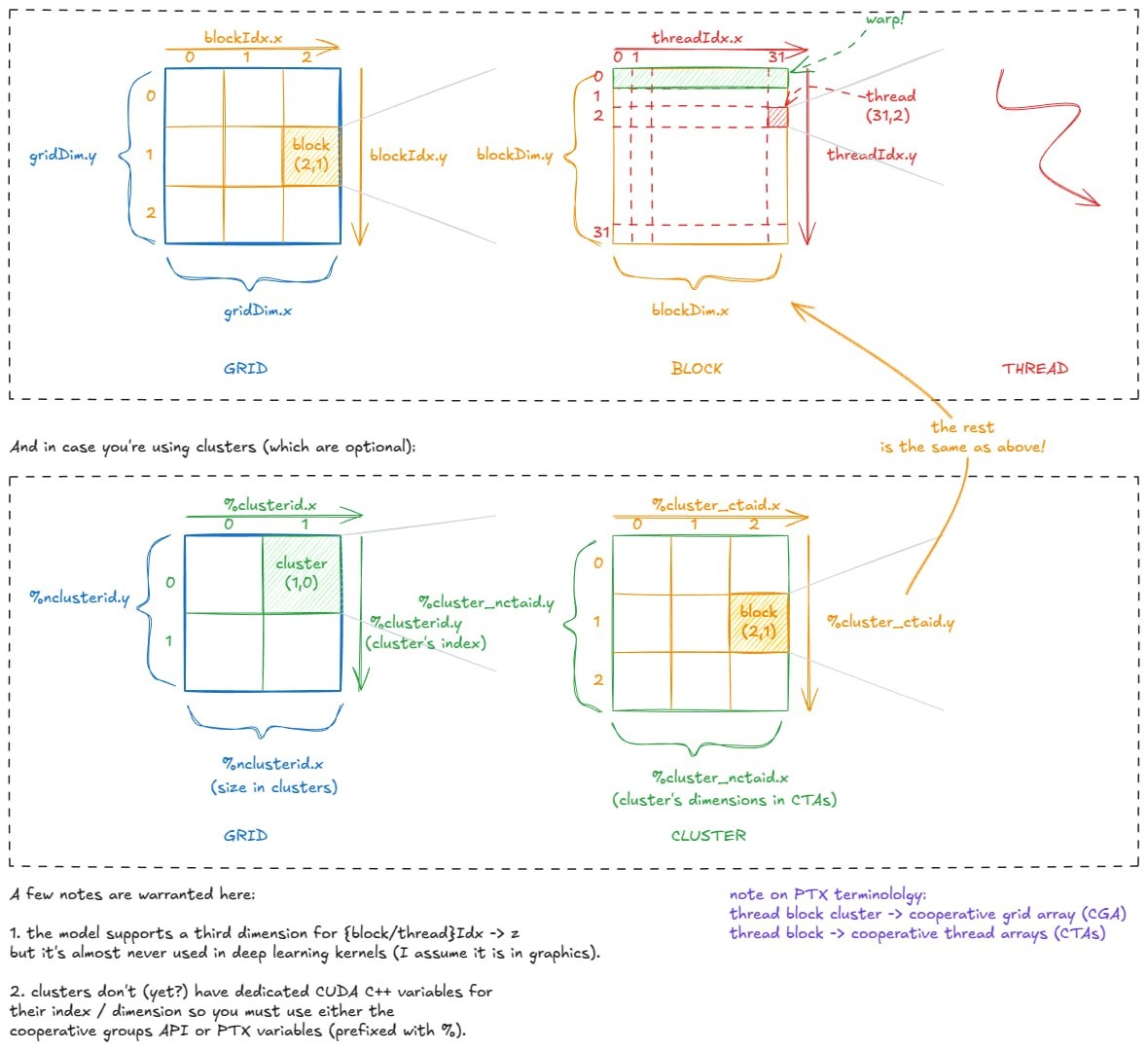
Внутри GPU NVidia: анатомия высокопроизоводительных математических умножений
Нашёл отличный материал по внутреннему устройству ядер матричного умножения на GPU — от железа до кода, бьющего производительность стандартных библиотек.
Автор проходит полный путь: архитектура памяти H100 → ассемблер GPU (PTX/SASS) → наивное ядро → оптимизированное ядро с тензорными блоками. Всё с картинками и кодом.
Ключевые полезные идеи:
Почему порядок обращения к памяти решает
Перестановка двух операторов (деление и остаток) в вычислении координат потока даёт падение производительности в 13 раз — с 3171 до 243 миллиардов операций в секунду. Без понимания иерархии памяти это выглядит как магия.
Перемешивание данных в общей памяти (swizzling)
Простая операция «исключающее ИЛИ» над адресами при загрузке данных устраняет конфликты банков памяти. Без этого — 8-кратное замедление при чтении столбцов. Автор разложил механизм до уровня отдельных битов.
Конвейер «производитель-потребитель» на уровне групп потоков
Одна группа из 128 потоков занимается только загрузкой данных через аппаратный ускоритель передачи (TMA), другая — только вычислениями на тензорных блоках. Координация через кольцевой буфер с барьерами в общей памяти. Это даёт перекрытие загрузки и вычислений.
Путь от 32 до 764 триллионов операций в секунду
Каждый шаг оптимизации с цифрами: тензорные блоки (+10×), увеличение размера плитки (+1.4×), конвейеризация (+1.2×), устойчивые ядра, кривая Гильберта для обхода плиток, кластеры блоков для обмена данными между процессорами. Итог — 107% от производительности стандартной библиотеки NVIDIA.
Кривая Гильберта для планирования вычислений
Вместо построчного обхода плиток выходной матрицы — обход по пространственно-заполняющей кривой. Соседние по времени плитки оказываются соседними в памяти → лучшее попадание в кэш второго уровня.
Материал закрывает разрыв между «знаю что такое GPU» и «понимаю как устроены ядра уровня продакшена». Автор обещает продолжение по архитектуре Blackwell и многочиповым ядрам.
#GPU #CUDA #обучение #H100 #NVidia
———