
Новая речевая модель Mistral может работать на смарт-часах или смартфоне. — techcrunch.com
Новая модель, получившая название Voxtral TTS, поддерживает девять языков, включая английский, французский, немецкий, испанский, голландский, португальский, итальянский, хинди и арабский.
«Наши клиенты просили о речевой модели. Поэтому мы создали компактную речевую модель, которая может работать на смарт-часах, смартфоне, ноутбуке или других граничных устройствах. Ее стоимость составляет лишь малую долю от предложений конкурентов на рынке, но при этом она обеспечивает передовую производительность», — сообщил Пьер Сток, вице-президент по научным операциям в Mistral AI, в телефонном интервью TechCrunch.
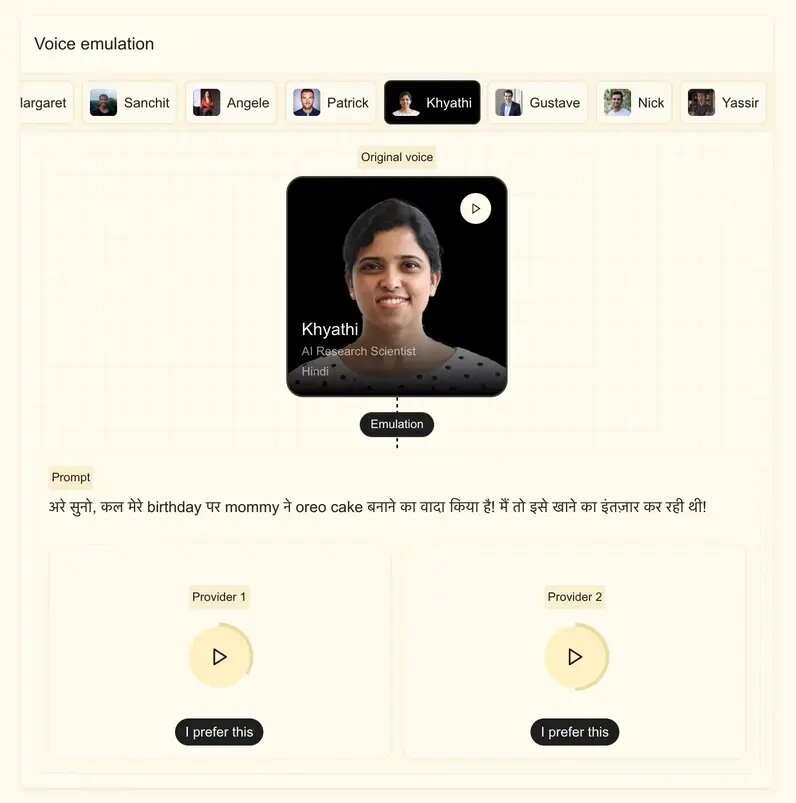
В Mistral заявили, что новая модель может адаптировать пользовательский голос по образцу продолжительностью менее пяти секунд, а также улавливать такие характеристики, как тонкие акценты, интонации, модуляции и нерегулярности в потоке речи. Модель, основанная на Ministral 3B, может легко переключаться между языками, не теряя характеристик голоса, что полезно для таких сценариев использования, как дублирование или перевод в реальном времени. Сток отметил, что компания стремилась к тому, чтобы модель звучала по-человечески, а не роботизированно.
По данным компании, модель разработана для работы в режиме реального времени. Время до первого аудиовыхода (TTFA) — показатель того, как быстро модель начинает «говорить» после получения входных данных — составляет 90 мс для 10-секундного образца из 500 символов. Модель также имеет коэффициент реального времени (RTF) 6x, что означает, что она может сгенерировать 10-секундный клип примерно за 1,6 секунды.
Ранее в этом году Mistral выпустила пару моделей транскрипции: одну для пакетной обработки больших объемов данных, а другую для сценариев реального времени с низкой задержкой. С новой речевой моделью компания, вероятно, нацелена на предоставление предприятиям полного набора голосовых продуктов.
«Мы планируем создать комплексную платформу, способную обрабатывать мультимодальные потоки входных данных, включая аудио, текст и изображения, а также выдавать соответствующий результат. Основное преимущество заключается в том, что вы получаете гораздо больше информации с помощью комплексной агентной системы, поддерживающей аудио в качестве ввода или вывода», — сказал Сток.
Позиция Mistral заключается в том, что ее открытый исходный код и возможности настройки помогут предприятиям внедрять ее голосовые модели в сравнении с конкурентами, поскольку они могут настраивать их по своему усмотрению.
Всегда имейте в виду, что редакции могут придерживаться предвзятых взглядов в освещении новостей.
Автор – Ivan Mehta