Всем привет, сегодня мы снова решаем задачи на JavaScript. Обычно я стараюсь не только решить задачу, но ещё и оптимизировать её.
В сегодняшней задаче нам нужно найти самый длинный префикс, который содержится одновременно во всех строках. Если что, префикс это такая подстрока, которая находится в самом начале слова.

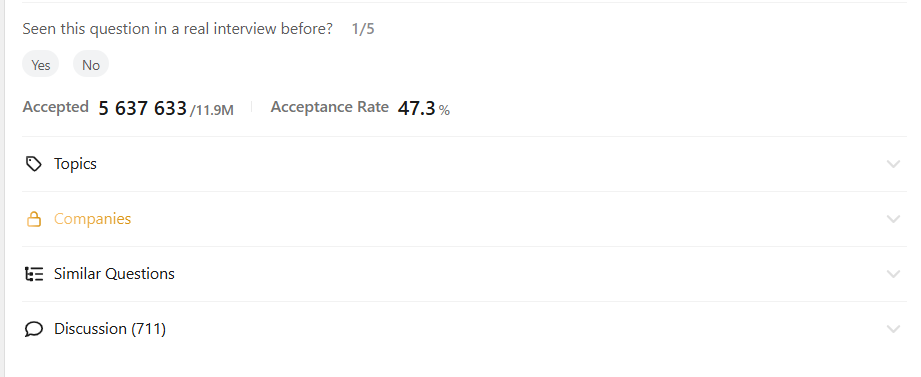
Вроде бы эта задача помечена, как лёгкая, но решило её 47,3% разработчиков, что довольно странно. Выглядит она не сложно, но если бы это было так, не было такого низкого процента решаемости.
Я думаю, здесь есть какие-то подвохи. Наиболее вероятно, что для проверки кода нам будут подкидывать слишком большие строки, из за чего мы можем не пройти чисто по оптимизации кода. Но это мои предположения, они могут быть опровергнуты в дальнейшем.
Ну что ж, дорогу осилит идущий. Давайте попробуем...
Начинаем решать задачу
Например, у нас есть массив из трёх слов. Нам нужно сделать цикл, которых проходит по буквам всех слов одновременно и сравнивает их. Также нужно сделать так, чтобы цикл не выходил за границы слова и останавливался, когда нужно.
Для начала нужно посчитать количество букв в самом маленьком слове. Делаем так
Я создал переменную, записал в неё бесконечность и начал сравнивать её с другими значениями, после чего в "min" записываются те, что меньше её.
Дальше я создам две переменные. "index" - конец нашего префикса. "check" - выполнилась ли проверка на первой букве
Дальше я сделаю цикл, который перебирает значения от 0 до конца минимального слова, и на каждой букве вызывает цикл, который сравнивает букву каждого слова. И записывает в index, где заканчивается наш префикс.
Казалось бы, задача вроде бы простая, но я буду её не только делать, но и оптимизировать. Я попытаюсь сделать так, чтобы по своей скорости код оказался среди лучших. То же самое я делаю и в своих предыдущих статьях.
Если у нас не нашлось совпадений, то index будет -1 и код выведет пустую строку. А если нет, в переменную "str" будет записываться этот самый префикс и выводиться из функции.
Наш код справился со своей задачей
Но меня смущает низкая решаемость этой задачи. Возможно, интересное ждёт нас впереди...
Запускаем
Первая ошибка нас встречает на таком примере. Всего одно слово с одной буквой.
Проблема в том, что наша строка одна, и цикл не запускается. Я сделаю отдельное условие, которое не считает, а просто выводит эту самую строку, если она одна.
Следующая ошибка
Ошибка здесь, я немного проглядел в этом условии.
Не index > 0, а index >= 0.
И нас код отработал отлично. Он справился с задачей за 0мс. На самом деле за приближённые к нему значения, как 0,01мс или 0,001мс, LeetCode, вероятно, округляет. Но я LeetCode уже не верю, каждый запуск он выдаёт разные результаты. Перезапустим.
Теперь выдаёт 3мс
В общем, наш код работает не идеально, выполняется за 0-5мс. Нужно его оптимизировать.
Приступаем к оптимизации
Довольно глупо, но я заметил, что можно поставить break в цикле. Конкретно этот цикл отвечает за перебор слов, когда проверяем одну конкретную букву.
Я придумал ещё кое что. У нас есть два цикла, один определяет конечную позицию префикса, а другой по ней этот префикс получает. Этот же цикл можно объединить в один, можно сразу записывать подходящие буквы в префикс.
Выглядеть это должно так
Переменной index у нас больше не существует, больше нет лишнего цикла, да и строчек кода стало меньше.
При запуске кода, он выполняется за 1ms, но нужно перепроверить ещё раз
Я запустил наш код несколько раз (больше трёх раз, вам я показал только три скриншота). Теперь наш код имеет более стабильное время выполнения. Раньше он выполнялся за 1-7мс, теперь за 1-3мс.
Если будете делать задачи на LeetCode, и для вас будет важна оптимизация, запускайте проверку кода несколько раз, LeetCode может выдавать ошибки.
Не знаю, можно ли это назвать ошибкой, но код выполняется не совсем стабильно. Ещё до нашей оптимизации, наш неоптимизированный код выполнился за 0мс и попал в топы, не забываем об этом.
Можно также заранее высчитать длину массива со словами и записать её в переменную для дальнейшего использования. В нашем коде 3 места, где длина массива рассчитывается каждый раз.
Также я обратил внимание на этот участок кода
Здесь мы перебираем слова и сравниваем буквы двух соседних слов в массиве. Это не совсем разумно. Если нам надо проверить, везде ли буквы одни и те же, можно сравнивать букву первого слова с буквой всех остальных.
Теперь в двух местах одна и та же конструкция, мы обращаемся к массиву и получаем букву. Мы можем эту самую букву один раз высчитать в начале цикла и везде её использовать
После всех этих изменений скорость выполнения кода та же, от 0 до 4 мс. Запускал несколько раз, проверял
Прошло какое-то время. На следующий день я решил снова запустить код на LeetCode, но не вечером, а днём. Вот результаты
Я запустил код 6 раз, из этих 6 раз он 3 раза выполнился за 0 мс, 2 раза за 1 мс, и 1 раз за 2 мс. Выполняется, примерно за 0-2 мс, что достаточно хорошо.
Подходим к концу
Вот такой код у нас получился
Выполняется достаточно быстро, но я думаю, что его ещё можно как-то оптимизировать.
Если у вас есть какие-то мысли, замечания, дополнения, пишите в комментариях.
Я буду рад, если вы поставите лайк и подпишитесь 😀