
Современные нейросети для генерации музыки и вокала работают на основе больших языковых и аудиомоделей, обученных на миллионах часов записей. Они не хранят библиотеку готовых голосов, а синтезируют их «на лету» каждый раз заново. Это открывает огромные возможности для творчества, но одновременно порождает вопросы: можно ли получить бесконечное разнообразие голосов? Есть ли у этого процесса предел?
Как нейросети создают голоса
Модели генерации вокала используют глубокое обучение на огромных массивах данных — записях песен, речи, вокальных партий в различных жанрах. На основе этого обучения сеть учится понимать:
- какие голоса характерны для рока, поп-музыки, джаза или рэпа;
- как эмоция (радость, грусть, гнев) влияет на тембр и интонацию;
- как текст и его ритмика соотносятся с вокальной подачей.
При каждой генерации нейросеть создает голос с нуля, комбинируя усвоенные паттерны. Теоретически это позволяет получать уникальный вокал в каждом новом треке. Однако на практике разнообразие ограничивается рядом факторов.
Что влияет на разнообразие голосов
1. Внутренние «архетипы» модели
Модель усваивает типичные для каждого жанра вокальные характеристики. Например, для рока это часто мощные, хриплые голоса; для поп-музыки — чистые, яркие; для рэпа — глубокие, ритмичные. Если пользователь долгое время работает в одном жанре с минимальными изменениями промптов, сеть начинает тяготеть к ограниченному набору «удачных» вариантов, которые она считает наиболее подходящими.
2. Зависимость от языка обучения
Большинство современных моделей обучены преимущественно на англоязычном материале. Поэтому генерация вокала на других языках может быть менее разнообразной, чем на английском. Это создает ощущение, что «все голоса похожи», особенно при работе с нетипичными для обучающей выборки языками.
3. Влияние текста и эмоциональной окраски
Эмоциональное содержание текста напрямую влияет на синтез голоса. Радостный текст чаще порождает светлые, открытые тембры, а текст о потере — надрывные, с дрожью. Однообразие тем и настроений в текстах может сужать спектр генерируемых голосов.
4. Случайные факторы (сиды)
Большинство нейросетей используют случайное начальное число (seed) для инициализации генерации. При одинаковых параметрах и одном seed результат будет идентичным или очень похожим. При смене seed (автоматической или ручной) разнообразие значительно возрастает.
Существует ли практический предел?
Для обычного пользователя
При умеренном использовании (сотни треков) предел разнообразия голосов практически недостижим. Достаточно менять жанры, добавлять детальные описания тембра, экспериментировать с эмоциональной окраской текста и случайными факторами, чтобы получать новые вариации вокала в каждом треке.
Для очень активного пользователя
При генерации тысяч треков в одном узком стиле может возникнуть ощущение повторяемости. Это связано с тем, что модель возвращается к наиболее вероятным, статистически «безопасным» вариантам, которые она считает оптимальными для заданных параметров. Однако даже в этом случае разнообразие можно расширить, если целенаправленно варьировать входные данные.
Как увеличить разнообразие голосов
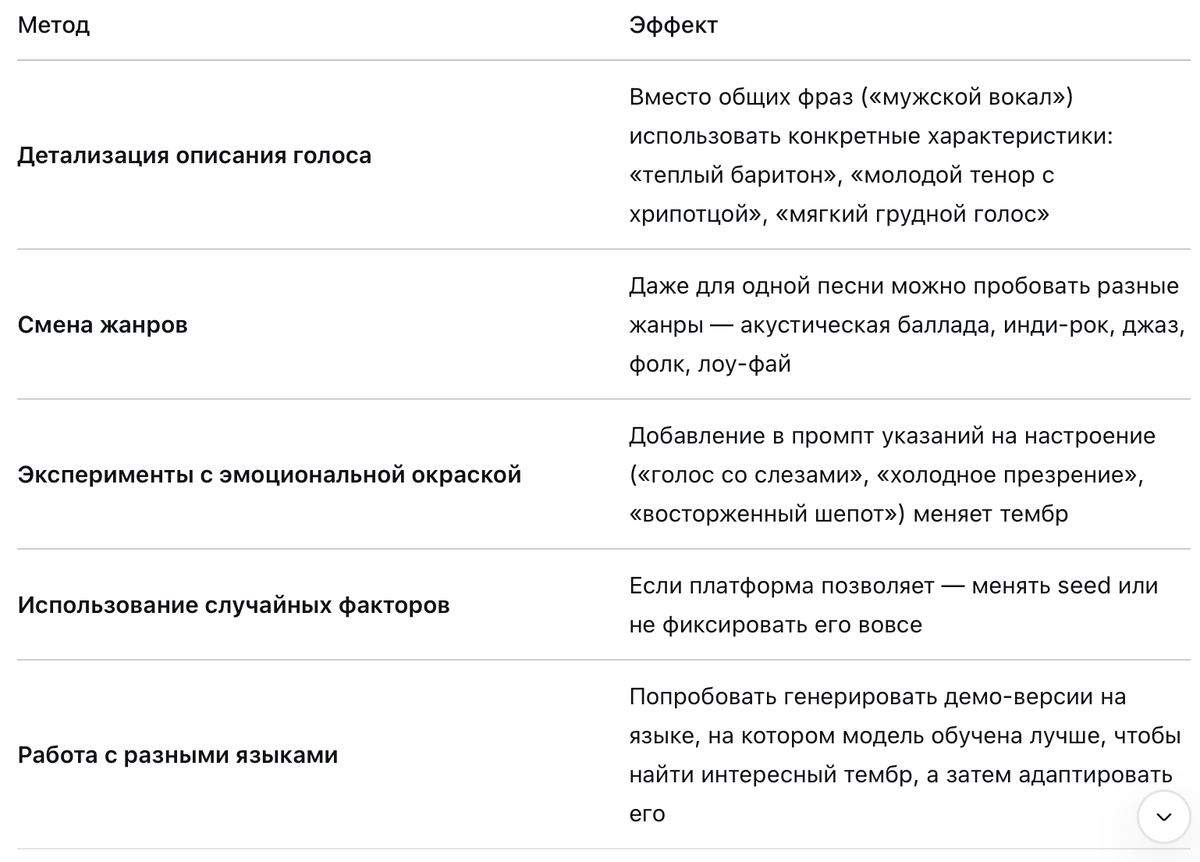
Чего нельзя сделать (ограничения технологий)
Заключение
Современные нейросети генерации вокала способны создавать практически неисчерпаемое разнообразие голосов. Предел существует скорее как теоретический — он ограничен внутренними архетипами модели и статистическими вероятностями. На практике же большинство пользователей никогда не сталкиваются с «исчерпанием» вариантов, особенно если они активно экспериментируют с параметрами, жанрами и детальными описаниями желаемого тембра.
Главный ключ к разнообразию — вариативность входных данных. Чем больше деталей, неожиданных сочетаний жанров и эмоциональных оттенков получает модель, тем более уникальный и неповторимый голос она сможет создать в каждом новом треке.