Я последнее время много общаюсь с разными ИИ моделями -пишу программы. И обнаружил - что-то с ними не то: с утра умная, после обеда тупеет, вечером вообще никакого толку от нее.

Работаете с ChatGPT или Claude уже час, а ответы становятся всё более странными? Модель повторяется, забывает контекст и путает факты? Скорее всего, вы столкнулись с переполнением контекстного окна. Разбираемся, как это отследить и что делать.
## Что такое контекстное окно и почему оно «заканчивается»
Каждая языковая модель работает с ограниченным объёмом информации одновременно. Это и есть контекстное окно — своеобразная «оперативная память» ИИ. Когда вы ведёте длинный диалог, добавляете файлы или просите проанализировать большой текст, это окно постепенно заполняется.
Как только лимит превышен, модель начинает «забывать» то, что было в начале разговора. Она не тупеет в буквальном смысле — просто физически не видит ранние сообщения. Отсюда повторы, потеря контекста и ощущение, что ИИ вас не понимает.
## Размеры окна у популярных моделей
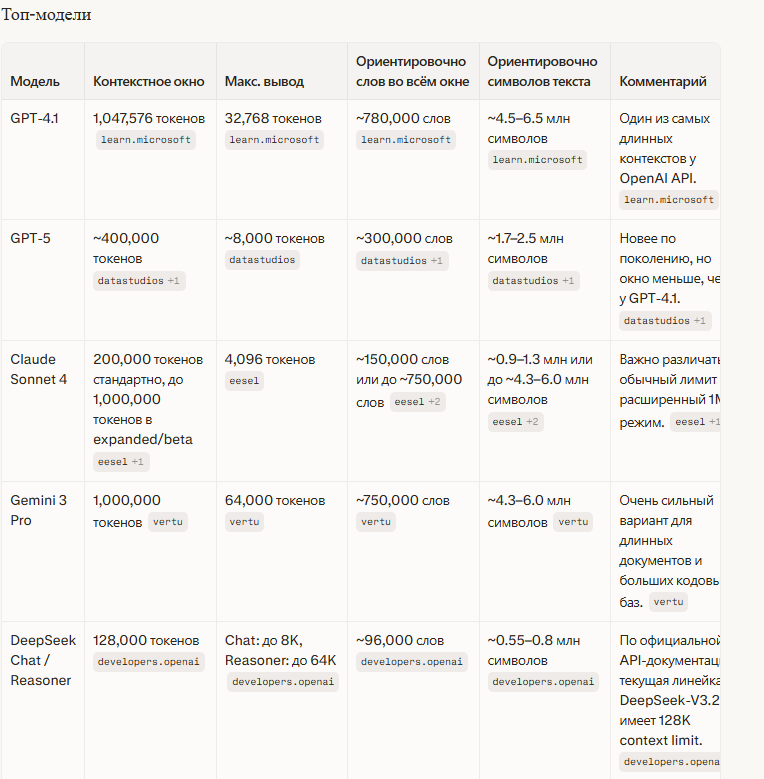
У разных нейросетей лимиты существенно отличаются:
GPT-4 (ChatGPT) — от 8 000 до 128 000 токенов в зависимости от версии. Стандартная версия обычно работает с меньшим окном.
Claude (Anthropic) — до 200 000 токенов. Одно из самых больших окон на рынке, позволяет загружать целые книги.
DeepSeek — около 64 000 токенов в базовой версии, в расширенных вариантах больше.
Gemini (Google) — до 1 000 000 токенов в версии 1.5 Pro, но на практике эффективность падает раньше.
## Токены — не символы: как считать правильно
Контекст измеряется в токенах, а не в символах или словах. Для русского языка действует приблизительное правило: один токен ≈ 3 символа. То есть сообщение в 3000 символов займёт примерно 1000 токенов. Есть еще одна особенность - цены указаны для англицского, он требует меньше токенов чем русский, так что для нас пользование моделями еще и дороже:
Точное количество токенов можно узнать через API, но не все модели предоставляют эту информацию в чат-интерфейсе. Хорошая новость — точность до токена вам и не нужна. Достаточно понимать порядок цифр.
Если вы написали 50 сообщений по 500 символов каждое, это уже около 8 000 токенов только ваших реплик. Добавьте ответы модели (они обычно длиннее) — и вы легко съели 30-40 тысяч токенов.
## Признаки того, что окно переполнено
Модель не скажет вам прямо: «Извините, я забыла начало разговора». Но есть косвенные признаки:
- ИИ переспрашивает то, что вы уже объясняли
- Ответы противоречат ранним договорённостям
- Модель «забывает» ваше имя или роль, которую вы ей задали
- Качество ответов заметно падает
- Появляются повторы и общие фразы вместо конкретики
## Лайфхак: пусть модель сама следит за контекстом
Простой трюк — добавить в системный промпт инструкцию для самоконтроля. Попросите модель в конце каждого ответа выводить приблизительную оценку использованного контекста.
Пример инструкции:
*«В конце каждого ответа добавляй строку: [Символов в запросе: ~X | Токенов ≈ X/3 | Использовано контекста ≈ X / 128000]»*
Модель будет приблизительно оценивать объём входящих сообщений и показывать, насколько заполнено окно. Это не идеально точно, но даёт ориентир. Когда видите, что использовано больше 70-80% — время начинать новый чат или делать резюме важных моментов.
## Что делать, когда окно заканчивается
Не пытайтесь продолжать разговор в надежде, что «как-нибудь получится». Лучшие стратегии:
- Начните новый диалог, кратко пересказав ключевые договорённости
- Сохраните важные промежуточные результаты отдельно
- Используйте модели с большим окном для объёмных задач
---
Вывод: Контекстное окно — это не баг, а особенность работы любой языковой модели. Зная лимиты и отслеживая заполнение, вы сэкономите время и нервы. А вы замечали, как ИИ «тупеет» в длинных диалогах?
---
Если Вам понравилась моя статья, подпишитесь на канал, пожалуйста,
Я стараюсь писать интересно и на актуальные темы.
Ваша оценка очень поможет мне.
Руслан Капетинг
[Символов в запросе: ~1800 | Токенов ≈ 600 | Использовано контекста ≈ 4800 / 200000]