В конце 2025 года исследовательская команда Yann LeCun представила VL-JEPA — Vision-Language Joint Embedding Predictive Architecture. Это принципиально новая модель, которая не генерирует текст токен за токеном, как привычные LLM, а предсказывает абстрактные смысловые представления (эмбеддинги). Подход основан на Joint Embedding Predictive Architecture (JEPA) и позволяет машине лучше понимать физический мир, видео и язык одновременно. VL-JEPA уже показывает результаты, превосходящие крупные мультимодальные модели при меньшем числе параметров. Модель открытая, код доступен для исследователей.
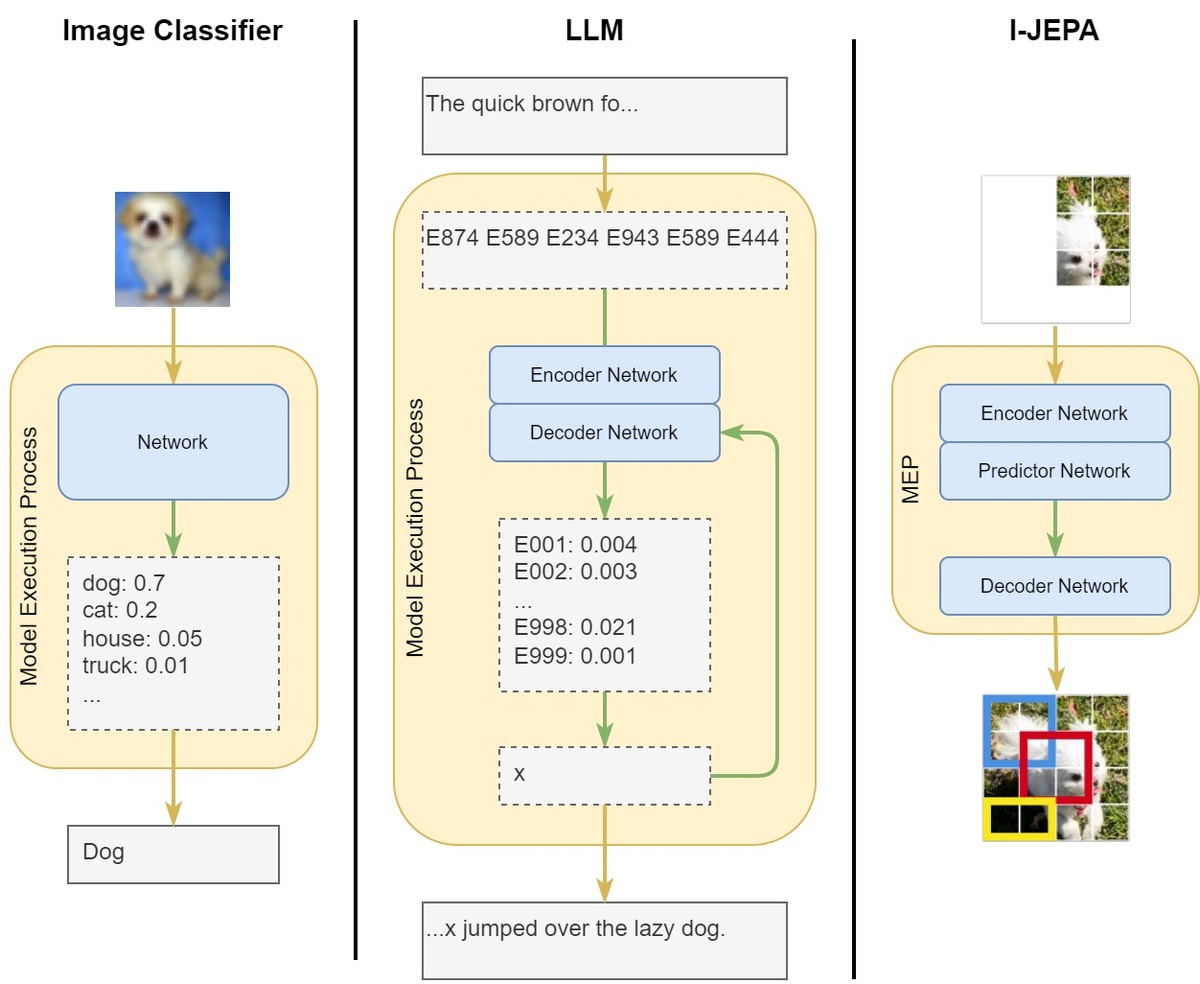
Как устроена VL-JEPA
В отличие от autoregressive моделей, которые пытаются предсказать следующее слово, VL-JEPA работает в пространстве непрерывных эмбеддингов. Модель учится предсказывать «мысленные векторы» — абстрактные представления того, что происходит на видео или в тексте. Это позволяет ей лучше моделировать причинно-следственные связи и физическую реальность. Архитектура включает:
• Энкодер видео и текста, который создаёт совместные эмбеддинги.
• Предиктор, который по частичной информации восстанавливает полное смысловое представление.
• Декодер (вызывается только при необходимости), который переводит эмбеддинги обратно в текст или действия.
Благодаря этому VL-JEPA эффективнее работает с потоковым видео в реальном времени и требует меньше вычислительных ресурсов.
Технические преимущества 2026 года
VL-JEPA демонстрирует значительный прирост эффективности:
• На задачах world modeling и action anticipation она обходит модели с в 10–50 раз большим числом параметров.
Применение VL-JEPA на практике
Модель уже тестируется в:
• Робототехнике (управление роботами в неизвестной среде).
• Анализе видео в реальном времени (безопасность, медицина, спорт).
• Мультимодальных системах, где нужно понимать и видео, и речь одновременно.
• Научных исследованиях физического мира и причинно-следственных связей.
VL-JEPA — шаг к более «человеческому» ИИ, который понимает мир, а не просто повторяет паттерны из данных.
• Поддерживает zero-shot перенос на новые задачи без дообучения.
• Хорошо справляется с длинными видео, где важна временная связность.
• Эффективна для робототехники: модель может планировать действия, предсказывая будущие состояния мира.
Исследователи подчёркивают, что такой подход ближе к тому, как учится человек: мы не запоминаем каждый пиксель, а понимаем смысл происходящего.
Плюсы для исследователей и разработчиков
• Открытый код и веса — можно изучать и дорабатывать.
• Высокая эффективность: меньше параметров — меньше энергозатрат.
• Лучшая обобщаемость на новые сценарии.
• Фокус на понимании, а не на генерации — меньше галлюцинаций.
Минусы и ограничения
• Пока меньше внимания к генеративным задачам (создание видео или текста «с нуля»).
• Требует качественных данных для обучения.
• Полный потенциал раскрывается в комбинации с другими моделями.
Вердикт
VL-JEPA — это важный шаг в развитии self-supervised learning. Вместо того чтобы заставлять ИИ генерировать токены, модель учится понимать смысл на абстрактном уровне. Это делает её эффективнее и ближе к человеческому мышлению. В 2026 году такие архитектуры могут стать основой для роботов, умных систем анализа видео и более безопасного ИИ. Если вы занимаетесь исследованиями или разработкой — VL-JEPA стоит изучить. Технология открытая и ориентирована на будущее.
Пишите в комментариях: как думаете, такие модели заменят привычные LLM?
Подписывайся на «Иишка для тебя» — каждый день свежие новости про ИИ и гаджеты 2026.
#VLJEPA #JEPA #ИИ2026 #Самообучение #WorldModeling #ИИАрхитектура #YannLeCun #Техника2026 #ВидеоИИ #МультимодальныйИИ