороша для генерации скриптов, JSON-преобразований и утилитарной логики.
Почему все говорят про reasoning-модели?
После DeepSeek R1 и OpenAI o1 ценность сместилась к моделям, которые лучше держат сложные цепочки рассуждений. Это важно для бизнес-сценариев в Make.com, где нужно не «красиво написать», а правильно решить, какой инструмент дернуть и в каком порядке.
Когда выбирать локальный запуск, а не API?
Когда у вас комплаенс, чувствительные данные или требование суверенитета. Локальный open обычно сложнее в эксплуатации, но дает максимальный контроль над данными и поведением.
দর
А у вас сейчас больше болит цена на токены, комплаенс или стабильность провайдера? Напишите в комментах и подпишитесь — разберу типовой стек под ваш кейс в Make.com.
#ai, #makecom, #deepseek