30+ движков за две недели, реальные замеры на Apple M4, и почему ElevenLabs за $5.57/час - это приговор для бизнеса
AI Voice AI TTS STT Text-to-Speech Speech-to-Text ElevenLabs Deepgram OpenAIGroq Kokoro Cartesia Google Meet Real-time перевод Голосовой бот БенчмаркApple Silicon LLM Личный опыт
Сижу на очередном рабочем созвоне. Обсуждаем архитектуру нового сервиса. Технически я всё понимаю - документацию на английском читаю без словаря, код ревьюю, в слаке переписываюсь нормально. А вот когда надо открыть рот и сказать что-то сложнее "I agree" - начинается цирк. Пауза. Подбираю слова. Коллега уже ответил за меня.
Знакомо?
Я CTO, серийный предприниматель, последние годы плотно работаю с AI-интеграциями. И вот парадокс: могу собрать систему автоматического обзвона клиентов с клонированием голосов, а сам на созвоне звучу как иностранец с разговорником.
Решил наконец закрыть этот гештальт. Полез искать real-time переводчик. Что-то типа: я говорю по-русски, собеседник слышит английский. И наоборот. В реальном времени, без пауз на 10 секунд.
И тут началось интересное.
Существующие решения - от $25 до $300+ в месяц
Я прошёлся по всему рынку. Вот что есть:
Google Meet S2ST в феврале 2026 запустил перевод речи. Звучит круто на бумаге - задержка ~2 секунды, сохраняет голос говорящего. На практике: работает только в Google Meet (в Zoom, Teams, Discord - нет), только в платной версии Workspace, ограниченная география, API нет.
Palabra.ai - 800ms задержка, есть WebSocket API. Бесплатно 30 минут в месяц, дальше от $25/мес за 60 минут. При активном использовании легко улетаешь за $100+. DeepL Voice - 1-2 секунды, $32.99/мес, в отзывах жалобы на лаги. Interprefy и Wordly - enterprise от $300-500+, заточены под конференции на 1000 человек, а не под двух людей на созвоне.
Протестировал всё что мог потрогать. Ни одно не работало так чтобы разговор звучал естественно. Где-то задержка два с лишним секунды - это уже не перевод, это рация. Где-то привязка к одной платформе. Где-то ценник для корпораций.
Ну и мы же айтишники. Да ещё и AI интегрировать умеем. Собрал рабочий прототип за выходные, а за следующие пару недель прогнал через бенчмарки весь рынок голосовых движков. Результаты - ниже.
Как устроен голосовой AI-переводчик
Схема простая. Три компонента в цепочке:
STT (распознавание речи) → LLM (перевод) → TTS (синтез голоса)
Я говорю по-русски. Deepgram распознаёт речь. Groq с Llama переводит. TTS озвучивает. Собеседник слышит английский. В обратную сторону то же самое.
Звучит просто. На деле каждый компонент - это бутылочное горлышко, и в каждом свои грабли. Разберём по частям.
Часть 1: STT - кто слушает лучше всех
Speech-to-Text - первое звено цепочки. Чем быстрее распознали речь, тем раньше начнётся перевод.
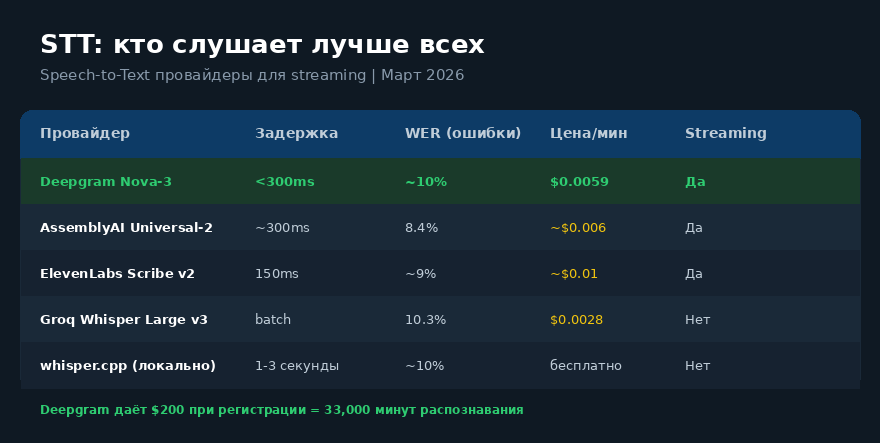
Deepgram Nova-3 - лучший для streaming. Работает стабильно, задержка меньше 300ms, цена копеечная.
Кстати, при регистрации Deepgram даёт $200 на счёт. При расходе $0.0059/минута этого хватает на 33,000 минут распознавания. Это 560 часов. Реферальной программы у них нет, а то бы дал ссылку и жил на пассивном доходе.
Groq Whisper мы пробовали раньше - нестабильный, падал с 503 ошибками, средняя задержка 2812ms. Заменили на Deepgram и забыли как страшный сон.
Часть 2: LLM - кто переводит быстрее
Для перевода нужна LLM, которая выдаёт первый токен максимально быстро (TTFT - Time to First Token). Качество перевода у всех крупных моделей плюс-минус одинаковое, а вот скорость отличается в разы.
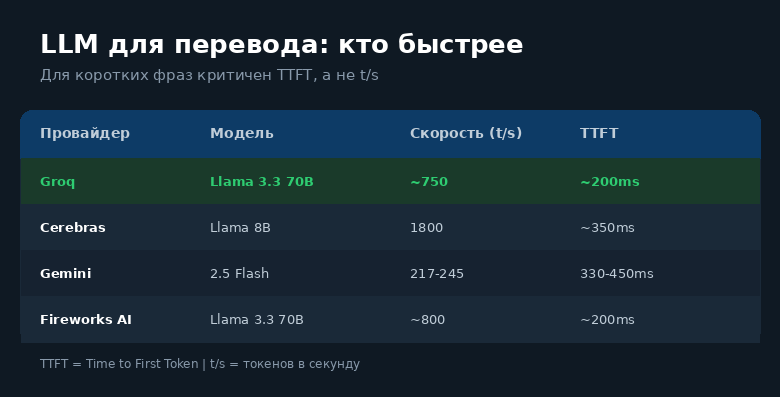
Cerebras быстрее по токенам/секунду, но у них выше TTFT. Для перевода коротких фраз (5-15 слов) критичен именно TTFT, а не скорость генерации. Groq с Llama 3.3 70B - оптимальный выбор: ~200ms до первого токена, хорошее качество перевода.
Часть 3: TTS - где всё ломается
Text-to-Speech выглядит как самая простая часть пайплайна. На деле это бутылочное горлышко всей системы. Если STT + LLM работают за 500ms, а TTS добавляет ещё секунду - собеседник ждёт полторы секунды после каждой фразы.
Я начал с Piper TTS. Бесплатный, опенсорсный, работает локально. Инференс на коротких фразах - 30-50ms. Быстрее не бывает. Но пользователи говорили одно и то же: "тихо и плохо". Голос звучит как робот из 2015 года.
Полез разбираться. Оказалось, проблема "тихо" - это баг в коде. Семплы из ONNX-модели идут без нормализации громкости. А "плохо" - ну, это архитектура VITS 2019 года. Плюс проект Piper архивировали в октябре 2025.
Начал искать замену. За пару недель прогнал через бенчмарки 30+ движков. Вот полная картина.
Облачные TTS API
Рейтинг качества TTS (ELO, слепое голосование)
Данные из TTS Arena v2 и Artificial Analysis, март 2026:
Локальные TTS модели (реальные бенчмарки на Apple M4)
Все тесты - MacBook Air M4, 24GB RAM. Одни и те же фразы, warm (после прогрева).
Тренд неприятный: все серьёзные новые модели (Chatterbox, Dia, Sesame CSM, Spark-TTS) идут к 0.5-2B параметров. На Mac без GPU это 6-19 секунд на фразу. Лёгких конкурентов Kokoro 82M почти нет.
Реальные бенчмарки: одни и те же фразы, все провайдеры
5 одинаковых фраз, warm, замеры TTFB или total time. Это самая ценная таблица в статье:
Обратите внимание на Cartesia в двух строках. Одна и та же модель, одна и та же фраза. Разница - только протокол подключения.
Четыре находки, которые стоили мне недели
Находка #1: Протокол решает всё
Cartesia Sonic через WebSocket: 245ms.
Cartesia Sonic через обычный HTTP SDK: 1361ms.
Разница в 5.5 раз. Просто потому что в одном случае соединение уже открыто и данные идут стримом, а в другом каждый запрос открывает новое соединение и ждёт полной генерации.
Если выбираете TTS для голосового бота и тестируете через синхронный API - вы получаете цифры, которые не имеют отношения к реальности. Всегда тестируйте через WebSocket.
Находка #2: Квантизация замедляет на Apple Silicon
Обычно INT8-квантизация ускоряет инференс. На Apple Silicon - наоборот.
Kokoro 82M в fp16: 373ms. Та же модель в INT8: 687ms. Почти вдвое медленнее.
ARM-процессоры Apple оптимизированы под fp16. Квантизация экономит RAM, но добавляет overhead на конвертацию типов. Нигде в документации это не написано. Мы убили на это день.
Находка #3: Русский язык - пустыня
Kokoro 82M - лучшая бесплатная модель по качеству (первое место в TTS Arena) - русского не поддерживает. Если делаете голосовой продукт для русскоязычного рынка на open-source - готовьтесь к боли. Или платите облаку.
Находка #4: ElevenLabs - лучшее качество, худшая экономика
ElevenLabs Flash v2.5 - объективно один из лучших движков. ELO 1544, голоса неотличимы от живых.
Цена: ~$206/1M символов. Для голосового бота на час - $5.57.
Cartesia Sonic Turbo при сопоставимой скорости: $1.26/час. Hume Octave 2: $0.26/час.
ElevenLabs в 4-20 раз дороже конкурентов при сравнимом качестве. Считайте unit-экономику до того как выберете провайдера. Не после.
Kokoro 82M: бесплатный чемпион (с нюансами)
Отдельно про модель которую я в итоге выбрал для английского TTS. Kokoro 82M - StyleTTS2, Apache 2.0 лицензия, 156MB в fp16.
28 английских голосов (20 US, 8 GB). Качество - первое место в TTS Arena для single-speaker. Субъективно значительно натуральнее Piper.
Минус: нет русского. 9 языков (EN, JA, ZH, ES, FR, HI, IT, PT, GB-EN), но не русский.
Что получилось в итоге
Финальный стек переводчика:
Deepgram Nova-3 (STT, ~300ms) → Groq Llama 3.3 70B (перевод, ~200ms) → StreamChunker (нарезает на куски по 2-3 слова, ~100ms) → Kokoro 82M (TTS английский, ~370ms на первый чанк)
Общая задержка до первого звука: ~870ms.
На уровне лучших коммерческих решений. Скоро выложу в open-source.
Для русского TTS пока Piper с фиксом нормализации громкости. Проблема "тихо" оказалась багом - семплы из ONNX шли без gain normalization. Починили, стало нормально.
Бонус: тот же стек для колл-центра
Пока копался в TTS-движках, тот же пайплайн пригодился для другого проекта. У RigCrewесть колл-центр - автоматический обзвон кандидатов, скриптованные разговоры, FAQ на 30 вопросов. Живые операторы стоят денег и масштабироваться с ними дорого.
Адаптировали пайплайн: STT слушает кандидата, LLM генерирует ответ по скрипту, TTS озвучивает. Один менеджер управляет целым оркестром из AI-звонилок. Голосовой бот который звучит натурально, стоит $1-2 в час, и не устаёт к концу смены.
Все бенчмарки из этой статьи - они работают и там. Тот же выбор между Cartesia за $1.26/час и ElevenLabs за $5.57/час. Та же разница в 5.5 раз между WebSocket и sync API.
Куда движется голосовой AI
Conversational Speech Models. Sesame CSM-1B генерирует речь с паузами, "ммм", контекстной интонацией. Пока research-grade (200-400ms, нужен GPU), но через год-два это будет стандарт.
LLM-based TTS. Hume Octave 2, OpenAI gpt-4o-mini-tts - модели которые "понимают" что говорят. Грустную новость бот сообщает грустным голосом. Hume побеждал ElevenLabs в слепом тесте (71.6% по quality).
Гонка цен вниз. Новые игроки (Inworld, Smallest.ai, Fish Audio) давят ElevenLabs. Цены за два года упали в 5-20 раз.
Open-source догоняет. Kokoro 82M бесплатно даёт качество облачных API годовой давности. Но русский язык - по-прежнему боль.
End-to-end модели. Google S2ST переводит речь напрямую, сохраняя голос. Пока только в Meet. Если откроют API - рынок изменится.
Три вещи которые я хотел бы знать до начала
Считайте unit-экономику на берегу. Разница между $0.26/час и $5.57/час при 1000 часов звонков в месяц - это $5,310. Выбор TTS-провайдера может убить бизнес-модель.
Тестируйте через WebSocket. Один и тот же провайдер: 245ms или 1361ms. Зависит только от протокола.
Русский язык - бутылочное горлышко. Open-source пока не дотягивает. Бюджет на cloud TTS неизбежен если ваш продукт для русскоязычного рынка.
Переводчик скоро в open-source. Все бенчмарки из статьи реальные, повторяемые, с указанием железа и условий. Если делаете что-то похожее - пишите, сэкономлю вам пару недель мучений.
Где меня найти:
Telegram: @ai_integr - кейсы, инструменты, фейлы AI-интеграций
Источники и бенчмарки:
TTS Arena v2 · Artificial Analysis · Cartesia · Hume Octave 2 · Deepgram Nova-3 · Kokoro-82M · Sesame CSM · Google Meet S2ST · Cerebras vs Groq · ElevenLabs Scribe v2 · Inworld TTS · Piper TTS · Kokoro ONNX · Palabra.ai· Interprefy