Внутри каждой языковой модели есть что-то вроде блокнота для заметок. Он называется KV-кэш: туда записываются промежуточные вычисления, чтобы модель не пересчитывала одно и то же заново. Чем длиннее контекст разговора, тем толще этот блокнот, и тем дороже память на серверах. И именно здесь давно существует узкое место, которое тормозит и удорожает работу ИИ в промышленных масштабах.
Google Research предложила три взаимосвязанных алгоритма, которые атакуют эту проблему с разных сторон. Главный из них — TurboQuant, который будет представлен на конференции ICLR 2026.
Суть метода заключается в том, что данные в кэше хранятся в виде числовых векторов, длинных списков чисел с дробной точностью. Стандартные методы квантования заменяют точные числа грубыми приближениями, но тогда теряется точность. Плюс почти все существующие подходы вынуждены хранить дополнительные «поправочные коэффициенты» — это съедает лишний бит-полтора на каждое число и частично обнуляет выигрыш от сжатия.
TurboQuant обходит эту ловушку через два шага. Сначала он случайным образом «поворачивает» вектор в математическом пространстве — это делает распределение чисел более равномерным и предсказуемым. Дальше в дело вступает алгоритм PolarQuant: вместо привычных декартовых координат он переводит каждую пару чисел в полярные — радиус и угол. Например, если бы люди вместо «три шага на восток и четыре на север» говорили «пять шагов под углом 37 градусов». Угловая сетка фиксирована, границы известны заранее, и никакой дополнительной нормировки не нужно. Накладные расходы на хранение метаданных исчезают.
Затем подключается алгоритм QJL. Он берет крохотную остаточную ошибку после первого шага и «схлопывает» ее до одного знакового бита: плюс или минус. Математически это работает через преобразование Джонсона-Линденштрауса — метод, который умеет сохранять расстояния между точками даже при радикальном уменьшении размерности. Один бит на коррекцию, и систематическое смещение в вычислениях исчезает без лишней памяти.
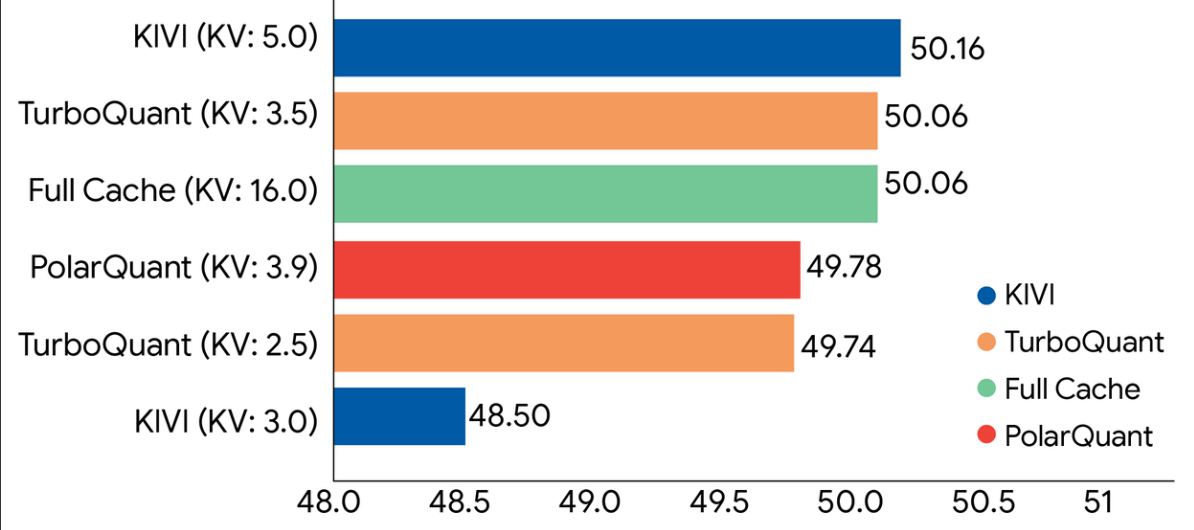
В итоге TurboQuant сжимает KV-кэш до 3 бит на число против стандартных 16-32. Память под кэш сокращается минимум в 6 раз. На GPU-ускорителях H100 скорость вычисления весовых коэффициентов внимания выросла до 8 раз по сравнению с базовой 32-битной точностью. При этом алгоритм не требует дообучения модели, и его можно применить к уже готовой нейросети.
Тесты на открытых моделях Gemma и Mistral подтвердили: на бенчмарках LongBench, Needle In A Haystack и ZeroSCROLLS результаты остаются на уровне несжатых моделей. Задача «найти иголку в стоге сена», когда модель должна найти единственный факт в огромном тексте, решается без потерь.
Помимо языковых моделей, технология напрямую влияет на векторный поиск — основу современных поисковых систем и рекомендательных алгоритмов. На наборе данных GloVe TurboQuant превзошел конкурирующие методы PQ и RaBitQ по точности поиска при меньшем объеме индекса.
Также на днях стало известно, что стартап Luma представил умный генератор картинок Uni-1. Подробности в статье.