Текст подготовил: Андрей Федорчук

AI-ready data — это данные для ИИ, которые уже очищены, полно описаны и структурированы так, чтобы LLM и RAG отвечали без фантазий и ошибок. Выгода простая: меньше галлюцинаций, точнее поиск и рекомендации, стабильнее реклама и аналитика.
Частая картина в РФ: каталог живет в 1С, выгрузка в CSV, описания пишутся «как получится», а цены обновляются пачками. Потом подключают чат-бота на GPT, семантический поиск или рекомендации — и внезапно ИИ уверенно советует не то, путает модификации и спорит с реальными остатками.
Проблема почти всегда не в модели. Модели стали commodity, а конкурентное преимущество уехало в качество данных и их структуру. Дальше будет 3 вывода: почему чистка и схемы дают больше точности, чем «еще одна модель»; как first-party данные становятся топливом; и как это быстро автоматизировать в Make.com, чтобы фиды не разваливались каждую неделю.
Как сделать каталог и 1P данные AI-ready за 7 шагов
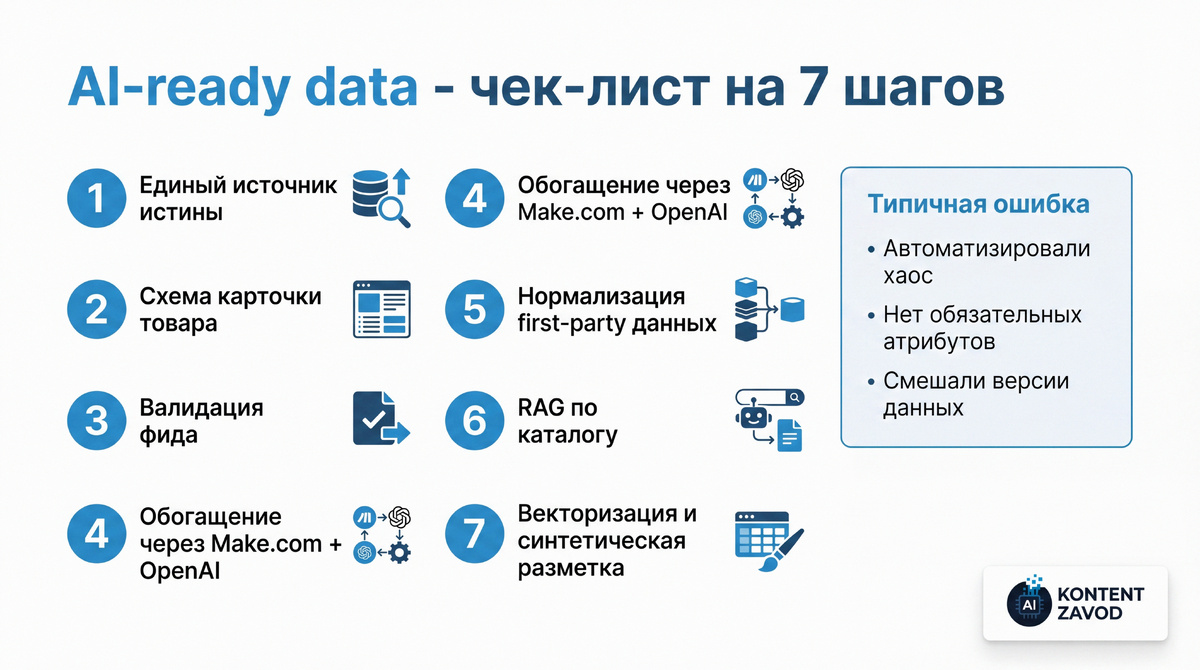
Шаг 1. Определите, где ИИ будет брать правду
Что делаем: выбираем «единый источник истины» для каталога и справочников: где живут названия, атрибуты, остатки, цены, правила комплектаций.
Зачем: автономные агенты и любые интеграции на Make.com ломаются не от «плохого промпта», а от конфликтов версий и ручных правок в трех местах.
Типичная ошибка: «и в 1С есть, и в Excel поправим, и в CMS руками докинем».
Мини-пример (РФ): магазин выгружает фид из 1С, а маркетолог правит описания в Google Sheets. В итоге в рекламе одно, на сайте другое, у бота третье. Сначала фиксируем источник, потом автоматизируем остальное.
Шаг 2. Приведите карточку товара к схеме (минимум атрибутов)
Что делаем: задаем обязательные поля и формат (хотя бы как JSON Schema): название, бренд, категория, вариации (цвет/размер), цена, наличие, доставка, ключевые характеристики.
Зачем: GIGO работает железно: если в фиде нет атрибутов или они кривые, даже GPT-4/Claude 3.5 начнут «додумывать» и ошибаться в классификации.
Типичная ошибка: один общий «description» на все случаи жизни и нулевые характеристики.
Мини-пример (РФ): в фиде «кроссовки мужские» без материала верха и сезона. Семантический поиск начинает тащить зимние модели в летние запросы. Добавили сезон и материал — и выдача стала спокойнее.
Шаг 3. Настройте валидацию фида до отправки куда-либо
Что делаем: проверяем аномалии и обязательные поля на лету, до выгрузки в рекламные кабинеты, маркетплейсы или в вашу базу знаний.
Зачем: дешевле остановить кривую выгрузку, чем разгребать последствия в рекламе, аналитике и в ответах бота.
Типичная ошибка: замечать поломку только по падению продаж.
Мини-пример (РФ): в Make.com ставим фильтр: если цена товара изменилась более чем на 50% за час, сценарий стопается и пишет в Telegram. Это не про красоту, это про контроль.
Шаг 4. Автоматически обогащайте описания и характеристики (но с рамками)
Что делаем: запускаем сценарий Make.com: Google Sheets/Airtable (сырые данные) — OpenAI (промпт на SEO-описание и извлечение характеристик) — обновление данных в таблице/каталоге.
Зачем: так «AI-raw» каталог превращается в «AI-ready» без ручного копирайтинга на тысячи SKU.
Типичная ошибка: генерировать текст без привязки к схеме (в итоге красиво, но не парсится и не помогает поиску).
Мини-пример (РФ): у одежды нет нормальных описаний. Генерируем краткое описание + список характеристик по шаблону, чтобы потом это же уходило в фид и в RAG-базу.
Шаг 5. Подготовьте first-party данные как отдельный актив
Что делаем: собираем и нормализуем 1P события и контент: просмотры, добавления в корзину, покупки, обращения, отзывы. Храним так, чтобы их можно было использовать повторно.
Зачем: при отказе от third-party cookies и росте приватности только first party данные остаются топливом для рекомендаций и предиктивных моделей оттока.
Типичная ошибка: «данные есть в аналитике, значит они у нас есть». Но для моделей и RAG нужно другое качество и структура.
Мини-пример (РФ): отзывы лежат в CRM текстом. Приводим их к единому формату (товар, дата, тональность/тема, цитата), чтобы потом использовать в семантическом поиске и подсказках.
Шаг 6. Сделайте RAG: поиск по каталогу перед ответом
Что делаем: строим RAG-подход: прежде чем отвечать, ИИ ищет факты в вашей базе знаний (каталоге/документации).
Зачем: качество ответа здесь на 100% зависит от того, насколько хорошо структурированы записи и поля. И это главный способ снизить галлюцинации без «магии промпта».
Типичная ошибка: кормить модель «простыней» текста без структуры и без идентификаторов товара/версий.
Мини-пример (РФ): в базе знаний по доставке разные формулировки для регионов. Привели к единому справочнику условий и начали отдавать в RAG только актуальную версию.
Шаг 7. Векторизуйте тексты и используйте синтетическую разметку аккуратно
Что делаем: превращаем описания и отзывы в эмбеддинги (векторизация). Если данных для классификации мало, добавляем синтетические примеры на базе ваших реальных 1P данных.
Зачем: векторизация помогает семантическому поиску понимать смысл (например, «платье для жаркой погоды» как легкий сарафан, даже если слова «жаркая» нет в названии). Синтетическая разметка ускоряет старт там, где нет датасета.
Типичная ошибка: генерировать синтетику «из головы», без опоры на реальные кейсы, и учить систему на выдумке.
Мини-пример (РФ): саппорт хочет классифицировать жалобы по темам, но исторических меток мало. Берем реальные обращения, а LLM генерирует дополнительные похожие примеры для обучения и теста.
Что выбирать: модель, RAG или «сначала данные»
Кому это сэкономит время и деньги
Если у вас каталог, фиды и first party данные живут в разных системах, AI-проекты обычно буксуют не на «интеллекте», а на подготовке данных. По оценке Anaconda, специалисты по данным тратят до 60-80% времени на очистку и подготовку данных, и лишь 10-15% на моделирование. И это ощущается даже в маленьких командах: больше всего времени съедают правки, проверки и «почему опять не так».
- E-commerce и ритейл: меньше проблем с фидами, стабильнее семантический поиск и рекомендации.
- Маркетинг: выше управляемость кампаний за счет качественных 1P сегментов (в исследованиях упоминают 15-20% выше ROI при связке 1P данных и AI).
- Поддержка: меньше галлюцинаций в чат-ботах, особенно если опираться на схемы JSON/Schema.org (у неструктурированных данных риск галлюцинаций выше на 30-40%).
- Продакт и BI: меньше споров «какие цифры правильные», когда есть единая структура и проверки.
Частые вопросы
Что такое AI-ready data простыми словами?
Это данные для ИИ, которые можно безопасно использовать в LLM, поиске и рекомендациях: поля заполнены, форматы единые, ошибки отлавливаются, а источники не конфликтуют.
Почему «качество данных» важнее, чем выбор модели?
Потому что модели стали commodity, а GIGO никто не отменял. Если фид кривой, любая LLM будет ошибаться. В data-centric подходе точность часто растет за счет чистки датасета (часто приводят оценку, что в 80% случаев улучшение идет от данных, а не от параметров модели).
Что быстрее улучшит результат: RAG или «обогащение фида»?
Если у вас пустые атрибуты и плохие описания, сначала обогащение и схема. RAG отлично работает, но он тянет факты из вашей базы знаний. Если там мусор, RAG просто быстрее найдет мусор.
Какие first party данные реально нужны, если куки исчезают?
Поведенческие события (просмотр, корзина, покупка), обращения в поддержку, отзывы, ответы в опросах, данные из личного кабинета. Важно не количество, а нормализация и возможность связать с каталогом и сегментами.
Как Make.com помогает именно с качеством данных?
Через no-code ETL: регулярные выгрузки, проверки, фильтры аномалий, обогащение текстов и атрибутов, уведомления в Telegram при сбоях. Главное правило: сначала схема и правила, потом автоматизация.
Векторизация — это только для больших команд?
Нет. Даже небольшой каталог и отзывы можно векторизовать, чтобы семантический поиск и рекомендации понимали смысл, а не только ключевые слова. Главное, чтобы тексты и метаданные были структурированы.
Какая боль у вас сейчас главнее: фиды, каталог или first party данные? Напишите в комментариях и подпишитесь — разберу типовые схемы Make.com для AI-ready данных под реалии РФ.
#данныедляии, #качестводанных, #firstparty