
Полнотекстовый поиск генерирует информационный шум. Сотрудники тратят часы на фильтрацию устаревших регламентов и чужих переписок. Вводя запрос «шаблон договора 2026», менеджер получает 100 результатов вместо одного актуального документа. Решение проблемы кроется во внедрении мета-полей. Этот инструмент превращает хаотичную файловую свалку в структурированную систему. Исследование McKinsey показывает любопытную цифру: специалисты тратят 19% рабочего времени на поиск нужной информации. Правильная настройка атрибутов сокращает это время до секунд.
Проблема полнотекстового поиска
Технология поиска по тексту сканирует содержимое всех статей внутри системы. Алгоритм ищет точные совпадения по введенным словам. В корпоративной среде этот подход быстро дает сбой. Количество документов растет ежемесячно. У каждого регламента появляются десятки черновиков и согласованных версий.
Синонимы, омонимия и устаревшие версии документов
Полнотекстовый алгоритм не понимает контекста задачи. При простом текстовом сканировании падает релевантность выдачи.
Список причин снижения точности:
- Омонимия. Одно слово имеет разные значения для бухгалтера и разработчика.
- Синонимы. Специалист ищет слово «отгул», а в официальном документе написано «отпуск».
- Устаревшие версии. Система выводит регламент за 2018 год выше актуального из-за большего количества ключевых слов внутри старого текста.
Текстовый движок отлично работает для открытых энциклопедий. Корпоративная база требует строгой иерархии и жестких границ.
Произвольные поля как скрытый каркас стандартов
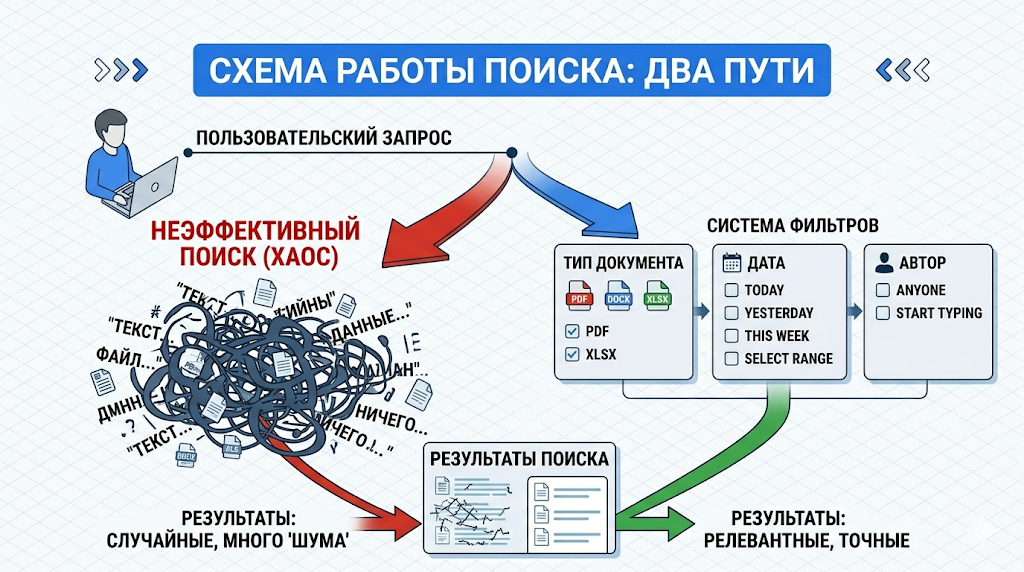
Метаданные создают жесткую структуру управления знаниями. Произвольные поля (Custom fields) привязывают к каждой статье конкретные параметры. Документ получает невидимые теги классификации. Настройка базы знаний начинается с проектирования этой архитектуры.
Что такое фасетная фильтрация в корпоративной среде
Фасетный поиск документов работает по принципу крупного интернет-магазина. Пользователь сужает выборку с помощью точных критериев. Атрибуты документа действуют как жесткие фильтры.
Популярные корпоративные фасеты:
- Тип (Инструкция, Регламент, Бланк).
- Отдел (HR, IT, Маркетинг).
- Статус (Действует, В архиве).
Поиск по метаданным отсекает 99% мусора до того момента, как алгоритм начнет читать основной текст. Запрос превращается в четкую команду серверу.
Практика: Как настроить умный поиск в KBPublisher
Реализовать модульную архитектуру позволяет правильное программное обеспечение. Платформа KBPublisher содержит необходимые инструменты классификации прямо из коробки.
Шаг 1. Создаем произвольные поля для статей (отделы, статусы)
Администратор платформы задает правила игры. В панели управления администратор создает новые обязательные параметры.
- Откройте настройки произвольных полей.
- Добавьте поле типа «Выпадающий список».
- Назовите поле «Отдел» и внесите значения для выбора.
- Сделайте поле обязательным для заполнения при публикации статьи.
После этих действий ни один автор не опубликует документ без указания его корпоративной принадлежности.
Шаг 2. Настраиваем фильтр поиска
Фильтр поиска выводит созданные скрытые поля в публичный интерфейс. Сотрудники получают удобную панель навигации рядом со строкой ввода. Администратор активирует фильтр в настройках публичного раздела и выбирает нужные параметры для отображения. Базовая KBPublisher настройка занимает 10 минут и навсегда решает проблему потерянных корпоративных файлов.
Бесплатный Open Source или Облако? Выбираем решение
Компании реализуют эту функциональность двумя путями. Выбор зависит от наличия собственных серверов и штата IT-специалистов.
Официальная версия KBPublisher предоставляет готовое к работе решение. Сервер настраивают инженеры платформы. Обновления и регулярное резервное копирование происходят автоматически. Этот вариант идеально подходит командам без выделенных системных администраторов.
Функциональная система управления знаниями open source требует установки на сервер компании. Пакет Community Edition открывает доступ к инструментам классификации бесплатно. Разработчики публикуют дистрибутив в открытом репозитории GitHub. Вариант решает задачи компаний с закрытыми внутренними контурами безопасности.
Логичная структура каталогов важнее объема текстов внутри платформы. Полнотекстовый поиск выполняет вспомогательную функцию. Основу корпоративного порядка задают жесткие атрибуты. Внедрите мета-поля в систему управления документами. Специалисты перестанут тратить часы на навигацию и сфокусируются на решении прямых рабочих задач.