Текст подготовил: Андрей Федорчук

Личная граница в AI — это набор правил, как ваши данные попадают в нейросети и автоматизацию, который не превращает человека в безликий датасет. Грамотная архитектура защищает приватность и при этом дает бизнесу пользу от ИИ.
Маркетолог в российском банке закидывает выписку клиента в личный ChatGPT, чтобы «быстрее сегментировать базу». Руководство пишет красивые политики по защите данных, а реальная утечка происходит в браузере сотрудника.
AI уже умеет восстановить личность по геолокации и стилю письма, даже если имена вырезали. Ни галочка в политике конфиденциальности, ни длинный NDA это не спасают. Дальше разберем, как использовать Make.com как фильтр, когда локальные LLM действительно нужны и как синтетические данные снижают риск, не ломая аналитику.
Практический гайд: как не превратить пользователей в сырье для ИИ
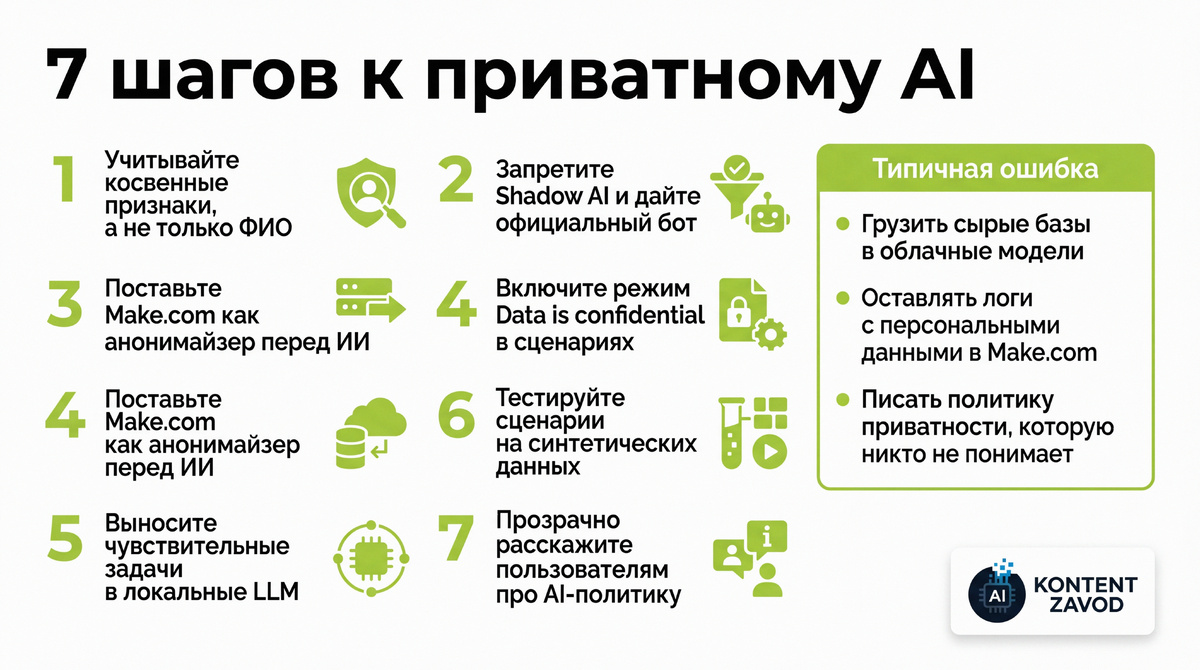
Шаг 1. Признать, что простая деидентификация больше не работает
Что делаем: перестаем считать замену ФИО на «Иван И.» надежной защитой. Оцениваем, какие косвенные признаки в наших сценариях позволяют узнать человека: гео, время действий, уникальные поля.
Зачем: современные модели умеют склеивать куски информации и восстанавливать личность даже из формально анонимных логов.
Типичная ошибка: выгружать CRM в Excel, удалить пару колонок и спокойно грузить все в облачную нейросеть «для анализа сегментов».
Мини-пример РФ: ecom из Москвы выкачивает историю заказов с точными адресами и временем доставки, удаляет ФИО и загружает в внешний AI-сервис. По совокупности адреса, района и чеков клиента все равно можно однозначно узнать.
Шаг 2. Ввести запрет на Shadow AI и дать официальный инструмент
Что делаем: прописываем в регламентах прямой запрет на использование личных аккаунтов ChatGPT и других публичных ботов для работы с корпоративными документами.
Зачем: основная утечка сегодня — не взлом дата-центра, а менеджер, который сам отгружает документы во внешний сервис.
Типичная ошибка: написать сухую политику и не дать людям замену. В итоге сотрудники все равно идут в личный GPT, потому что он удобнее.
Мини-пример РФ: продуктовая IT-компания из Петербурга поднимает внутрикорпоративный доступ к Azure OpenAI с отключением использования данных для обучения и официально разрешает его как рабочий инструмент вместо личных аккаунтов.
Шаг 3. Использовать Make.com как фильтр и анонимайзер
Что делаем: строим цепочки в Make.com, которые перед отправкой текста в облачную модель автоматически заменяют персональные данные на плейсхолдеры вида [NAME_1], [PHONE_1]. Используем Regex или отдельный AI-промпт-анонимайзер.
Зачем: облачная модель видит только обезличенный контент, а восстановление реальных данных происходит уже на нашей стороне, в Make.com.
Типичная ошибка: слать в OpenAI сырые заявки клиентов и надеяться на абстрактные обещания поставщика «мы все шифруем».
Мини-пример РФ: московское агентство поддержки интернет-магазинов прогоняет тикеты через Make.com. Сначала модуль Regex вычищает имена, адреса и телефоны, потом текст уходит в OpenAI для классификации, а после ответа Make.com подставляет данные обратно в обращение в Helpdesk.
Шаг 4. Включить режим Zero-Knowledge в автоматизации
Что делаем: помечаем чувствительные сценарии в Make.com флагом конфиденциальности (Data is confidential), минимизируем логирование и срок хранения данных.
Зачем: даже при компрометации аккаунта или уязвимости платформы злоумышленник не увидит историю полных запросов с персональными данными.
Типичная ошибка: использовать одну и ту же Make-сцену для прототипирования и продакшена с включенными логами «для дебага».
Мини-пример РФ: региональная клиника автоматизирует запись пациентов через Make.com. Для сценария с медицинскими полями включают конфиденциальный режим, а для маркетинговых рассылок оставляют стандартные логи.
Шаг 5. Перенести максимум чувствительных вычислений в локальные LLM
Что делаем: для документов с высокой чувствительностью поднимаем локальные модели вроде Llama 3 или Mistral через Ollama на своем сервере или в защищенном контуре.
Зачем: контент не уходит к OpenAI или Google, обработка идет внутри инфраструктуры компании, что снижает риски и лучше стыкуется с требованиями по защите персональных данных.
Типичная ошибка: использовать облачный AI даже там, где формально запрещено выносить данные за пределы РФ.
Мини-пример РФ: юридическая фирма из Казани анализирует договоры клиентов через локальную Llama 3 на сервере в дата-центре резидента РФ и подключает к ней бота через внутренний портал.
Шаг 6. Тестировать сценарии и модели только на синтетических данных
Что делаем: для разработки и A/B-тестов генерируем синтетические профили пользователей с помощью ИИ, не загружая реальные базы.
Зачем: снижаем риск утечки на этапах прототипирования. Gartner прогнозирует, что к 2025 году 60% данных для разработки ИИ и аналитики будут синтетическими — рынок туда уже идет.
Типичная ошибка: давать подрядчику полный дамп CRM «для настройки воронки» и верить, что он сам аккуратно все почистит.
Мини-пример РФ: московский онлайн-школа заказывает автоматизацию в Make.com у внешней команды. Для настройки они получают только синтетическую базу, сгенерированную по структуре реальных полей, но без связи с живыми учениками.
Шаг 7. Объяснить пользователю, что вы делаете с его данными и зачем
Что делаем: публикуем простую, неюридическую страницу о том, как именно используется ИИ, какие данные попадают в модели, где стоят локальные LLM, какие политики безопасности включены.
Зачем: исследования Cisco показывают, что 81% людей считают использование их данных неконтролируемым. Прозрачность по AI-практикам становится конкурентным преимуществом.
Типичная ошибка: спрятать все детали в длинной политике на 20 страниц мелким шрифтом.
Мини-пример РФ: сервис доставки из Екатеринбурга делает отдельный раздел «Как мы используем AI» с понятными блоками: локальный анализ отзывов, анонимизация через Make.com, запрет передачи истории заказов в публичные чат-боты.
Где обрабатывать данные: облако, локальные LLM и Make.com
Кому приватный AI-сетап сэкономит время и деньги
Подход с Make.com как фильтром, локальными LLM и синтетическими данными особенно полезен, если вы уже чувствуете, что «ручное» решение вопросов приватности тормозит продукт.
- Среднему и крупному ecom в РФ — меньше рисков при автоматизации поддержки, триггерных рассылок и аналитики заказов.
- Медицине и edtech — возможность использовать ИИ для обработки записей и успеваемости без вывоза персональных данных в публичные сервисы.
- Банкам, финтеху и страхованию — снижение вероятности штрафов и претензий за утечки при работе с транзакциями и заявками.
- Продуктовым IT-компаниям — быстрый запуск AI-функций без вечных согласований по безопасности, потому что архитектура изначально privacy-first.
- Агентствам и интеграторам — готовая логика: где включить анонимизацию в Make.com, где использовать синтетические данные вместо реальных клиентских баз.
Частые вопросы
Если я заменю имена в базе, этого достаточно для защиты?
Нет. Модели могут восстановить личность по сочетанию геолокации, времени активности, сумм заказов и другим косвенным признакам. Нужна системная анонимизация и ограничение состава данных, которые вы вообще отправляете в ИИ.
Make.com безопасен сам по себе или нужно что-то настраивать?
По умолчанию часть данных может попадать в логи сценариев. Для конфиденциальных процессов включайте режим Data is confidential и выносите чувствительные поля в отдельные модули с минимальным логированием.
Зачем мне локальная LLM, если есть мощные облачные модели?
Локальные LLM нужны там, где вы не можете передавать данные наружу: юрпрактика, медицина, финансы. Такие модели вроде Llama 3 или Mistral через Ollama позволяют обрабатывать документы внутри вашего контура.
Синтетические данные не исказят аналитику и обучение моделей?
Если правильно задать параметры генерации, синтетические пользователи сохраняют структуру и распределения реальных данных, но не связаны с живыми людьми. Gartner прогнозирует рост их использования до 60% всех данных для разработки ИИ к 2025 году именно по этой причине.
Как бороться с Shadow AI у сотрудников?
Одного запрета мало. Нужен официальный, одобренный канал: корпоративный доступ к Azure OpenAI или другому провайдеру с нужными гарантиями, плюс понятные правила, что можно и нельзя грузить в модели.
AI-profiling без cookies не ухудшит маркетинг?
AI-подходы позволяют таргетироваться по контексту сессии, а не по многолетней истории пользователя. Это снижает зависимость от персональных данных и лучше стыкуется с трендом на этичный таргетинг.
Где почитать про риски и уязвимости ИИ-систем?
Посмотрите OWASP Top 10 for LLM, отчеты Gartner по AI и Data Privacy, а также Cisco Data Privacy Benchmark Study. Это хорошая база, чтобы согласовать ваши решения с безопасниками.
Как вы сейчас защищаете данные клиентов при работе с ИИ и автоматизацией — есть понятная схема или набор костылей? Напишите, что болит, и подпишитесь, чтобы не пропустить разборы рабочих кейсов по Make.com и AI-приватности.
#приватность, #ai, #make