Если ты когда-нибудь разговаривал с голосовым ассистентом и ловил паузу в духе «эээ… сейчас… секундочку…», то знаешь главную боль: голосу нельзя тормозить. В тексте ИИ может «подумать» пару секунд — и никто не умрёт. А в голосе задержка должна укладываться примерно в 200 миллисекунд, иначе диалог превращается в неловкий созвон с человеком, у которого микрофон в шкафу.
И вот тут вылезает RAG — подход, где модель перед ответом лезет в базу знаний и достаёт нужные куски текста. Проблема простая: обычный запрос в удалённое хранилище часто съедает 50–300 мс только на сеть и поиск. То есть ты ещё ничего не ответил — а бюджет уже закончился.
Salesforce выложили в опенсорс VoiceAgentRAG — архитектуру, которая лечит эту задержку не магией, а нормальной организацией труда внутри системы.
Два «сотрудника»: один говорит, второй копает
В VoiceAgentRAG работают два агента параллельно, и у каждого своя роль.
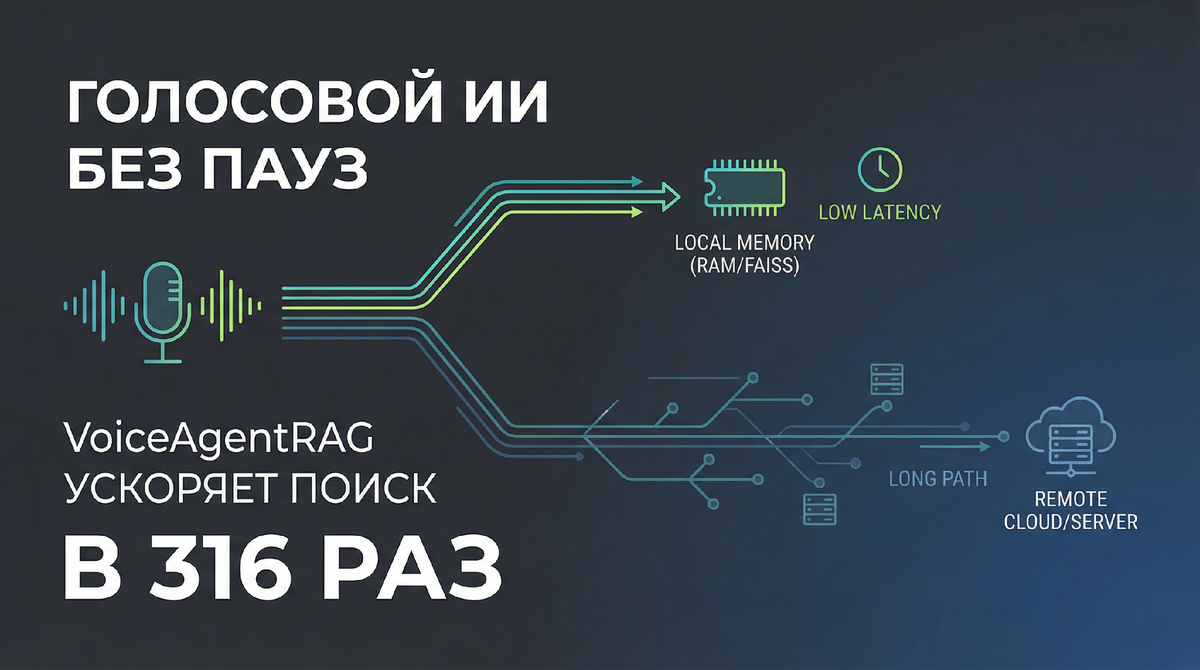
Fast Talker — «быстрый говорун». Он находится на главной линии ответа, где важна каждая миллисекунда. Когда пользователь задаёт вопрос, Fast Talker сначала смотрит в локальный семантический кэш — это память в оперативке, где уже лежат подходящие куски знаний. Если нашёл — достаёт контекст примерно за 0,35 мс. Это буквально «моргание».
Если в кэше пусто — приходится идти в удалённую базу. Но результат сразу складывается в локальную память, чтобы на следующих репликах не бегать по сети снова.
Slow Thinker — «медленный мыслитель». Он работает фоном и делает то, что мы все хотели бы уметь на совещаниях: заранее понимать, что сейчас спросят. Он постоянно следит за диалогом, берёт последние 6 реплик и пытается предсказать 3–5 вероятных продолжений темы. А затем заранее подтягивает из удалённого хранилища нужные фрагменты в локальный кэш — пока между репликами есть естественная пауза.
Забавный нюанс: чтобы лучше находить нужные документы, Slow Thinker формулирует не вопросы, а «описания в стиле документа». Потому что база знаний обычно написана прозой, и совпадения по смыслу так получаются точнее.
Что за «семантический кэш» и почему он не тупой
Кэш здесь не просто «словарик: вопрос → ответ». Он устроен умнее: хранит фрагменты документов и умеет искать по смыслу прямо внутри себя.
Техническое слово всё-таки будет одно: FAISS — это быстрый движок для поиска похожих текстов по смыслу, который можно держать в памяти. Звучит страшно, но по факту это «поисковик по оперативке».
Кэш индексирует сами документы, а не формулировки запросов — поэтому если ты спросил иначе, но про то же самое, шанс попасть в кэш всё равно высокий. Есть пороги похожести, чтобы кэш не «угадывал» слишком смело. И он не раздувается до бесконечности: выкидывает старое по принципу «давно не трогали — до свидания» и чистит дубликаты.
А если пользователь внезапно сменил тему, Fast Talker отправляет сигнал «срочно принеси контекст» — и Slow Thinker делает приоритетный поиск шире обычного, чтобы быстро обложить новую тему материалами.
Насколько быстрее стало в реальности
Тестировали систему с удалённой базой Qdrant Cloud на 200 запросах в 10 сценариях диалога.
Попадание в кэш — 75%, а на «прогретых» репликах — 79%. Ускорение поиска составило 316 раз: примерно 110 мс против 0,35 мс на удачных попаданиях. За 200 ходов диалога экономия составила 16,5 секунды чистого времени на поиск.
Лучше всего система работает, когда разговор держится одной темы. Например, сценарий «сравнение функций» дал 95% попаданий в кэш. А когда диалог скачет, как пульт у телевизора в пятницу вечером, показатель падает: в самом «неровном» сценарии было около 45–55%.
Открытый код — берёшь и крутишь под себя
Репозиторий сделан так, чтобы не запираться в одной экосистеме. Поддерживаются основные языковые модели — OpenAI, Anthropic, Gemini, а также локальный запуск через Ollama (в тестах использовали GPT-4o-mini). Для распознавания и озвучки подходят Whisper и Edge TTS. Для хранилища — FAISS локально или Qdrant удалённо.
То есть идея не «покупайте наш стек», а «вот схема — прикручивай к своему».
Скорость в голосе — это не бонус, а условие выживания
В голосовом интерфейсе задержка — это не «приятно бы», а условие, чтобы тебя вообще не считали тупящим ботом. VoiceAgentRAG по сути делает простую вещь: разделяет работу на «ответить прямо сейчас» и «подготовиться заранее».
Как в кафе: один бариста принимает заказ и разговаривает, второй уже молча перемалывает кофе, потому что знает — следующим будет капучино.
И когда система начинает жить в таком режиме, голосовой ИИ перестаёт звучать так, будто он каждый раз звонит в справочную, прежде чем сказать «да».