
Сотни файлов на корпоративном сервере лежат мертвым грузом, потому что сотрудники не могут найти внутри них нужную информацию. Стандартный поиск видит только названия файлов. Если документ называется "Регламент_отдел_продаж_финал.pdf", найти в нем пункт о штрафах через строку поиска невозможно. Решение проблемы: массовый репарсинг документов, который извлекает текст из файлов и делает его доступным для поисковой машины.
Что такое репарсинг файлов и зачем он нужен?
Репарсинг означает повторное чтение файла внутренним роботом системы для создания текстового индекса. Когда администратор загружает пачку старых регламентов в базу знаний через FTP или автоматические правила директорий (Directory Rules), система "видит" только оболочку файла. Чтобы заработал полнотекстовый поиск, специальный скрипт должен открыть каждый PDF или Word документ, скопировать оттуда все слова и записать их в базу данных Sphinx или MySQL.
Сотрудники тратят 1.8 часа ежедневно на поиск информации, как показывает исследование McKinsey. Полнотекстовый поиск сокращает это время до секунд. Пользователь вводит запрос, а система показывает не только статьи, но и точные совпадения внутри прикрепленных файлов Excel, Word или PDF.
Инструкция: Как запустить массовый репарсинг в KBPublisher
Администраторам баз знаний часто требуется обновить индекс после массовой загрузки документов. Открывать карточку каждого из 10 000 файлов и нажимать кнопку обновления нерационально. KBPublisher включает функцию групповой обработки данных.
Выполните три шага для обновления файлового индекса:
- Откройте панель управления и перейдите по маршруту: Админка -> Файлы.
- Выберите нужные документы галочками слева. Для выбора всех файлов на странице нажмите галочку в шапке таблицы.
- Внизу страницы найдите блок Массовые действия, выберите опцию Репарсинг файлов и нажмите кнопку подтверждения.
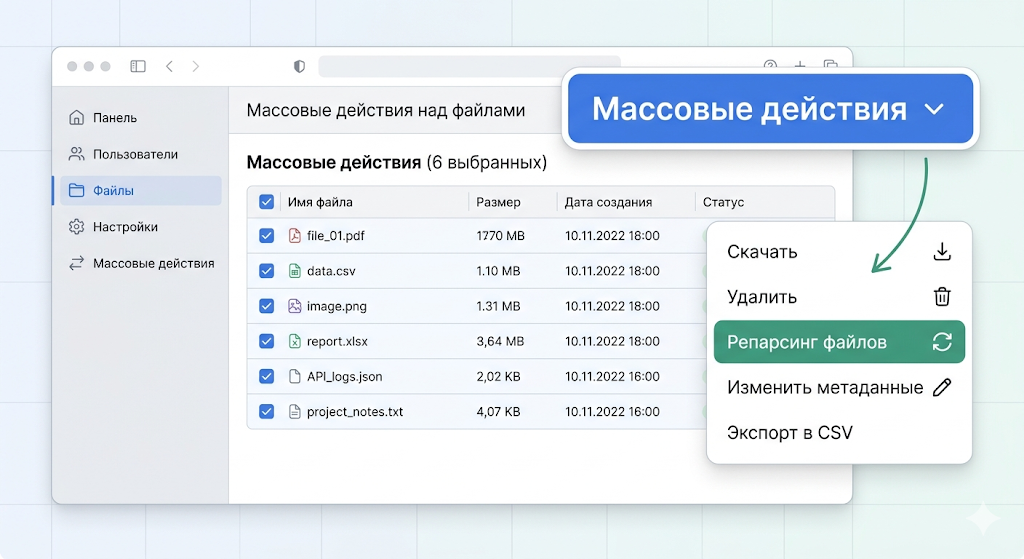
Лайфхак для больших баз: вы можете запустить репарсинг не по отдельным файлам, а по целым категориям. Для этого перейдите в раздел управления категориями файлов, выберите нужные папки и примените аналогичное массовое действие. Система запустит фоновый процесс извлечения текста.
Проверка парсеров: Почему текст может не извлекаться?
Иногда репарсинг завершается, но текст в базе не появляется. Причина кроется в серверных настройках. База знаний использует сторонние утилиты для чтения проприетарных форматов.
Проверьте наличие установленных библиотек на сервере:
- XPDF: отвечает за извлечение текста из файлов формата PDF.
- Catdoc: необходим для чтения старых файлов Microsoft Word (.doc).
- Antiword: альтернативный парсер для файлов Word.
В панели администратора KBPublisher предусмотрен раздел тестирования. Перейдите в блок настроек и запустите тесты утилит. Если система выдает ошибку, системному администратору нужно установить недостающие пакеты на Linux-сервер (apt-get install xpdf catdoc antiword) или указать правильные пути к исполняемым файлам в конфигурации базы знаний.
У вас еще нет умного поиска по документам?
Компании годами копят файлы на сетевых дисках, теряя доступ к собственному опыту. Внедрение структурированной базы знаний превращает "слепой" файловый архив в прозрачную информационную систему.
Если настройка серверов и парсеров кажется сложной задачей, облачная версия решает эту проблему из коробки. В KBPublisher все инструменты для чтения PDF, Word и Excel уже установлены и настроены инженерами. Вы просто загружаете файлы, а система автоматически извлекает текст и делает его доступным для быстрого поиска.
Массовый репарсинг возвращает ценность старым документам. Один запуск скрипта открывает доступ к тысячам страниц скрытого текста. Начните использовать скрытые резервы вашей компании уже сегодня: протестируйте возможности облачной версии или разверните базу на собственном сервере, скачав бесплатную версию Community Edition из официального репозитория на GitHub.